문제점
발견된 문제점
JPA를 활용하면 테이블 구조에 대한 고민을 자바 코드에선 하지 않고 객체간의 관계로써만 코드를 작성할 수 있도록 기능을 지원해준다는 장점이 있습니다.
저는 JPA를 가지고 연관관계를 가진 엔티티 객체들 간의 정보를 일대다 혹은 다대다 관계를 가질 수 있도록 List 자료구조에 저장함으로써 필요에 따라 쿼리문에 대한 고민 없이 연관관계 객체의 정보를 조회할 수 있도록 구현해보고자 했습니다.
하지만 이로 인해 서비스 성능에 매우 큰 문제를 야기할 수 있는 구조로 작성된 코드를 발견했고 그러한 문제를 N+1 쿼리라고 불리고 있었습니다.
N+1 쿼리란?
N+1 쿼리란 연관 관계에서 발생하는 이슈로 연관 관계가 설정된 엔티티를 조회할 경우에 조회된 데이터 갯수(n) 만큼 연관관계의 조회 쿼리가 추가로 발생하여 데이터를 읽어오게 되면서 추가적인 오버헤드가 발생하는 현상을 의미합니다.
N+1 쿼리 발생 코드
우선 N+1 쿼리가 발생한 엔티티 객체로 Participant 클래스입니다. 아래 코드에서도 볼 수 있듯이 Channel과 User 클래스와 연관관계를 가진 구조로 구성되어 있습니다.
Participant 클래스(엔티티)
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@Builder
@Entity
@Table(name = "participant")
public class Participant {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private int id;
// 연관관계를 가지는 필드
@ManyToOne
@JoinColumn(name = "channel_id", referencedColumnName = "id")
private Channel channel;
@OneToOne
@JoinColumn(name = "user_id", referencedColumnName = "id")
private User user;
/**
* 매니저가 초대한 참가자 객체들을 담을 리스트 객체 생성 메소드.
*/
public static List<Participant> listOf() {
return new ArrayList<>();
}
}
해당 엔티티 객체에 대한 N+1 쿼리는 사용자들 간의 메세지 전송 메소드에서 발생했습니다. 생성된 메세지를 전송하기 위해 그 대상이 되는 userId를 조회해야 했는데 그 과정은 다음과 같습니다.(message 객체 생성 과정은 생략했습니다.)
- 메세지가 전송될 channelId를 가진 participant 객체들을 조회
- 각 participant 객체 저장된 user 필드의 id 값을 조회
ChatServiceImpl 클래스
@Override
@Transactional
public void sendMessage(int channelId, int sendUserId, String content) {
// message 객체에 주입할 channel 정보 조회
Channel channel = findChannelById(channelId);
// message 객체에 주입할 user 정보를 조회
User user = userService.findById(sendUserId);
Message message = Message.builder()
.type(Type.MESSAGE)
.content(content)
.createAt(LocalDateTime.now())
.build();
messageRepository.save(message);
// user 정보 주입
message.setUser(user);
// channel 정보 주입
message.setChannel(channel);
// 1)
// 해당 채팅방에 메세지를 받아야하는 대상자를 조회 -> N+1 쿼리 발생 지점!!
List<Integer> userIdList = findMessageReceivers(channelId);
// 조회된 user들에 대해 메세지를 푸시
for (int receiveUserId : userIdList) {
if (receiveUserId != sendUserId) {
PushMessageCommand command = PushMessageCommand.builder()
.channelId(channelId)
.sendUserId(sendUserId)
.receiveUserId(receiveUserId)
.content(content)
.build();
chatPushService.pushMessage(command);
}
}
}
@Override
@Transactional(readOnly = true)
public Channel findChannelById(int channelId) {
Optional<Channel> channel = channelRepository.findById(channelId);
if (channel.isEmpty()) {
throw new RuntimeException("채팅방 정보가 존재하지 않습니다.");
}
return channel.get();
}
@Override
@Transactional
public List<Integer> findMessageReceivers(int channelId) {
List<Integer> userIdList = new ArrayList<>();
List<Participant> participants = findParticipantsByChannelId(channelId);
for (Participant participant : participants) {
// 2)
// participant 객체에 저장된 User 객체를 사용하기 위해 N번의 쿼리문 발생
userIdList.add(participant.getUser().getId());
}
return userIdList;
}
@Override
@Transactional(readOnly = true)
public List<Participant> findParticipantsByChannelId(int channelId) {
return participantRepository.findAllByChannelId(channelId);
}결국 지연로딩으로 인해 각 participant에 저장된 user객체에 대한 정보를 조회하는 것을 사용 시점으로 미뤄졌고 userId에 대한 조회가 발생하는 시점에서 추가적인 쿼리문이 발생하는 것을 확인할 수 있었습니다.
