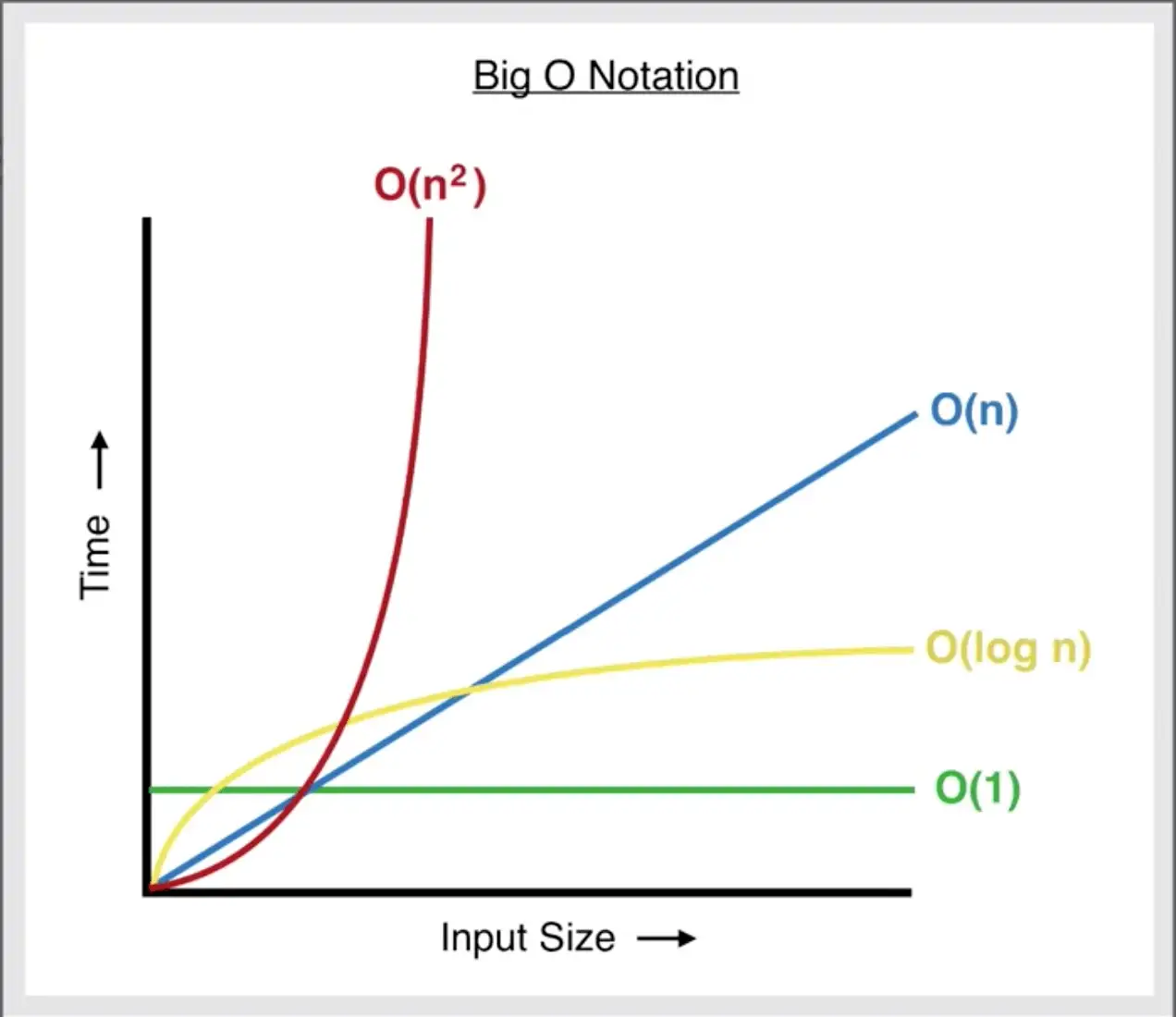
Python 자료형별 연산자의 시간 복잡도 정리
본격적으로 코딩 테스트를 준비하면서, 자료형별 연산자의 시간복잡도에 관심을 가지게 되었다.
특시 백준에서 알고리즘 문제를 풀다보면 '시간 초과'문제를 자주 겪게 되는데, 어떤 함수가 얼마나 비효율적으로 사용되었는지 판단하는것이 항상 '상상의 영역'이었던 것을 생각하면, 잘 정리해 두는 편이 좋을 것 같다.
먼저, 이 포스팅은 python에서의 시간 복잡도를 해당 블로그를 참고하여 작성하였다.
