RDBMS & NoSQL
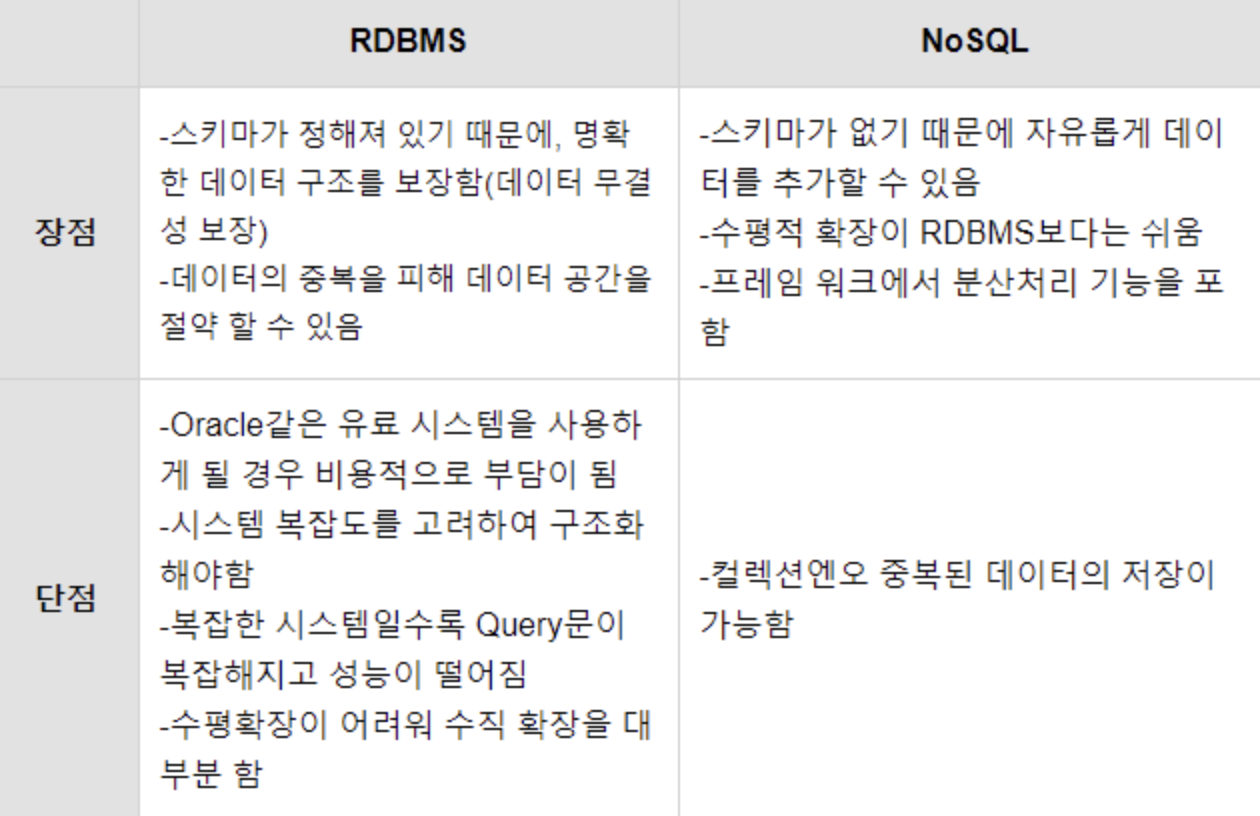
RDBMS
RDBMS는 정해져있는 데이터 스키마에 따라 데이터베이스 테이블에 저장되며,
관계를 통한 테이블간 연결을 통해 사용된다.
이 때문에 RDBMS는 데이터 관리를 효율적으로 하기위해 구조화가 굉장히 중요하다.
※스키마란?
데이터베이스에서 자료의 구조, 자료의 표현 방법, 자료 간의 관계를 형식 언어로 정의한 구조이다. 데이터베이스 관리 시스템(DBMS)이 주어진 설정에 따라 데이터베이스 스키마를 생성하며,
데이터베이스 사용자가 자료를 CURD 할 때, DBMS는 자신이 생성한 데이터베이스 스키마를 참조하여 명령을 수행한다.
NoSQL
NOSQL 은 Not Only SQL, Non relational Database 라고 부른다.