APM으로 확인한 N+1쿼리

ElasticSearch로 로직 실행 과정을 모니터링해보면 앞서 말씀드린 코드에서 N개의 반복적인 쿼리문이 발생한 것을 확인했고 이에 대한 해결책을 마련할 필요성을 느낄 수 있었습니다.
해결방안
1. 외래키 컬럼을 필드값으로 지정
제목 그래도 테이블 구조와 동일하게 객체 구조를 구성하는 방법으로 해결하는 방법입니다. Participant 객체는 User에 대한 정보를 연관관계로써 가지지 않고 userId값에 대해서만 int 타입으로 저장한다면 위에서처럼 user 객체를 DB에서 조회하기 위한 추가적인 쿼리문은 생성되지 않을 것입니다.
수정한 Participant 객체
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@Builder
@Entity
@Table(name = "participant")
public class Participant {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private int id;
// userId 값만 필드로 구성
@Column(name = "user_id")
private int userId;
@ManyToOne
@JoinColumn(name = "channel_id", referencedColumnName = "id")
private Channel channel;
/*
* 연관관계 필드는 주석처리
@OneToOne
@JoinColumn(name = "user_id", referencedColumnName = "id")
private User user;
*/
/**
* 매니저가 초대한 참가자 객체들을 담을 리스트 객체 생성 메소드.
*/
public static List<Participant> listOf() {
return new ArrayList<>();
}
}수정된 ChatServiceImpl 클래스
// 생략
@Override
@Transactional
public List<Integer> findMessageReceivers(int channelId) {
List<Integer> userIdList = new ArrayList<>();
List<Participant> participants = findParticipantsByChannelId(channelId);
for (Participant participant : participants) {
// -> 연관관계를 가지기 보단 userId를 컬럼으로 가져오는 방법을 선택함으로써 N+1 쿼리 발생을 방지
userIdList.add(participant.getUserId());
}
return userIdList;
}하지만 이와같은 엔티티 클래스 구조는 JPA가 제공해주는 기능의 장점을 오히려 활용하지 못하고 테이블 패러다임에 의존하는 객체 구조가 된다고 생각합니다.
또한 현재는 userId에 대한 필요성만 존재해 해결책으로 제시될 수 있더라고 이후 Participant를 통해 User의 여러 데이터를 호출해야 하는 경우에는 쿼리문이 추가로 발생할 수 밖에 없어 여러 클래스의 코드를 수정해야 하는 소요(OCP에 위반되는 상황)도 발생할 수 있다고 판단되어 다른 방법을 찾아야 한다고 생각했습니다.
2. Fetch Join
첫번 째 해결책에서 나오는 문제점을 해결하기 위해 적용해본 방법은 Fetch Join 조건을 추가하는 것이였습니다.
Fetch Join은 일반 Join과는 다르게 from 뒤에 오는 대상 엔티티와 함께 Fetch Join으로 지정된 엔티티를 포함해 함께 Select 해오는 특징이 있습니다.
- 일반 Join : join 조건을 제외하고 실제 질의하는 대상 Entity에 대한 컬럼만 SELECT
- Fetch Join : 실제 질의하는 대상 Entity와 Fetch join이 걸려있는 Entity를 포함한 컬럼 함께 SELECT
Fetch Join을 이용한다면 Participant 객체들을 조회해오는 과정에서 연관관계를 가진 User 객체들도 함께 조회해올 수 있고, 그렇다면 User 객체의 정보를 호출하는 과정에서 추가적인 쿼리문이 생성되지 않을 수 있습니다.
Fetch Join 쿼리문이 추가된 ChatRepository
@Repository
public interface ParticipantRepository extends JpaRepository<Participant, Integer> {
Participant save(Participant participant);
@Override
<S extends Participant> List<S> saveAll(Iterable<S> entities);
Optional<Participant> findById(Participant participant);
// 직접 JPQL을 작성해 해당 로직에 대한 조건을 수동으로 설정
@Query("SELECT p FROM Participant p WHERE p.channel.id = :channelId")
List<Participant> findAllByChannelId(@Param(value = "channelId") int channelId);
}위 코드처럼 JpaRepository를 implements 하고 있는 Repository 레이어의 인터페이스에 선언된 N+1쿼리를 발생시키는 메소드에 @Query 어노테이션을 추가해주고 직접 JPQL문을 문자열로 선언해줍니다.
이후 1번 해결방안에서 주석처리한 코드를 원래대로 돌려준 다음, 메세지 전송 로직을 수행시켜본다면 아래 사진처럼 APM을 통해 N+1 쿼리가 발생하지 않고 하나의 쿼리문만 생성되는 것을 확인할 수 있습니다.
