🚩 문제
문제설명
프로그래머스 팀에서는 기능 개선 작업을 수행 중입니다. 각 기능은 진도가 100%일 때 서비스에 반영할 수 있습니다.
또, 각 기능의 개발속도는 모두 다르기 때문에 뒤에 있는 기능이 앞에 있는 기능보다 먼저 개발될 수 있고, 이때 뒤에 있는 기능은 앞에 있는 기능이 배포될 때 함께 배포됩니다.
먼저 배포되어야 하는 순서대로 작업의 진도가 적힌 정수 배열 progresses와 각 작업의 개발 속도가 적힌 정수 배열 speeds가 주어질 때 각 배포마다 몇 개의 기능이 배포되는지를 return 하도록 solution 함수를 완성하세요.
제한 사항
- 작업의 개수(progresses, speeds배열의 길이)는 100개 이하입니다.
- 작업 진도는 100 미만의 자연수입니다.
- 작업 속도는 100 이하의 자연수입니다.
- 배포는 하루에 한 번만 할 수 있으며, 하루의 끝에 이루어진다고 가정합니다. 예를 들어 진도율이 95%인 작업의 개발 속도가 하루에 4%라면 배포는 2일 뒤에 이루어집니다.
입출력 예
progresses speeds return [93, 30, 55] [1, 30, 5] [2, 1] [95, 90, 99, 99, 80, 99] [1, 1, 1, 1, 1, 1] [1, 3, 2] 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
🌌 생각
progresses[i] += speeds[i]로 완료 일수를 계산할지, 완료 일수를 따로 구해서 변수로 만드는게 나을지...- 문제 분류가 스택/큐로 되어있는데, 이 경우는 앞선 단계의 개발이 완료되지 않으면 뒷쪽 단계는 완료되도 배포를 못하므로,
FIFO구조인 큐 형태라는 얘긴데, 큐를 사용하라는 건가? - 배포되는 기능 수를 어떻게 구분하지? 탐색 알고리즘을 좀 찾아봐야겠다.
📝 코드 작성
import java.util.*;
class Solution {
public int[] solution(int[] progresses, int[] speeds) {
int[] answer = {};
List<Integer> ans = new ArrayList<Integer>();
Queue<Integer> queue = new LinkedList<>();
int[] dev = new int[speeds.length];
// 개발 완료까지 필요 일수 계산
for (int i=0; i<progresses.length; i++) {
int progress = progresses[i];
int day = 0;
while (true) {
progress += speeds[i];
day++;
if (progress >= 100) {
break;
}
}
dev[i] = day;
queue.offer(day);
}
int tmp = 0;
int count = 0;
while (!queue.isEmpty()) {
tmp = queue.poll();
count++;
if (queue.isEmpty()) { // 마지막 값이라면
ans.add(count);
} else if (queue.peek() > tmp) {
// 뒷 값이 더 큰 경우
ans.add(count);
count = 0;
tmp = 0;
}
}
return ans.stream().mapToInt(i->i).toArray();
}
}처음 시도한 코드. 솔직히 돌리면서 안될 줄은 알고 있었다. 내가 봐도 어딘가 나사가 빠졌거든.
내가 생각하고 시도한 방식은,
- 먼저 각 작업 단계의 완료까지의 필요한 일수(
dev)을 구하고, Queue에 순차적으로 각 단계의 필요한 일수를 넣어준다.Queue에서 값을 하나씩 꺼내면서
1)tmp임시 변수에 방금 꺼낸 값을 넣어준다.
2)count값을 증가. (Queue에서 값을 꺼냈으므로, 작업이 완료 됐다고 가정)
3)Queue의Top Pointer값이 방금 꺼낸 값보다 높다면,
다음 단계는 아직 완료까지 개발 일수가 더 필요하다는 얘기니 지금까지의count(배포 수)를 list에 추가 후count,tmp를 초기화 한다.
4)Queue의Top Pointer값이 방금 꺼낸 값보다 낮다면,
묶어서 배포가 되는 경우니count만 증가.Queue가 빌때까지 반복하면[배포, 되는, 기능수]의 list가 생성이 될 것임.
코드 실행하면 초기 테스트 케이스 2개는 통과가 되는데, 채점하니까 다 틀린다.
import java.util.*;
class Solution {
public int[] solution(int[] progresses, int[] speeds) {
List<Integer> ans = new ArrayList<Integer>();
int[] dev = new int[progresses.length];
Queue<Integer> queue = new LinkedList<>();
// 개발 완료까지 필요 일수 계산
for (int i=0; i<progresses.length; i++) {
int progress = progresses[i];
int day = 0;
while (true) {
progress += speeds[i];
day++;
if (progress >= 100) {
break;
}
}
dev[i] = day;
queue.offer(day);
}
int tmp = 0;
int count = 0;
while (!queue.isEmpty()) {
if (tmp >= queue.peek()) {
queue.poll();
} else {
tmp = queue.poll();
}
count++;
if (queue.isEmpty()) { // 마지막 값이라면
ans.add(count);
} else if (queue.peek() > tmp) {
// 뒷 값이 더 큰 경우
ans.add(count);
count = 0;
tmp = 0;
}
}
return ans.stream().mapToInt(i->i).toArray();
}
}통과한 코드.
다시 생각해보니 조건이 약간 잘못 되어 있었다.
tmp = queue.poll()로 무조건 값을 털면, 한번에 3개 이상 완료 되는 경우같은, 앞의 값이 높고 뒷 값이 낮은 경우 문제가 생긴다.
그 부분의 조건을 추가해주었다.
