논문 제목:Guiding Large Language Models via Directional Stimulus Prompting
저자 : Zekun Li, Baolin Peng, Pengcheng He, Michel Galley, Jianfeng Gao, Xifeng Yan
요약
- Directional Stimulus Prompting은 대규모 언어 모델(LLMs)을 직접 조정하지 않고, 작은 정책 모델T5등을 통해 각 입력에 맞는 보조 프롬프트를 생성해 LLM을 원하는 방향으로 유도하는 방법
이를 통해 LLM의 성능을 개선하며, 정책 모델은 지도 학습이나 강화 학습으로 최적화함
사용하는곳
- 작고 조정 가능한 언어모델을 사용하여 원하는 LLM의 응답을 원하는 결과 로 유도하는 힌트나 단서 제공
- 기존 미세 조정 방식보다 더 큰 제어력을 제공하며, 모델의 응답을 안해하면서도 모델의 일반적인 능력을 유지
특징
- 가이드 힌트 제공
- 정책 언어 모델 훈련
- 정확도와 사용자 선호도 향상
작동방식
- 힌트 생성
- LLM 출력유도
- 강화 학습을 통해 최적화
정리
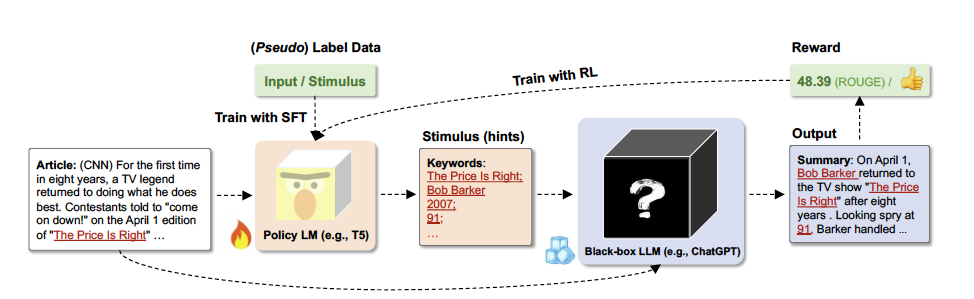
작은 규모의 정책 모델(예: T5)**을 활용하여 각 입력에 맞는 Directional Stimulus를 자동 생성합니다.
지도 학습(SFT) – 소량의 라벨 데이터로 초기 Directional Stimulus 생성 학습
강화 학습(RL) – LLM의 성능(ROUGE 점수, 사용자 선호도 등)을 기준으로 최적화
참고자료
https://slashpage.com/haebom/k5r398nmnnx8emvwje7y?lang=ko
https://brunch.co.kr/@aichaemun/109

개발자를 위한 첫시작