트랜잭션과 락
🟧 트랜잭션의 개념
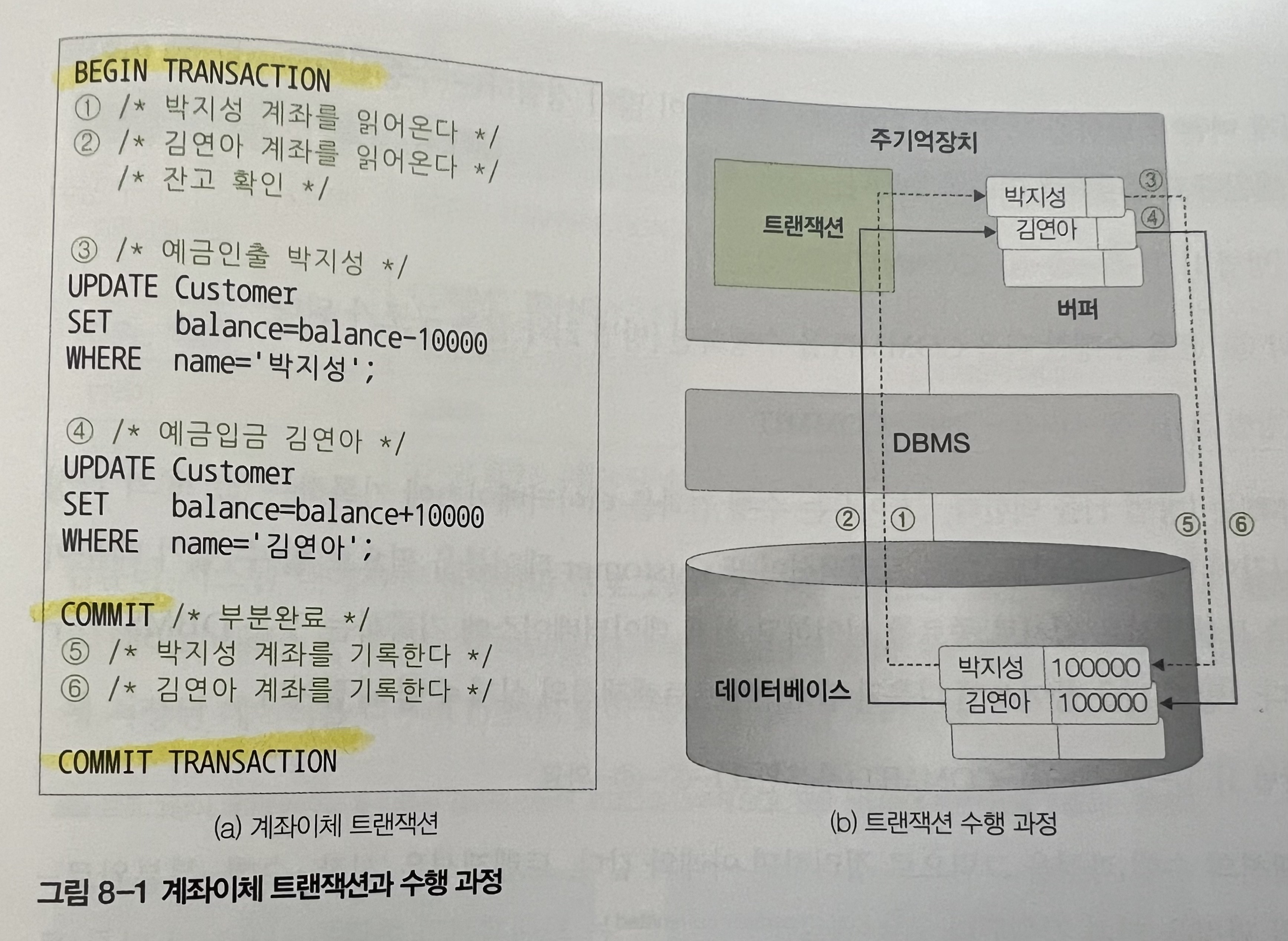
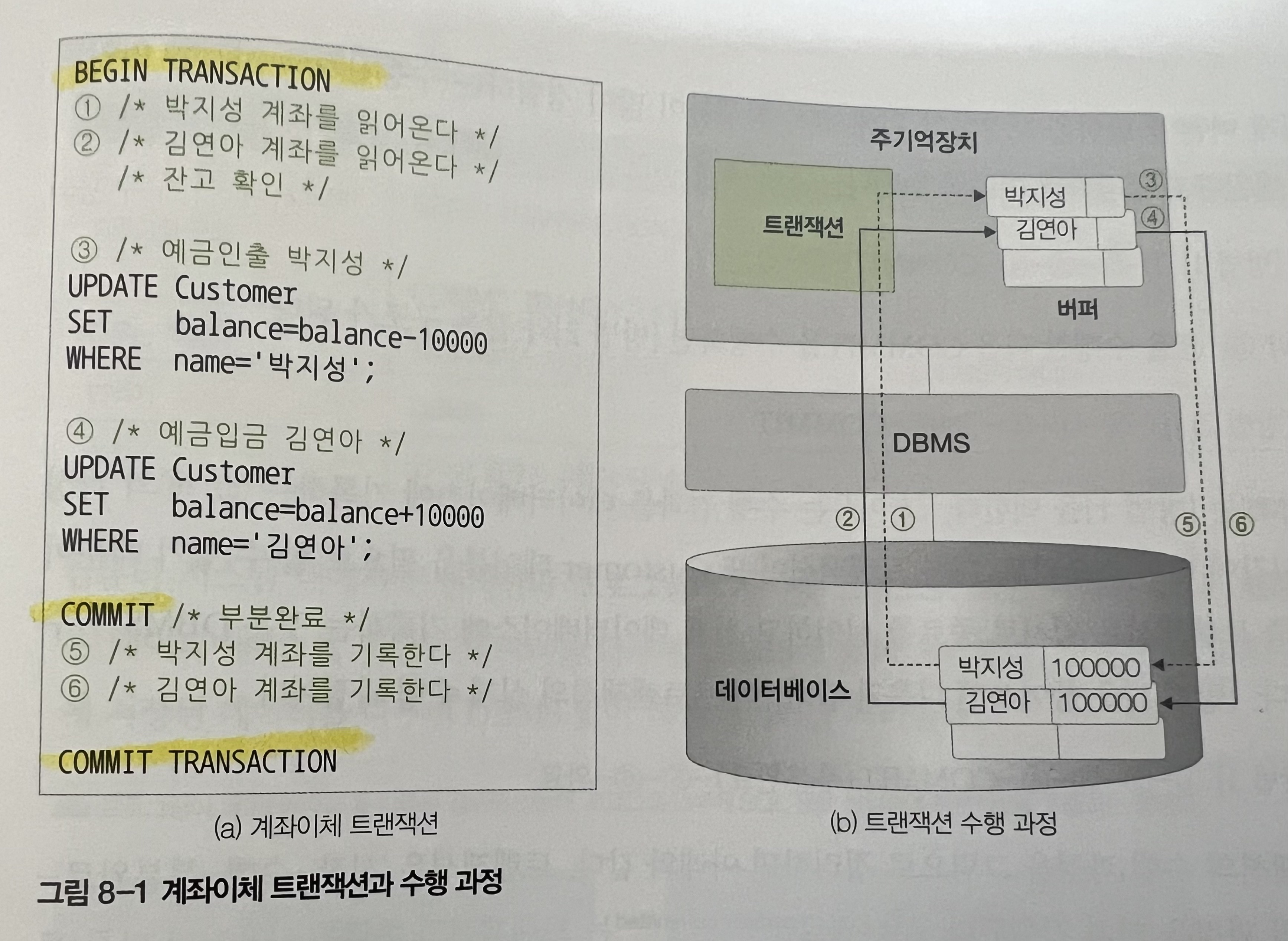
트랜잭션 : DBMS에서 데이터를 다루는 논리적인 작업의 단위
-
데이터베이스의 데이터는 하드디스크에 저장되어 있고,
처리를 위해서는 반드시 주기억장치 버퍼로 사본을 읽어와야 한다 -
트랜젝션은 '시작-수행-부분완료-완료'의 과정을 거쳐서 진행된다. (COMMIT은 트랜잭션을 부분완료시키는 명령어)
=> 트랜잭션은 데이터베이스에 저장된 테이블을 읽어와 주기억 장치 버퍼에 저장하고,
버퍼에 저장된 데이터를 수정한 후 최종적으로 데이터베이스에 다시 저장한다.