NOSQL은 관계형 데이터베이스와 반대되는 방식을 사용하여 스키마와 관계라는 개념이 없다.
RDBMS에서는 스키마에 맞추어 데이터를 관리하여야 하지만 NOSQL은 스키마가 없어 좀 더 자유롭게 데이터를 관리할 수 있다.
NOSQL에서 테이블과 같은 개념으로 컬렉션이라는 형태로 데이터를 관리한다.
※수직적 확장? 수평적 확장?
- 수직적 확장이란 기존의 서버를 더 좋은 H/W로 바꾸는 방법(scale up)
- 수평적 확장은 기존에 사용하던 서버 외에 서버를 추가하여 성능을 높이는 방법(scale out)
샤딩
Q. 데이터가 많아서 검색이 느린데 더 빠르게 할 수 있는 방법은 없을까?
샤딩은 수평 분할(Horizontal Partitioning) 과 동일하며,
인덱스의 크기를 줄이고, 작업 동시성을 늘리기 위한 것이다.
수평 분할(Horizontal Partitioning)이란 스키마(schema)가 같은 데이터를 두 개 이상의 테이블에 나누어 저장하는 디자인을 말한다.
데이터베이스를 샤딩하게 되면 기존에 하나로 구성될 스키마를 다수의 복제본으로 구성하고
각각의 샤드에 어떤 데이터가 저장될지를 샤드키를 기준으로 분리한다.
단점: 프로그래밍, 운영적인 복잡도는 더 높아지는 단점이 있습니다.
- 가능하면 Sharding을 피하거나 지연시킬 수 있는 방법을 찾는 것이 우선되어야 합니다.
Read 부하가 크다면?
Cache나 Database의 Replication을 적용하는 것도 하나의 방법입니다.
Table의 일부 컬럼만 자주 사용한다면?
Vertically Partition도 하나의 방법입니다. Data를 Hot, Warm, Cold Data로 분리하는 것입니다.
Algorithm Sharding
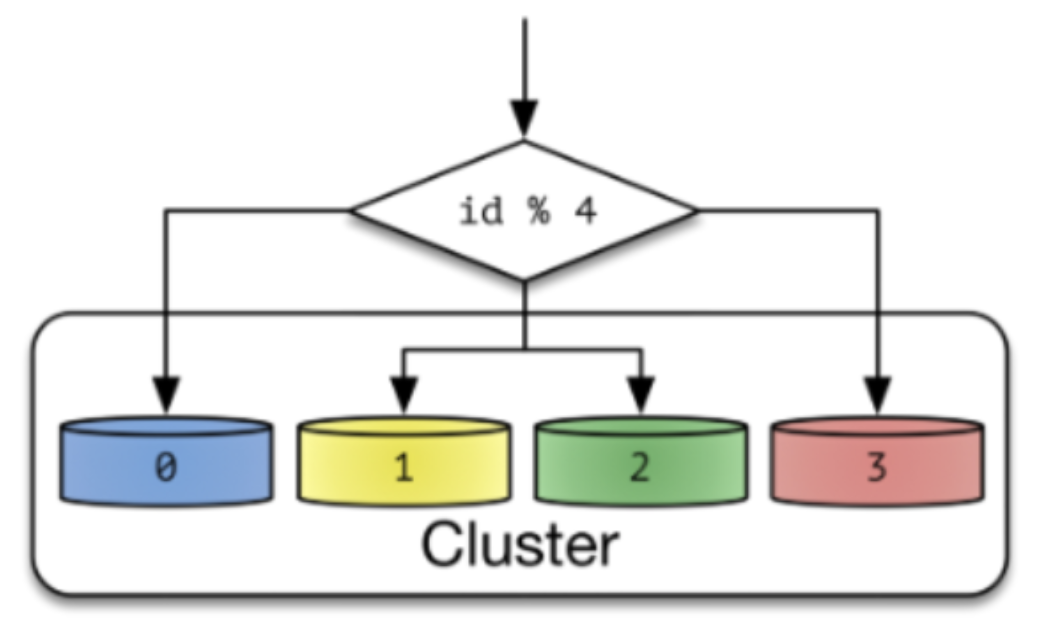
Database id를 단순하게 나누어 샤딩하는 방식
Sharding Key는 hash(key) % NUM_DB 같은 방식
- 장점 : 같은 값을 가지는 key-value 데이터베이스에 적합하다.
