Qdrant란 무엇인가?
등장 배경
최근 AI 기술이 일상 속에 깊숙이 들어오면서 단순한 키워드 검색만으로는 사용자의 의도를 정확히 파악하기 어려워졌습니다.
지금 필요한 건 ‘단어’가 아닌 ‘의미’로 검색하는 방식입니다. 그리고 바로 이때 필요한 것이 ‘벡터 데이터베이스’입니다.
VectorDB란 무엇인가?
기존 관계형 데이터베이스(RDB)는 데이터를 테이블 형태로 저장하고, 행과 열에 따라 조건을 걸어 조회하는 방식입니다.
"Vector databases are a relatively new way for interacting with abstract data representations derived from opaque machine learning models such as deep learning architectures.
These representations are often called vectors or embeddings and they are a compressed version of the data used to train a machine learning model to accomplish a task like sentiment analysis, speech recognition, object detection, and many others."
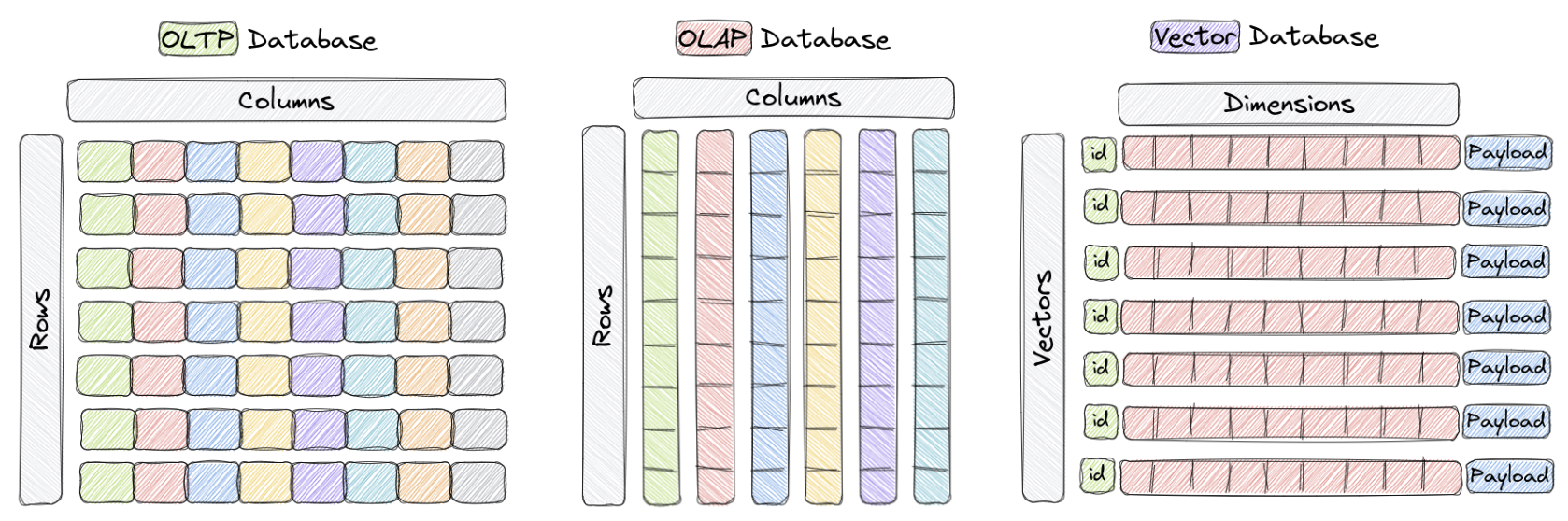
벡터 DB는 데이터를 고차원 수치로 표현한 벡터(embedding)를 저장하고, 입력된 벡터와 가장 유사한 벡터를 찾아주는 역할을 합니다. 자연어 처리, 이미지 검색, 추천 시스템에서 이 방식이 특히 빛을 발합니다.