🟧 트랜잭션의 성질
ACID성질
- 원자성(Atomicity): 트랜잭션에 포함된 작업은 전부 수행되너가 아니면 전부 수행되지 않아야(all or nothing) 한다.
- 일관성(Consistency): 트랜잭션을 수행하기 전이나 수행한 후나 데이터베이스는 항상 일관된 상태를 유지해야 한다.
- 고립성(Isolation): 수행중인 트랜잭션에 다른 트랜잭션이 끼어들어 변경 중인 데이터 값을 훼손하는 일이 없어야 한다.
- 지속성(Durability): 수행을 성공적으로 완료한 트랜잭션은 변경한 데이터를 영구히 저장해야한다. 저장된 데이터베이스는 저장 직후 혹은 어느때나 발생할 수 있는 정전, 장애, 오류에 영향을 받지 않도록 해야 한다.
🟧 동시성 제어
트랜잭션이 동시에 실행될 때 데이터베이스의 일관성을 해치지 않도록 드랜잭션의 데이터 접근을 제어하는 DBMS의 기능이다.
🟧 락
락: 트랜잭션이 데이터를 읽거나 변경할 때 데이터에 표시하는 잠금 장치이다.
락의 유형
- 공유락(shared lock) : 읽기를 할 때 사용하는 잠금장치
- 배타락(exclusive lock) : 쓰기를 할 때 사용하는 잠금 장치
🟧 2단계 락킹(2 phase locking)
트랜잭션이 락을 걸고 해제하는 시점을 2단게로 나누어 시행하는 락킹 기법이다.
- 확장단계(Growing phase, Expanding phase) : 트랜잭션이 필요한 락을 획득하는 단계, 이미 획득한 락을 해제하지 않는다.
- 수축단계(Shrinking phase) : 트랜젝션이 락을 해제하는 단계, 새로운 락을 획득하지 않는다.
🟧 데드락
데드락(deadlock) or 교착상태 :2단계 락킹 기법을 사용하면 데이터베이스의 일관성을 유지할 수 있다. 하지만 두개이상의 트랜잭션이 각각 자신의 데이터에 대하여 락을 획득하고, 상대방 데이터에 대하여 락을 요청하면 무한 대기 상태에 빠질 수 있다.
- 데드락 해결 : 일반적으로 데드락이 발생하면 DBMS는 T1혹은 T2의 작업 중 하나를 강제로 중지시킨다. 그 결과 나머지 트랜잭션은 정상적으로 실행된다.
이때 중지시키는 트랜잭션에서 변경한 데이터는 원래 상태로 되돌려 놓는다.
🟧 트랜잭션 고립수준
트랜잭션 동시 실행 문제
1. Dirty Read : 다른 트랜잭션이 COMMIT하지 않는 데이터를 읽은 후 다른 트랜잭션이 철회(ROLLBACK)하면서 발생하는 현상
2. Non-Repeatable Read : 트랜잭션 중간에 다른 트랜잭선이 변경한 데이터를 읽으면서 발생하는 현상
3. Phantom Read : 트랜잭션 중간에 다른 트랜잭션이 삽입한 데이터를 읽으면서 발생하는 현상
1. ACID 원칙 중 “Isolation”을 구현하기 위해 RDBMS가 제공하는 4단계(READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, SERIALIZABLE)의 차이점을 실제 현상(Dirty Read, Non-Repeatable Read, Phantom Read)와 연관지어 설명해 보세요.
