
자연어 처리
XML
- 텍스트 XML 데이터 저장 및 읽기
%%writefile test.xml
<?xml version="1.0" encoding="utf-8"?>
<world name="주소록과 네이버 API 서비스">
<people name="김민수">
<age>15</age>
<tall>183cm</tall>
<add>서울시 서대문구</add>
</people>
<people name="박한솔">
<age>30</age>
<tall>175cm</tall>
<add>서울시 용산구</add>
</people>
<naver_api>
<client_id>JXRlq5D6b1L0PA</client_id>
<client_secret>hwinqikqgbKvH</client_secret>
</naver_api>
</world>- 파싱한다 ET.parse으로 파싱
import xml.etree.ElementTree as ET
# XML 파일 파싱
tree = ET.parse("test.xml")
root = tree.getroot()
# 루트 태그와 이름 속성 출력
print(root.tag)
print(root.get('name'))
# 첫 번째 자식 요소의 두 번째 자식의 텍스트 출력
print(root[0][1].text)
# 모든 자식 요소의 태그와 속성 출력
for child in root:
print(child.tag, child.attrib)
# 'add' 태그를 가진 모든 요소의 텍스트 출력
for add in root.iter('add'):
print(add.text)-
JSON 파일, PDF파일도 가능
-
HWP파일을 경우 텍스트 파일로 변환후 사용함
웹크롤링
- 스크래핑 : 시스템이나 인터넷 상에서 정보를 추출해서 가공
- 랭글링 : 원자료를 분석하기 좋은 형태로 전환하거나 매핑하는 과정
- 파싱 : HTML로 작성된 문법구조 또는 구문을 수집하여 쉬운 언어로 해석
- 인덱싱 : 리스트와 같이 순회 가능한 객체의 한 조각을 잘라내는 것
HTML
- 웹문서를 만들기 위하여 사용하는 기본적인 웹 언어의 한 종류
- tag 와 <>를 사용하여 나타낸다.
- 정적 수집도구(Reqeusts, Urllib) 와 동적 수집도구(Selenium)가 있음
- CSS 디자인 적용하고자하는 HTML의 요소 선택
배운내용추가 부분
- 문서 → 문단 → 문장 → 형태소순으로
- 품사 단위
- 영문 nltk라이브러리
- 한글 KoNLPY, 꼬꼬마. 코모란 한나눔, 메캅, Okt
- 영어는 불용어사전이 있으나 한글은 없다
나이브 베이즈
- 베이즈 정리( 사전 확률과 현재의 정보를 토대로 사후 확률 추론)를 기반으로 한 확률적 분류 모델
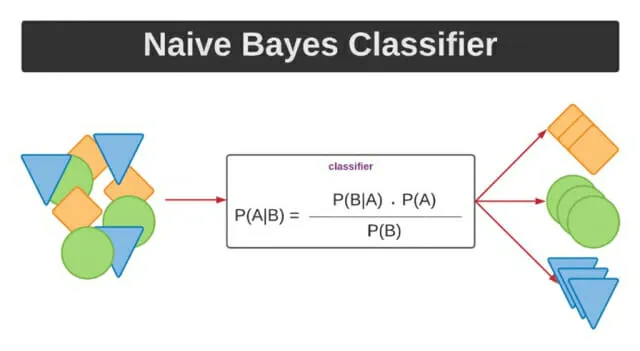
장점
- 구현이 간단하고 계산 효율성이 높음
- 적은 양의 훈련 데이터로도 좋은 성능을 보임
- 다중 클래스 문제에 쉽게 적용 가능
단점
- 특성 간 독립성 가정이 현실과 맞지 않을 수 있음
- 훈련 데이터에서 보지 못한 특성 값에 대해 취약할 수 있음

개발자를 위한 첫시작