- 단점 : Cluster를 포함하는 Node 갯수가 변하게 되면 Resharding이 필요하다. Hash Key로 분산되기 때문에 공간에 대한 효율이 부족하다.
Dynamic Sharding
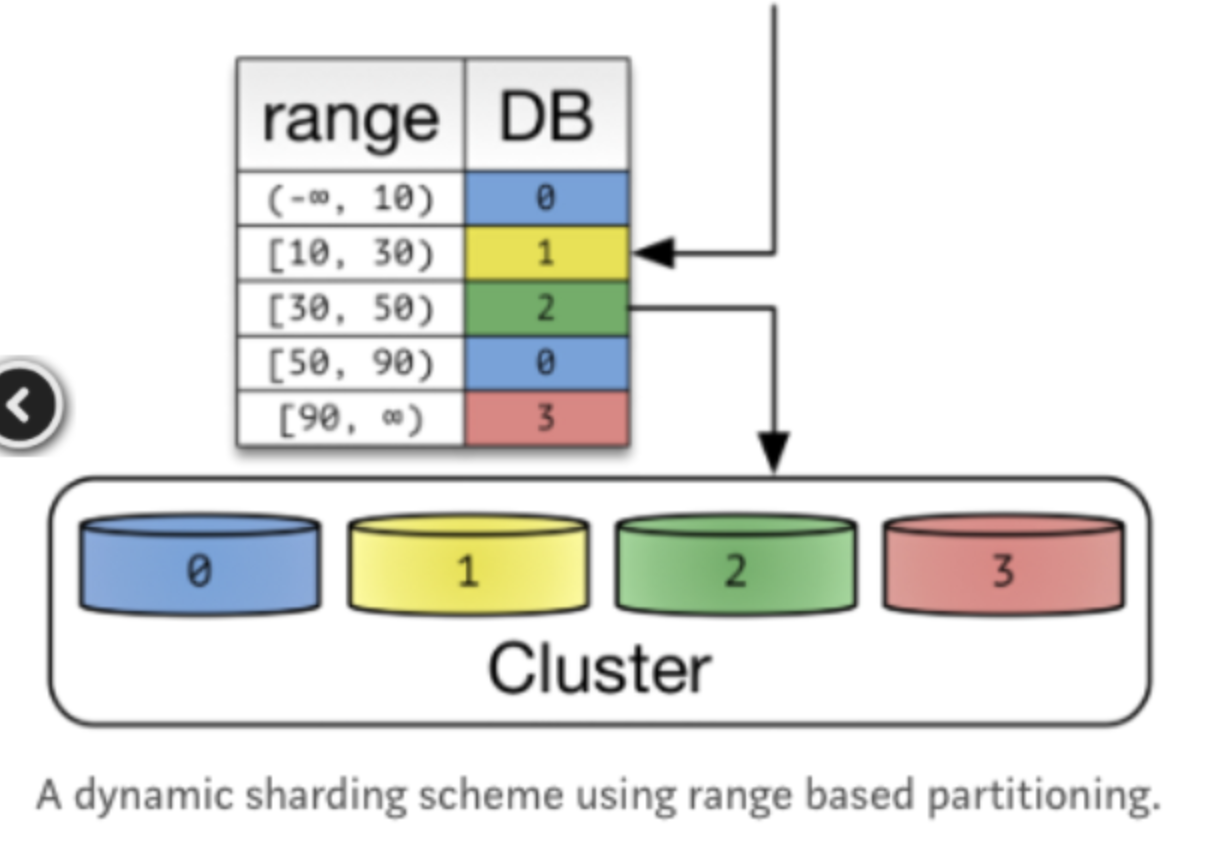
클라이언트는 Locator Service에 접근하여 Shard Key를 얻는다.
-
장점 : Cluster가 포함하는 Node 갯수가 변하면 Shard Key를 추가하기만 하면 된다.
확장에 유연하게 대처가능하다. -
단점 : Data Relocation시에는 Locator Service의 Shard key Table도 일치시켜야 한다. Locator에 의존할 수 밖에 없는 구조이다.