List 자료형
| Operation | Example | Class | Notes | |
|---|---|---|---|---|
| 1 | Index | l[i] | O(1) | 인덱스로 값 찾기 |
| 2 | Store | l[i] = 0 | O(1) | 인덱스로 데이터 저장 |
| 3 | Length | len(l) | O(1) | 리스트 길이 |
| 4 | Append | l.append(5) | O(1) | 리스드 뒤에 데이터 저장 |
| 5 | Pop | l.pop() | O(1) | 가장 뒤의 데이터 pop |
| 6 | Clear | l.clear() | O(1) | l = [] |
| 7 | Slice | l[a:b] | O(b-a) | 슬라이싱되는 요소들 수 만큼 비례 |
| 8 | Extend | l.extend(...) | O(len(...)) | 확장되는 길이만큼 |
| 9 | Construction | list(...) | O(len(...)) | 리스트 길이만큼 |
| 10 | check ==, != | l1 == l2 | O(N) | 전체 리스트가 동일한지 확인 |
| 11 | Insert | l[a:b] = ... | O(N) | 데이터 삽입 |
| 12 | Delete | del l[i] | O(N) | 데이터 삭제 |
| 13 | Containment | x in/not in l | O(N) | 포함 여부 확인 |
| 14 | Copy | l.copy() | O(N) | 복제 |
| 15 | Remove | l.remove(...) | O(N) | 제거 |
| 16 | Pop | l.pop(i) | O(N) | 제거된 값 이후를 전부 한칸씩 당겨줘야함 |
| 17 | Extreme | value min(l)/max(l) | O(N) | 전체 데이터를 확인해야함 |
| 18 | Reverse | l.reverse() | O(N) | 뒤집기 |
| 19 | Iteration | for v in l: | O(N) | 전체 데이터 확인하므로 |
| 20 | Sort | l.sort() | O(N Log N) | 파이썬 기본 정렬 알고리즘 |
| 21 | Multiply | k*l | O(k N) | 리스트의 곱은 리스트 개수 늘어남 |
이 내용에서 개인적으로 관심이 많았던 Operation은 Sort와 pop(insert, delete 등등 마찬가지...)이었다.
그 이유는, 두 Operation을 자주 사용하기는 하지만, python의 내부에 어떻게 구현되어 있는지를 '열어 보지' 않았기 때문에, 매번 효율성의 측면을 의심하며 사용했었기 때문이다.
python에서 기본적으로 제공하는 Sort 연산은 퀵정렬의 형식으로 매우 효율적으로 연산이 된다는것을 알 수 있었고,
반대로, pop이나 delet연산의 경우, 전체 리스트의 요소를 움직여 줘야 하는 등의 이유로 결국 O(N)의 복잡도를 가지는 것을 확인 할 수 있었다.
늘 고민했던, list 자체를 queue나 stack으로 대체해서 사용하는 방법은 결국은 효율성이 낮다는것을 의미한다. (실제로 길이를 많이 늘렸을 때 속도 차이가 나는것을 확인)
이에 대한 답으로, collection의 dequeue를 사용하는것이 좋은 대안이 될 수 있다.
Set 자료형
| Operation | Example | Class | Notes | |
|---|---|---|---|---|
| 1 | Add | s.add(5) | O(1) | 집합 요소 추가 |
| 2 | Containment | x in/not in s | O(1) | 포함 여부 확인 |
| 3 | Remove | s.remove(..) | O(1) | 요소 제거 |
| 4 | Discard | s.discard(..) | O(1) | 특정 요소 제거 |
| 5 | Pop | s.pop() | O(1) | 랜덤하게 하나 pop |
| 6 | Clear | s.clear() | O(1) | similar to s = set() |
| 7 | Construction | set(...) | O(len(...)) | 길이만큼 |
| 8 | check ==, != | s != t | O(len(s)) | 전체 요소 동일 여부 확인 |
| 9 | <= /< | s <= t | O(len(s)) | 부분집합 여부 |
| 10 | >=/> | s >= t | O(len(t)) | 부분집합 여부 |
| 11 | Union | s, t | O(len(s)+len(t)) | 합집합 |
| 12 | Intersection | s & t | O(len(s)+len(t)) | 교집합 |
| 13 | Difference | s - t | O(len(s)+len(t)) | 차집합 |
| 14 | Symmetric Diff | s ^ t | O(len(s)+len(t)) | 여집합 |
| 15 | Iteration | for v in s: | O(N) | 전체 요소 순회 |
| 16 | Copy | s.copy() | O(N) | 복제 |
Dictionary 자료형
| Operation | Example | Class | Notes | |
|---|---|---|---|---|
| 1 | Add | s.add(5) | O(1) | 집합 요소 추가 |
| 2 | Containment | x in/not in s | O(1) | 포함 여부 확인 |
| 3 | Remove | s.remove(..) | O(1) | 요소 제거 |
| 4 | Discard | s.discard(..) | O(1) | 특정 요소 제거 |
| 5 | Pop | s.pop() | O(1) | 랜덤하게 하나 pop |
| 6 | Clear | s.clear() | O(1) | similar to s = set() |
| 7 | Construction | set(...) | O(len(...)) | 길이만큼 |
| 8 | check ==, != | s != t | O(len(s)) | 전체 요소 동일 여부 확인 |
| 9 | <=/< | s <= t | O(len(s)) | 부분집합 여부 |
| 10 | >=/> | s >= t | O(len(t)) | 부분집합 여부 |
| 11 | Union | s, t | O(len(s)+len(t)) | 합집합 |
| 12 | Intersection | s & t | O(len(s)+len(t)) | 교집합 |
| 13 | Difference | s - t | O(len(s)+len(t)) | 차집합 |
| 14 | Symmetric Diff | s ^ t | O(len(s)+len(t)) | 여집합 |
| 15 | Iteration | for v in s: | O(N) | 전체 요소 순회 |
| 16 | Copy | s.copy() | O(N) | 복제 |