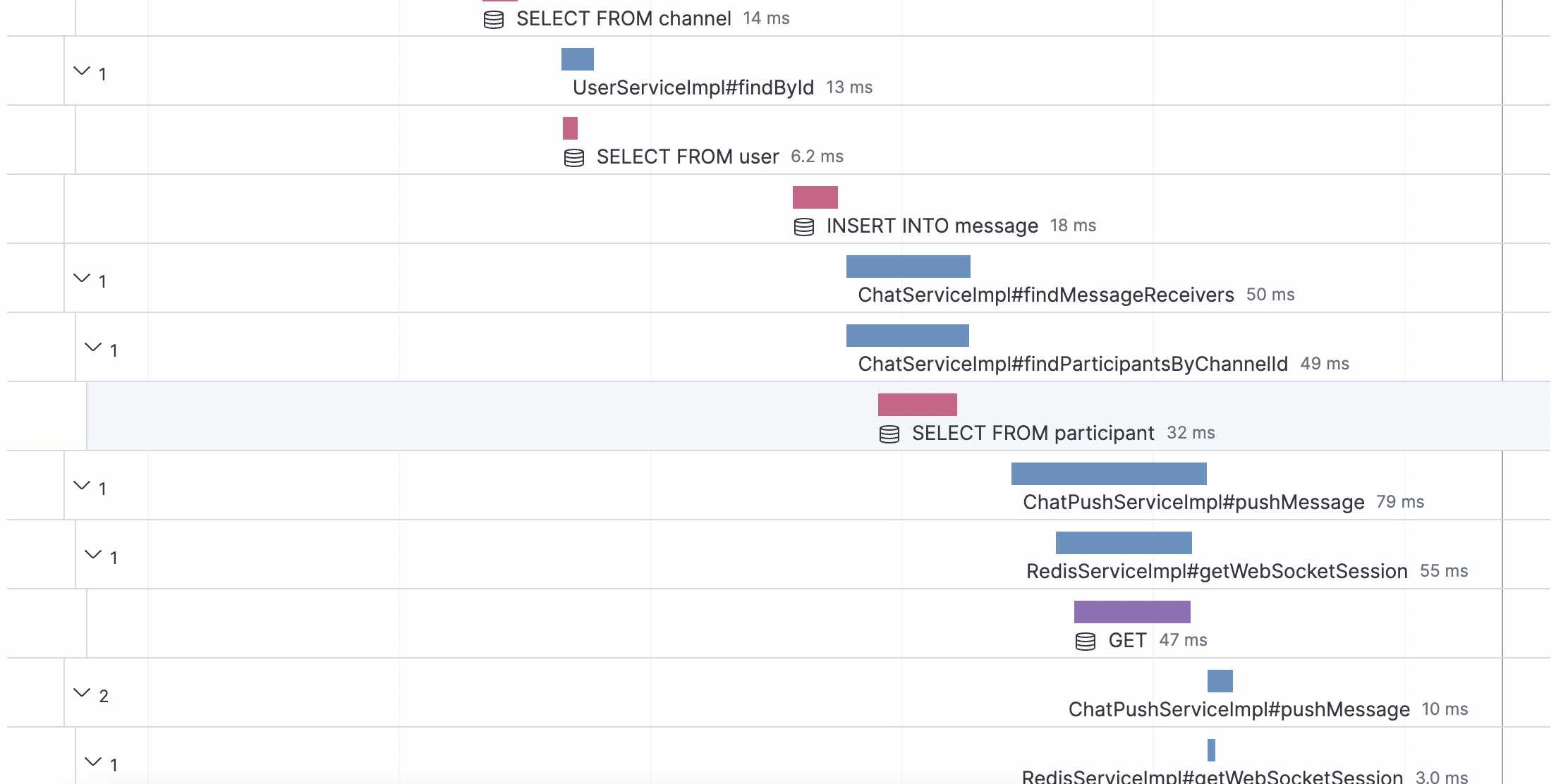
하지만 직접 Fetch Join문을 JPQL에 작성해주는 것은 JPA의 기능을 활용한다기 보단 개발자에게 책임이 있다고 볼 수 있습니다. 또한 JPQL문에 직접 Fetch Join을 선언해주었기 때문에 이후 FetchType에 대한 조건을 LAZY로 걸어주고 싶은 경우, 이미 join된 JPQL문으로 인해 EAGER로 밖에 선언할 수 없다는 단점이 있습니다.
3. @EntityGraph
이러한 문제를 해결해볼 수 있는 방법이 @EntityGraph 어노테이션을 활용하는 것입니다. 이러한 방법은 같은 동작을 하지만 JPA에서 제공해주는 FetchType에 대한 설정값도 함께 활용할 수 있고, 하드코딩으로 인한 위험도도 줄여볼 수 있습니다.