Entity Group
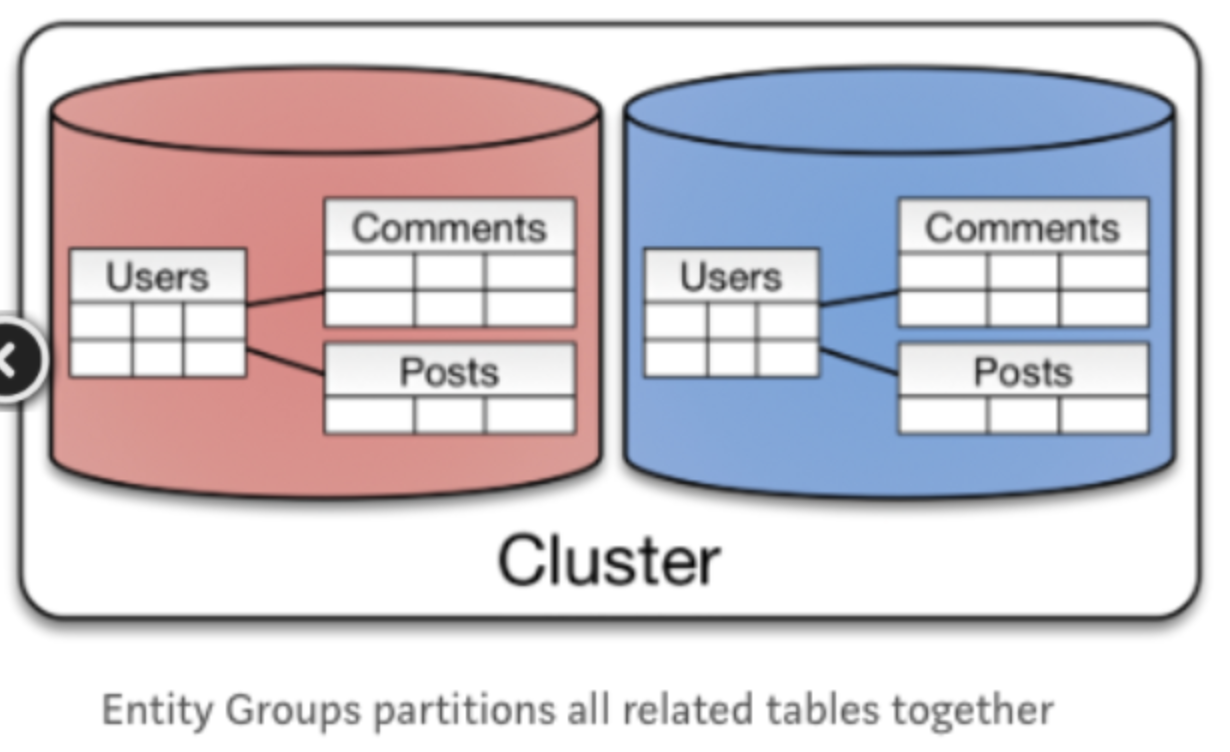
RDBMS의 Join, Index, Transaction을 사용하여 복잡도를 줄이는 방식과 유사
동일한 파티션의 관련 엔티티를 저장하여 단일 파티션 안에서 추가 기능을 제공하는 방식
- 장점 :하나의 물리적인 Shard에 쿼리를 진행하면 효율적이된다.
사용자의 증가에 따른 확장성이 좋은 파티셔닝이다. - 단점 :특정 파티션간 쿼리가 자주 요구되는 경우가 있다.
Replication
2개 이상의 DBMS를 Master와 Slave로 나누어 동일한 데이터를 저장한다.
-
Master DB는 : Insert, Update, Delete의 기능을 수행하고, Slave DB에 실제 데이터를 복사한다.
-
Slave DB 시간이 오래걸리는 Select문의 기능을 수행하여 전체적인 Select문 성능을 향상시킨다.
DB 이중화
- master db에서는 insert , update ,delete 작업
- slave db에서는 read용으로 사용
mysql replication을 통해 데이터 복제
replication 장점
- DB 서버 부하 분산
- master db 장애시 slave db로 대체 가능
replication 단점
- Master-Slave pair 관리:서버들이 많아질 경우, Master와 Slave의 짝을 관리하는 것이 쉽지 않다.
- 실패 상황에서의 복구 : Master가 실패시 Master와 Slave의 교체, 혹은 Slave의 데이터를 Master로 복사하는 등의 작업을 수동으로 진행하여야 한다. Slave의 실패인 경우도 마찬가지이다.