예를 들어 사용자가 어떤 이미지를 업로드하면, 시스템은 해당 이미지를 벡터로 변환하고, 기존 이미지 벡터들과 비교해 가장 유사한 결과를 반환합니다. 이 모든 과정은 숫자 공간 내 거리 계산을 통해 이루어집니다.
Qdrant란 무엇인가?
Qdrant “is a vector similarity search engine that provides a production-ready service with a convenient API to store, search, and manage points (i.e. vectors) with an additional payload.”
Qdrant는 벡터 유사도 검색을 위한 검색 엔진입니다. 고차원 벡터 데이터를 저장하고 검색하며 관리할 수 있는 API 기반의 서비스로, 실시간으로 벡터 유사도 검색이 가능한 프로덕션 레벨의 솔루션입니다.
특히 Qdrant는 각 벡터에 부가 정보를 담을 수 있는 ‘Payload’ 기능을 지원합니다. 이로써 단순한 유사도 검색을 넘어, 유의미한 필터링과 메타데이터 기반의 조건 검색까지 가능합니다.
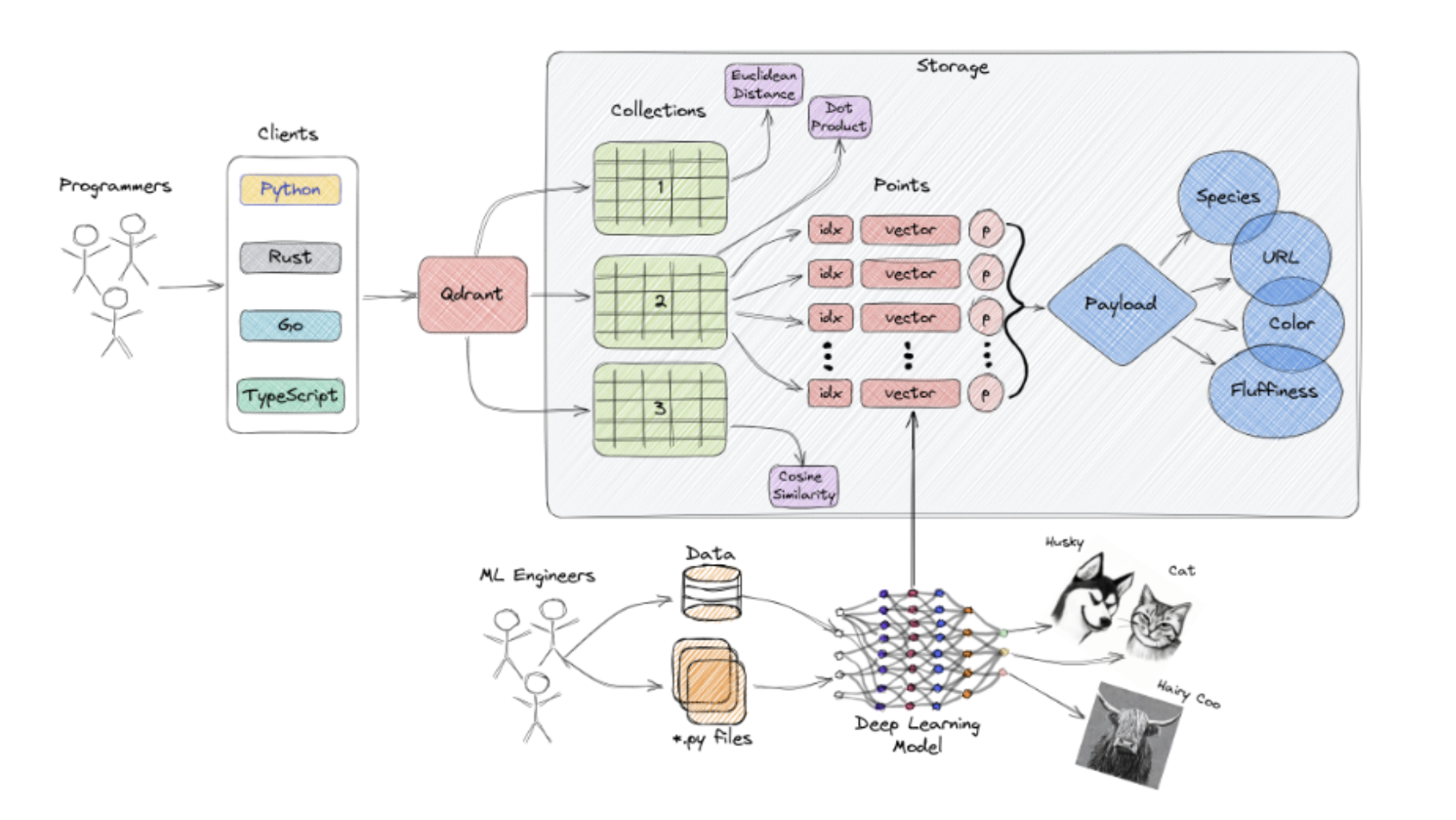
Qdrant의 핵심 아키텍처 구성 요소
- Collection: 벡터 데이터들을 저장하는 단위입니다.
