

Chapter 4. 최적화
4.1 확률적 경사 하강법
손실 함수의 곡면에서 "경사가 가장 가파른 곳으로 내려가다 보면 언젠가 가장 낮은 지점에 도달한다"는 가정으로 만들어짐
4.1.1
학습률
- 최적화할 때 한 걸음의 폭을 결정하는 스텝 크기
- 학습 속도를 결정함
- 학습률이 고정되어 있으면 최적화가 비효율적으로 진행됨
- 학습률이 낮으면 학습 속도가 느림
- 학습률이 높으면 최적해로 수렴하지 못함 or 손실이 커짐
학습률 감소
- 처음에 높은 학습률로 시작하고 학습이 진행되는 상황에 따라 학습률을 조금씩 낮추는 방식
적응적 학습률
- 학습의 진행 상황이나 곡면의 변화를 알고리즘 내에서 고려해서 학습률을 자동으로 조정하는 방식
- 곡면의 변화에 따라 학습률이 적응적으로 조정된다면 안정적으로 학습 가능
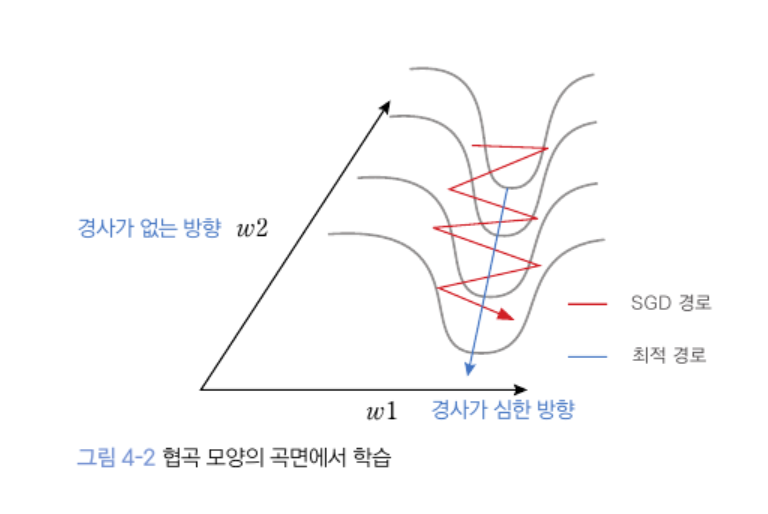
4.1.2 협곡에서 학습이 안 되는 문제
- 가로 방향으로는 경사가 매우 가파르고 세로 방향으로는 경사가 거의 없는 폭이 좁고 깊은 지형
- 확률적 경사 하강법으로는 이와 같은 지형을 안정적으로 해결 불가
- 결국, 최적해가 있는 곳에 도달하지 못하고 정체된 상태로 학습 종료
4.1.3 안정점에서 학습 종료
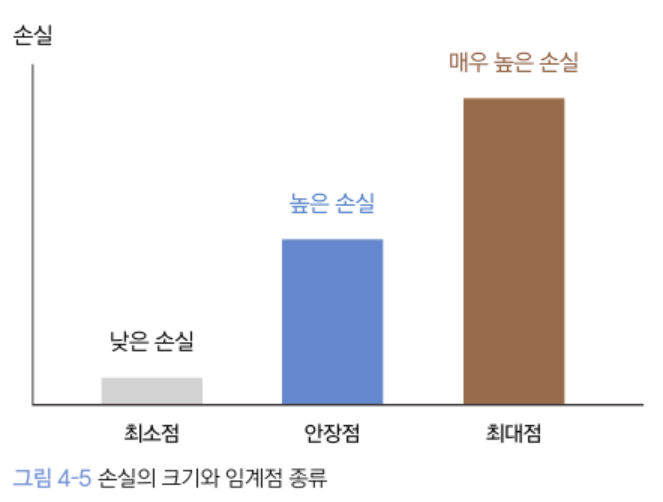
임계점: 미분값이 0인 지점 (최대점, 최소점, 안장점)
확률적 경사 하강법은 임계점을 만나면 최대점, 최소점, 안장점을 구분하지 못하고 학습을 종료
손실 함수 곡면에는 안장점 多 → 안장점을 만나더라도 학습 진행될 방법 필요
임계점 vs. 최대점/최소점/안장점
임계점에서 손실을 확인해보자!