- binary log의 관리: Master 에 쌓이는 binary log에 대한 관리 또한 수동으로 처리하여야 한다.(cron등을 이용하여 정기적인 삭제 필요)
- replication 지연발생: Master의 처리량이 많은 경우 Slave는 지연시간이 발생하게 되고 그 시간동안의 데이터는 일치하지 않는 문제가 있다.
파티셔닝
VLDB(Very large DBMS)
- 전체 DB가 하나의 DBMS시스템에 다 들어가기 힘들어지는 경우
- 테이블 들을 여러 개의 군으로 나눠 분산 저장
- 하나의 테이블이 방대한 경우에는 사전방식과 같이 나눠 저장
이점
- 데이터 전체 검색시 필요한 부분만 탐색해 성능 증가
- 전체 데이터를 손실할 가능성이 줄어듦 -> 가용성향상
- 파티션별 백업/복구 가능
- 파티션 단위로 I/O 분산가능 -> 업데이트 성능 증가
방식 *범위(range) a-m/n-r/s-z
- 해시(hash) 해시함수 파티션별로 크기를 비슷하게 나눔
- 리스트(list) 특정한 컬럼을 기준
EX) Card 테이블에 연도 (CreationTime) 컬럼을 추가하고 파티셔닝하시오.
create table businessCard(ID INT NoT Null, Name varchar(255), Address varchar(255) ,
Telephone varchar(255) , CreateTime DATE)
PARTITION BY RANGE(YEAR(CreationTime)) (
PARTITION p0 VALUES LESS THAN(2013),
PARTITION p1 VALUES LESS THAN(2014),
PARTITION p2 VALUES LESS THAN(2015),
PARTITION p3 VALUES LESS THAN MAXVALUE); 파티션 추가 와 삭제
ALTER TABLE Card ADD PARTITION(PARTITION p4 VALUES LESS THAN(2005));
ALTER TABLE Card DROP PARTOTION p4;파티션 분할 / 병합
ALTER TABLE CardREORGANIZE
PARTITION p3 INTO(PARTITION p3 VALUES LESS THAN(2015),
PARTITION p4 VALUES LESS THAN MAXVALUE);Lock이란?
데이터의 일관성을 보장하기 위한 방법입니다.
Lock의 종류는?
Lock은 상황에 따라서 크게 두가지로 나누어 집니다.
1. Shared Lock(공유 Lock 또는 Read Lock)
보통 데이터를 읽을 때 사용합니다. 원하는 데이터에 lock을 걸었지만 다른 세션에서 읽을 수 있습니다.
공유Lock을 설정한 경우 추가로 공유Lock을 설정할 수 있지만, 배타적 Lock은 설정할 수 없습니다.
즉, 내가 보고 있는 데이터는 다른 사용자가 볼 수 있지만, 변경할 수는 없습니다.
2. Exclusive Lock(배타적 Lock 또는 Write lock)
보통 데이터를 변경할 때 사용합니다. 이름에서 느껴지는 것 처럼 해당 Lock이 해제되기 전까지는, 다른 공유Lock, 배타적Lock을 설정할 수 없습니다.
즉, 읽기 기와 쓰기가 불가능하다는 의미입니다.
Blocking ?
Lock들의 경합(Race condition이라고도 합니다)이 발생하여 특정 세션이 작업을 진행하지 못하고 멈춰 선 상태를 의미합니다.
- 이를 해결하는 방법은 Transaction commit 또는 rollback 뿐입니다.
경합이 발생할 때, 먼저 Lock을 설정한 트랜젝션을 기다려야하기 때문에, 이런 현상이 반복되면 빠른 서비스를 제공할 수 없습니다.
해결방안
- SQL 문장에 가장 빠르게 실행되도록 리펙토링하는 것이 가장 기본이며 효과적인 방법입니다.
- 트랜젝션을 가능한 짧게 정의하면 경합을 줄일 수 있습니다.
- 동일한 데이터를 동시에 변경하는 작업을 하지 않도록 설계하는 것이 좋습니다. 또한 트랜젝션이 활발한 주간에는 대용량 갱신 작업을 수행하면 안됩니다.
- 대용량작업이 불가피할 경우, 작업단위를 쪼개거나 lock_timeout을 설정하여 해당 Lock의 최대시간을 설정할 수 있습니다.