같은 Collection 내의 벡터는 동일한 차원을 가지며 동일한 거리 측정 방식(metric)을 사용합니다. - Point: Qdrant의 핵심 단위로, 하나의 벡터와 그에 대한 고유 ID, 그리고 부가 정보를 담고 있는 payload로 구성됩니다.
- Vector: 문서, 이미지, 음성 등 데이터를 고차원 수치로 표현한 결과물입니다.
- Payload: 벡터와 함께 저장되는 JSON 형태의 추가 데이터입니다. 예를 들어 문서 제목, 카테고리, 작성자 등 메타 정보를 포함할 수 있습니다.
- Distance Metric: 벡터 간 유사도를 계산하는 방식입니다. Qdrant는 다음 세 가지 방식을 지원합니다.
1. Cosine Similarity: 방향 기준 유사도 측정 (값 범위: -1 ~ 1)
Cosine similarity is a way to measure how similar two vectors are. To simplify, it reflects whether the vectors have the same direction (similar) or are poles apart. Cosine similarity is often used with text representations to compare how similar two documents or sentences are to each other. The output of cosine similarity ranges from -1 to 1, where -1 means the two vectors are completely dissimilar, and 1 indicates maximum similarity.
2. Dot Product: 벡터 길이와 방향 모두 고려
Unlike cosine similarity, it also considers the length of the vectors. The dot product similarity is calculated by multiplying the respective values in the two vectors and then summing those products. The higher the sum, the more similar the two vectors are.
3. Euclidean Distance: 유클리드 거리 계산 방식 (거리 기반, 값이 작을수록 유사)
Euclidean distance is a way to measure the distance between two points in space, similar to how we measure the distance between two places on a map. It’s calculated by finding the square root of the sum of the squared differences between the two points’ coordinates. This distance metric is also commonly used in machine learning to measure how similar or dissimilar two vectors are.
- Storage
- In-memory 저장: RAM을 활용해 속도가 빠름
- Memmap 저장: 디스크 기반 가상 메모리 방식
Qdrant 주요 특징과 장점
1. 고차원 벡터 검색 최적화: HNSW(Hierarchical Navigable Small World) 기반의 인덱싱 구조를 통해 빠른 유사도 검색이 가능합니다.
2. Payload 기반 필터링 지원: 단순한 거리 계산 이상의 조건 검색이 가능해 다양한 응용이 가능합니다.
3. 간단한 API 설계: REST API 및 gRPC를 통한 직관적인 인터페이스 제공.
4. 다양한 클라이언트 언어 지원: Python 외에도 다양한 언어에서 사용할 수 있도록 클라이언트 제공.
5. 실시간 검색 성능: 수백만 개의 벡터 중에서도 빠른 검색 응답 속도 제공.
6. 오픈소스 및 클라우드 지원: 온프레미스 및 클라우드 환경 모두에서 유연하게 운영 가능.