- 손실 ↓: 최소점일 가능성 큼
- 손실 ↑: 최대점일 가능성 큼
- 손실 적당히 높음: 안장점일 가능성 큼
4.1.4 학습 경로의 진동
경사하강법: 기울기가 정확하기 때문에 최적해를 향해 곧바로 내려감
확률적 경사 하강법: 기울기가 부정확하기 때문에 여기저기 둘러서 최적해로 감
- 최적화 경로 길어짐
- 수렴 속도 느려짐
4.2 SGD 모멘텀
4.2.1 핵심 개념
SGD: 가장 가파른 곳으로 내려가는 방식
SGD 모멘텀: 지금까지 진행하던 속도에 관성이 작용하도록 만든 방식
속도에 관성이 작용하면...
- 학습 경로가 전체적으로 매끄러워짐
- 가파른 경사를 만나면 가속도가 생겨서 학습이 매우 빨라짐
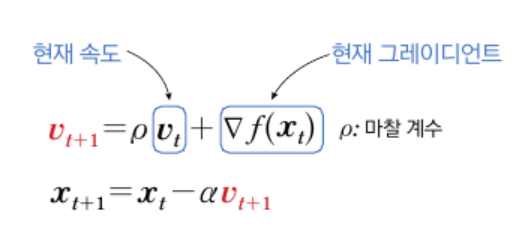
현재 속도에 마찰 계수를 곱한 뒤 그레이디언트를 더해서 계산
4.2.2 관성을 이용한 임계점 탈출과 빠른 학습
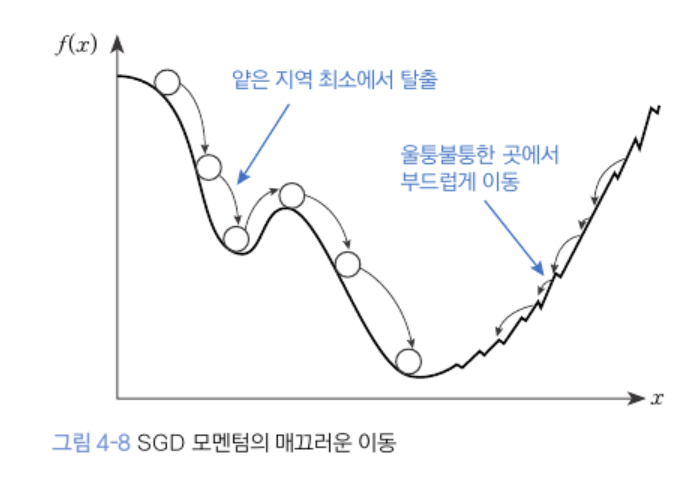
(SGD 모멘텀으로 이동하면) 관성이 생겨 진행하던 속도로 계속 진행하려 함
- 깊이가 얖은 지역 최소에서 탈출 가능
- 기울기가 막 바뀌는 곳에서도 탈출 가능
- 경사가 가파르면 가속도가 생김 (빠르게 이동)
4.2.3 오버 슈팅 문제 (SGD 모멘텀의 단점)
경사가 가파르면 빠른 속도로 내려오다가 최소 지점을 만나면 기울기는 작아지지만 속도는 여전히 크기 때문에 최소 지점을 지나치는 현상
최적해 주변을 평평하게 만들어 주는 정규화 기법을 사용하면 오버 슈팅 방지 가능★
4.3 네스테로프 모멘텀
SGD 모멘텀과 같이 속도에 관성을 줌
BUT, 오버 슈팅이 된 만큼 다시 내리막길로 내려가기 때문에 이동 방향에 차이 有
4.3.1 핵심 개념
- 관성을 이용해서 현재 속도로 한 걸음 미리 간 지점에서 내리막길로 내려가는 방식
- (오버 슈팅 방지) 한 걸음 미리 갔을 때 높이 올라간 만큼 다시 내려오도록 그레이디언트로 교정해 줌
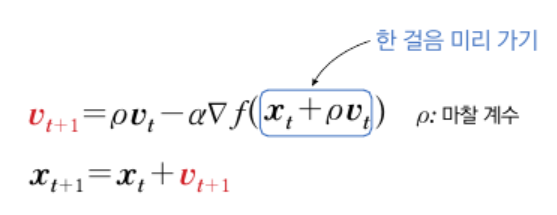
현재 속도에 마찰 계수를 곱한 뒤 현재 속도로 한 걸음 미리 가 본 위치의 그레이디언트를 빼서 계산
4.3.2 오버 슈팅 억제
아래는 네스테로프 모멘텀이 오버 슈팅을 억제하는 단계를 벡터로 표현한 그림이다.