✔️ 다른 사람의 코드
간결한 코드
import java.util.ArrayList;
import java.util.Arrays;
class Solution {
public int[] solution(int[] progresses, int[] speeds) {
int[] dayOfend = new int[100];
int day = -1;
for(int i=0; i<progresses.length; i++) {
while(progresses[i] + (day*speeds[i]) < 100) {
day++;
}
dayOfend[day]++;
}
return Arrays.stream(dayOfend).filter(i -> i!=0).toArray();
}
}
내 머리를 딱 때린 코드.
100일을 가정한 길이 100짜리 array를 만들고, 해당 일자에 몇개가 끝나는지(day*speeds[i] < 100)
넣어서, 0이 아닌 값들만 모아서 다시 배열로 만들어서 리턴한다.
발상도 좋고, 내가 원래 이렇게 짜고 싶었는데 방법도 모르고 저렇게 한다는 생각도 못했다.
Queue를 사용한 코드
import java.util.*;
class Solution {
public int[] solution(int[] progresses, int[] speeds) {
Queue<Integer> q = new LinkedList<>();
List<Integer> answerList = new ArrayList<>();
for (int i = 0; i < speeds.length; i++) {
double remain = (100 - progresses[i]) / (double) speeds[i];
int date = (int) Math.ceil(remain);
if (!q.isEmpty() && q.peek() < date) {
answerList.add(q.size());
q.clear();
}
q.offer(date);
}
answerList.add(q.size());
int[] answer = new int[answerList.size()];
for (int i = 0; i < answer.length; i++) {
answer[i] = answerList.get(i);
}
return answer;
}
}Queue를 사용한 내가 한 것 보다 더 정답인 것 같은 방식.
이 경우는 남은 일자로 계산을 했다.
🔍 탐색 알고리즘
선형 탐색 알고리즘 (Linear Search Algorithm)
맨 앞이나, 맨 뒤부터 순서대로 하나하나 찾아보는 알고리즘이다.
가장 단순하고 간단한 탐색 알고리즘이다.
맨 끝부터 하나하나 원하는 값을 찾아본다.
원하는 값을 찾으면, 탐색을 종료한다.
예시
5를 찾을 때, 맨 왼쪽에 있는 1부터 시작해서 하나씩 탐색한다.

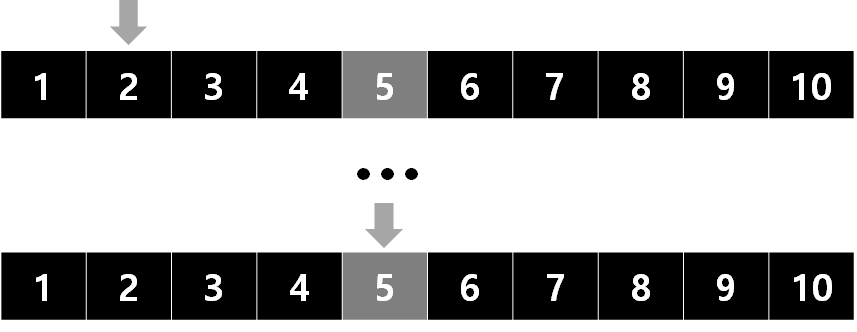
시간 복잡도
길이 n짜리의 리스트를 탐색할 때,
최선의 경우
- 리스트의 첫 번째 원소가 정답인 경우 : 1번
최악의 경우
- 리스트의 맨 마지막 원소가 정답이거나, 리스트에 정답이 없을 때 : n번
따라서 O(n)의 시간복잡도를 가진다.
이진 탐색 알고리즘 (Binary Search Algorithm)
중간지점을 기준으로 데이터를 반씩 나눠서 탐색하는 알고리즘이다.
중간지점을 선택한 뒤, 중간지점을 기준으로 왼쪽 혹은 오른쪽 부분만 남긴다.
남긴 부분 중에서 다시 중간지점을 선택한 뒤, 왼쪽 혹은 오른쪽만 남긴다.
위 과정을 원하는 값을 찾을 때 까지 반복한다.
예시
5를 찾는 경우,
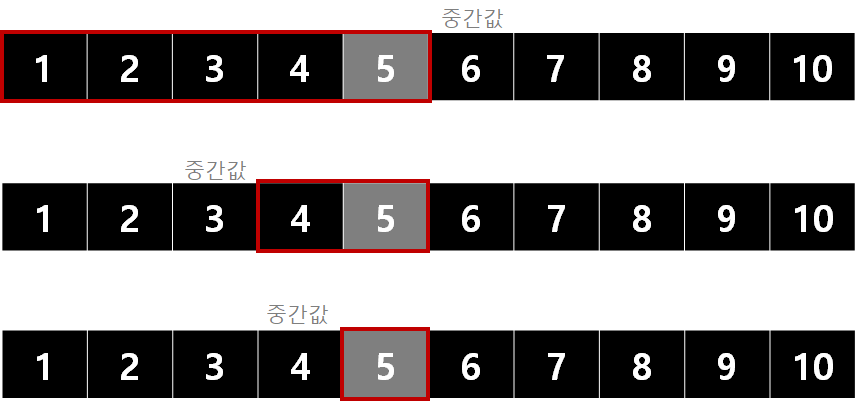
시간 복잡도
최선의 경우
- 리스트의 중간부분이 정답일 때 : 1번
최악의 경우
- 리스트에 정답이 없는 경우 : log2(n) 번
따라서 O(logn)의 시간 복잡도를 가진다
선형탐색은 n이 증가함에 따라 시간복잡도가 선형적으로 증가하지만, 이진탐색은 n이 증가해도 시간복잡도가 아주 천천히 증가한다.
보통 정렬된 리스트에는 이진탐색을 사용하고,
정렬되지 않은 리스트에는 선형탐색을 사용한다.