-
Read Uncommitted(Level=0) : 고립수준이 가장 낮은 명령어로, 자신의 데이터에 아무런 공유락을 걸지 않는다. 또한 다른 트랜잭션에 공유락과 배타락이 걸린 데이터를 대기하지 않고 읽는다. 심지어 다른 트랜잭션이 COMMIT하지 않는 데이터도 읽을 수 있다.
때문에, Dirty Read가 발생한다. -
Read Committed(Level=1) : Dirty Read를 피하기 위해, 자신의 데이터를 읽는 동안 공유락을 걸지만 트랜잭션이 끝나기 전에라도 해지가능하다.
SQL Server의 기본설정이다.
Non-Repeatable Read발생 : ex) 트랜잭션 T1은 Book테이블에 저장된 도서 가격의 총액 계산, T1에서 두번 조회한 도서 가격의 총액이 서로 다름 => 이유? 트랜잭션 T2가 중간에 Book테이블의 price를 변경하고 변경된 결과를 T1이 다시 읽었기 때문에 발생 -
Reapeatable Read(Level=2) : 자신의 데이터에 설정된 공유락과 배타락을 트랜잭션이 종료할 때까지 유지하여 다른 트랜잭션이 자신의 데이터를 갱신(UPDATE)할 수 없도록 한다.
Phantom Read 발생 : ex) 새로운 데이터가 삽입되어 발생하는 유령데이터 읽기 문제는 해결 할 수 없다. => 이유? 트랜잭션 T1이 Book테이블에 저장된 도서 가격의 총액을 조회하는 과정에서 T2가 중간에 삽입한 데이터 값의 영향을 받기 때문 -
Serializable(Level=3) : 고립수준이 가장 높은 명령어. 실행 중인 트랜잭션은 다른 트랜잭션으로부터 완벽하게 분리된다. 데이터 집합에 범위를 지어 잠금을 설정할 수 있기 때문에 다른 사용자가 데이터를 변경하려고 할 때 트랜잭션을 완벽하에 분리할 수 있다.
2. 동시에 실행되는 두 트랜잭션이 교착(Deadlock)에 빠지는 전형적인 시나리오를 설명해 주시고, MySQL이 Deadlock을 감지·해결하는 과정을 설명해 보세요.
Deadlock은 두 개 이상의 트랜잭션이 서로가 필요로 하는 자원을 점유하고, 서로의 자원을 기다리는 상황으로 발생합니다.
예를 들어, 트랜잭션 A는 테이블의 행 1을 잠근 후 행 2를 요청하고, 동시에 트랜잭션 B는 행 2를 잠근 후 행 1을 요청하는 상황을 생각할 수 있습니다. 이 경우 두 트랜잭션은 서로 상대방이 잠근 자원을 기다리면서 순환 대기 상태에 빠지게 되고, 이로 인해 Deadlock이 발생합니다.
MySQL(InnoDB 스토리지 엔진 기준)은 이러한 Deadlock을 자동으로 감지하고 해결합니다.
내부적으로는 트랜잭션들의 잠금 대기 관계를 잠금 대기 그래프(Lock Wait Graph)로 구성한 뒤, 이 그래프에서 사이클(순환 대기)을 탐지합니다. 사이클이 감지되면, 비용이 가장 적은 트랜잭션을 선택하여 롤백시킵니다.
이 과정은 자동으로 수행되며, 애플리케이션 입장에서는 "Deadlock found when trying to get lock"과 같은 에러를 통해 알 수 있습니다. 개발자는 이런 상황에서 트랜잭션을 재시도할 수 있도록 로직을 구성하는 것이 좋습니다.
3. MVCC(Multi-Version Concurrency Control, 다중 버전 동시성 제어)는 무엇이며, 전통적인 잠금 방식과 비교했을 때 어떤 장단점이 있나요? MVCC가 어떻게 동시성을 향상시키는지 설명해주세요.