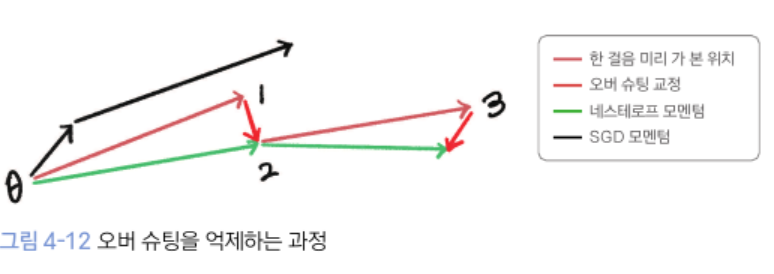
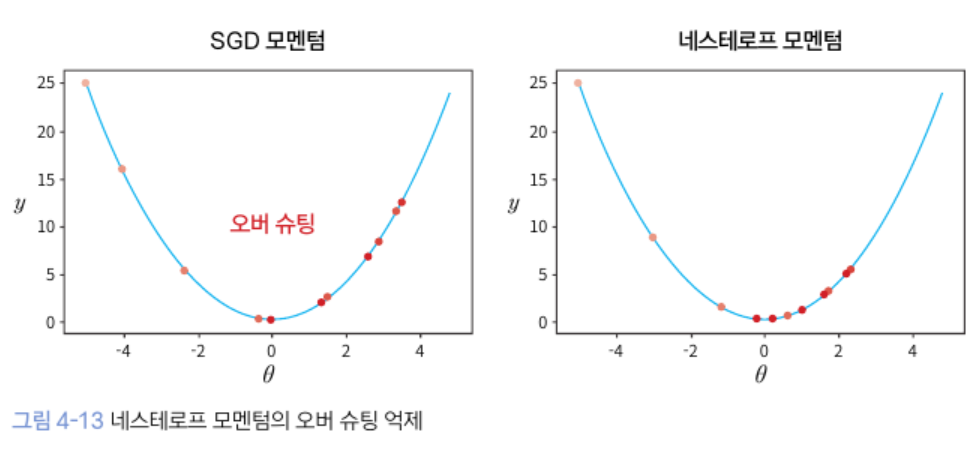
- SGD 모멘텀은 최소 지점을 지나쳐서 오버 슈팅이 됨
- 네스테로프 모멘텀은 최소 지점을 조금만 지나쳐서 오버 슈팅 억제
4.4 AdaGrad
손실 함수의 곡면의 변화에 따라 적응적으로 학습률을 정하는 알고리즘
4.4.1 핵심 개념
경사가 가파르면?
- 작은 폭으로 이동하는 것이 좋음
- 큰 폭으로 이동하면 최적화 경로를 벗어나거나 최소 지점을 지나칠 수 있음
경사가 원만하면?
- 큰 폭으로 빠르게 이동하는 것이 좋음
곡면의 변화량을 어떻게 계산할까?
- 각 기울기의 제곱합을 계산
적응적 학습률?