MVCC는 Multi-Version Concurrency Control의 약자로, 데이터의 여러 버전을 관리함으로써 동시성을 높이는 기술입니다.
기존의 잠금 기반 방식은 데이터를 읽거나 쓸 때 잠금을 걸어 다른 트랜잭션의 접근을 차단하지만, 이로 인해 성능 저하와 교착 상태가 발생할 수 있습니다.
MVCC에서는 트랜잭션마다 고유한 스냅샷을 참조하도록 하여, 읽기 작업은 잠금 없이 과거 버전을 참조합니다. 쓰기 작업은 기존 데이터를 직접 수정하는 것이 아니라 새로운 버전을 생성합니다.
이 방식의 장점은 다음과 같습니다:
• 읽기 작업이 락 없이 가능하여 동시성이 매우 높습니다.
• Dirty Read, Non-Repeatable Read를 방지합니다.
단점으로는:
• 삭제된 버전이 메모리에 남아 있어 저장 공간 낭비가 발생할 수 있고,
• 주기적인 Garbage Collection이 필요합니다.
이러한 MVCC 방식 덕분에, PostgreSQL과 InnoDB는 높은 트랜잭션 처리 성능을 유지하면서도 일관성을 보장할 수 있습니다.
4. 2단계 잠금(Two-Phase Locking, 2PL) 프로토콜은 무엇이며, 트랜잭션의 직렬 가능성(Serializability)을 어떻게 보장하는지 설명해주세요. 2PL의 단점은 무엇일까요?
2PL(Two-Phase Locking) 프로토콜은 트랜잭션의 직렬 가능성(Serializability) 을 보장하는 대표적인 잠금 기법입니다.
이 방식에서는 트랜잭션이 다음 두 단계를 반드시 따릅니다:
1. 잠금 획득 단계(Growing Phase): 트랜잭션은 필요한 모든 자원에 대한 잠금을 얻습니다.
2. 잠금 해제 단계(Shrinking Phase): 한 번이라도 잠금을 해제하면, 이후에는 새로운 잠금을 획득할 수 없습니다.
이 규칙을 따를 경우 트랜잭션 간의 실행 순서를 직렬화 가능한 순서로 정렬할 수 있기 때문에 데이터의 일관성을 유지할 수 있습니다.
하지만 단점도 존재합니다:
• 트랜잭션이 잠금을 오래 유지할 경우 경합이 심해지고,
• 트랜잭션 간 순환 대기가 발생하면 Deadlock 가능성도 존재합니다.
따라서 2PL을 사용할 때는 교착 방지 전략이나 타임아웃 설정이 함께 고려되어야 합니다.
5. 인덱스 구조(B-Tree, Hash)에 따라 잠금 단위와 경합 양상이 어떻게 달라지나요?
인덱스 구조는 데이터 접근 방식뿐 아니라 잠금 경합의 양상에도 영향을 미칩니다.
1. B-Tree 인덱스:
• 범위 검색이 가능한 구조이며, 각 노드가 정렬된 상태로 유지됩니다.
• 예를 들어 WHERE age BETWEEN 20 AND 30 같은 쿼리는 여러 리프 노드를 탐색하면서 여러 페이지에 걸쳐 잠금이 걸릴 수 있습니다.
• 이로 인해 잠금 범위가 넓어지고 경합이 발생할 가능성이 높습니다.
2. Hash 인덱스:
• 키 값에 해시 함수를 적용하여 특정 버킷으로 바로 접근합니다.
• WHERE id = 123처럼 정확한 키 값 검색에서 빠른 성능을 보이며, 잠금 범위가 매우 좁습니다.
• 하지만 범위 검색이 불가능하다는 제약이 있습니다.
따라서 B-Tree는 유연한 검색이 가능하지만 경합에 취약하고, Hash는 빠른 단일 키 검색이 가능하지만 범용성이 떨어집니다.