- 학습률/곡면의 변화량의 제곱근
- 곡면의 변화량에 반비례
- 곡면의 변화가 크면 천천히 학습
- 곡면에 변화가 작으면 빠르게 학습
4.4.2 학습 초반에 학습이 중단되는 현상
- 곡면의 변화량을 전체 경로의 기울기 벡터의 크기로 계산
- 학습이 진행될수록 곡면의 변화량은 점점 커지고 반대로 적응적 학습률은 점점 낮아짐
- ex) 경사가 매우 가파른 위치에서 학습 시작 → 초반부터 적응적 학습률이 급격히 감소하기 시작해서 조기에 학습 중단 가능
- 학습 중단 문제를 해결하기 위해 RMSProp 제안
4.5 RMSProp
최근 경로의 곡면 변화량에 따라 학습률을 적응적으로 결정하는 알고리즘
4.5.1 핵심 개념
- 곡면 변화량을 측정할 때 전체 경로가 아닌 최근 경로의 변화량을 측정하면 곡면 변화량이 누적되어 계속해서 증가하는 현상 없앰
- 최근 경로의 곡면 변화량을 측정하기 위해 지수가중이동평균 사용
4.5.2 최근 경로의 곡면 변화량
- 최근 경로의 그레이디언트는 많이 반영되고 오래된 경로의 그레이디언트는 작게 반영
- 그레이디언트 제곱에 곱해지는 가중치가 지수승으로 변화 → 지수가중평균
- 단계마다 새로운 그레이디언트 제곱의 비율을 반영하여 평균이 업데이트 → 지수가중이동평균
4.6 Adam
SGD 모멘텀과 RMSProp이 결합된 형태로, 진행하던 속도에 관성을 주고 동시에 최근 경로의 곡면의 변화량에 따라 적응적 학습률을 갖는 알고리즘
4.6.1 핵심 개념
- 관성 + 적응적 학습률의 장점
- 우수한 최적화 성능
- 잡음 데이터에 대해 민감하지 반응 X
- 학습 초기 경로가 편향되는 RMSProp 문제 제거

4.6.2 학습 초기 경로 편향 문제
WHY?

- r이 작아지면 적응적 학습률이 커져서 출발 지점에서 멀리 떨어진 곳으로 이동
- 최적화에 좋지 않은 곳으로 이동 가능
SO? 어떻게 제거할까?

- 추가된 식에 따르면 r은 그레이디언트의 제곱이므로 아주 작아질 일 X
- 학습 초반에 학습률이 급격히 커지는 편향 제거
- 훈련이 진행될수록 베타1, 베타2가 1보다 작기 때문에 베타가 포함된 분모는 1에 수렴하므로 원래 알고리즘으로 바뀜
Chapter 5. 초기화와 정규화
5.1 가중치 초기화
모델 초기화: 신경망을 학습할 때 손실 함수에서 출발 위치를 결정하는 방법
5.1.1 상수 초기화
신경망의 가중치를 0으로 초기화한다면?
가중 합산 결과는 항상 0, 활성 함수는 가중 합산 결과인 0을 입력받아서 늘 같은 값 출력
5.2 정규화
최적화 과정에서 최적해를 잘 찾도록 정보를 추가하는 기법
5.2.1 일반화 오류
일반화: 훈련 데이터가 아닌 새로운 데이터에 대해 모델이 예측을 얼마나 잘하는지
일반화 오류: 모델의 룬현 성능과 검증/테스트 성능의 차
5.3 배치 정규화
데이터가 계층을 지날 때마다 매번 정규화해서 내부 공변량 변화를 없애는 방법
5.4 가중치 감소
학습 과정에서 작은 크기의 가중치를 찾게 만드는 정규화 기법
5.5 조기 종료
모델이 과적합되기 전에 훈련을 멈추는 정규화 기법
- 훈련하는 동안 주기적으로 성능 검증을 하다가 성능이 더 좋아지지 않으면 과적합이 시작되었다고 판단 → 훈련 멈춤
5.6 데이터 증강
훈련 데이터셋을 이용해서 새로운 데이터를 생성하는 기법
5.6.3 데이터 증강 방식 선택
- 이동
- 회전
- 늘리기
- 좌우/상하 대칭
- 카메라 왜곡
- 잡음 추가
- 색깔 변환
- 잘라내기
- 떼어내기
5.7 배깅
독립된 여러 모델을 동시에 실행한 뒤 개별 모델의 예측을 이용해서 최종으로 예측하는 방법
배깅이 왜 정규화인가?
- 모델이 서로 독립일 때 예측 오차가 모델 수에 비례해서 줄어듬
5.8 드롭아웃
미니배치를 실행할 때마다 뉴런을 랜덤하게 잘라내서 새로운 모델을 생성하는 정규화 방법
5.9 잡음 주입
5.9.1 잡음 주입 방식
- 입력 데이터에 잡음 주입
- 특징에 잡음 주입
- 모델 가중치에 잡음 주입