ParticipantRepository(JpaRepository 상속 클래스)
@Repository
public interface ParticipantRepository extends JpaRepository<Participant, Integer> {
Participant save(Participant participant);
@Override
<S extends Participant> List<S> saveAll(Iterable<S> entities);
Optional<Participant> findById(Participant participant);
// Fetch Join 대상이 되는 필드명을 attributePaths로 지정
@EntityGraph(attributePaths = "user")
@Query("SELECT p FROM Participant p WHERE p.channel.id = :channelId")
List<Participant> findAllByChannelId(@Param(value = "channelId") int channelId);
}그러나 Fetch Join으로 쿼리문을 하나로 줄여냈다고 해도 결국 사용하지 않는 연관객체의 다른 필드값까지 전부 조회해 오면서 조회할 개체수가 많아지면 많아질수록 로직의 성능은 낮아질 수 밖에 없었습니다.
그래서 외래키에 대한 값을 그대로 가지는 필드와 필요에 따라 연관관계 객체를 조회할 수 있는 구조로 엔티티 클래스를 설계할 수 있는 방법은 무엇이 있을지 찾아보게 되었습니다.
4. insertable = false, updatable = false
insertable 과 updatable은 @JoinColumn에 변수 중 하나로 연관관계 객체가 insert 혹은 update할 때 DB의 저장될 대상으로 포함시킬지 여부에 대한 설정을 할 수 있는 변수입니다.
즉, 연관관계 객체에 insertable과 updatable을 false로 설정해두면 연관관계 객체가 필드값에 포함되어 있지 않아도 DB에 데이터를 저장 및 수정할 수 있도록 구성할 수 있습니다. 대신 외래키에 대한 값을 저장할 일반 변수를 추가로 선언해 객체 생성시 외래키값만 지정해주면 DB에는 무리없이 저장할 수 있습니다.
- insertable : 엔티티 저장시 이 필드도 같이 저장한다. false로 설정하면 데이터베이스에 저장하지 않는다. 읽기 전용일때 사용한다.
- updatable : 위와 동일한 하지만 수정일때 해당 된다.
수정한 Participant 엔티티 클래스
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@Builder
@Entity
@Table(name = "participant")
public class Participant {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private int id;
// 외래키를 저장할 필드 추가
@Column(name = "channel_id", updatable = false)
private int channelId;
// 외래키를 저장할 필드 추가
@Column(name = "user_id", updatable = false)
private int userId;
@ManyToOne
@JoinColumn(name = "channel_id", referencedColumnName = "id",
insertable = false, updatable = false) // DB에 저장, 수정 시 필요한 데이터 대상에서 제외
private Channel channel;
@OneToOne
@JoinColumn(name = "user_id", referencedColumnName = "id",
insertable = false, updatable = false) // DB에 저장, 수정 시 필요한 데이터 대상에서 제외
private User user;
}위에서 설명한대로 외래키 값을 저장할 필드를 추가하고 연관관계 객체에는 insertable과 updatable을 false로 설정해 insert, update 쿼리문의 대상에서 제외시켰습니다. 이후, 조회의 경우에만 해당 객체에 대한 쿼리문이 생성됩니다.
수정된 ChatServiceImpl 클래스
@Slf4j
@Service
@RequiredArgsConstructor
public class ChatServiceImpl implements ChatService {
// 생략
@Override
@Transactional
public void sendMessage(int channelId, int sendUserId, String content) {
Message message = Message.builder()
.type(Type.MESSAGE)
.content(content)
.createAt(LocalDateTime.now())
.channelId(channelId) // 연관객체를 조회하지 않고 외래키 값을 그대로 저장
.userId(sendUserId) // 위와 동일
.build();
messageRepository.save(message);
List<Integer> userIdList = findMessageReceivers(channelId); // 호출 메소드 변경
for (int receiveUserId : userIdList) {
if (receiveUserId != sendUserId) {
PushMessageCommand command = PushMessageCommand.builder()
.channelId(channelId)
.sendUserId(sendUserId)
.receiveUserId(receiveUserId)
.content(content)
.build();
chatPushService.pushMessage(command);
}
}
}
@Override
@Transactional(readOnly = true)
public List<Integer> findMessageReceivers(int channelId) {
return participantRepository.findAllUserIdByChannelId(channelId); // userId 컬럼만 리스트로 조회하는 메소드 구현
}
// 이전에 호출되던 메소드
@Override
@Transactional(readOnly = true)
public List<Participant> findParticipantsByChannelId(int channelId) {
return participantRepository.findAllByChannelId(channelId);
}
}
message 수신자 대상 회원들의 userId를 조회하기 위해 호출되는 메소드도 변경되었습니다. (fetch join을 사용하지 않는 메소드를 호출)
추가적인 엔티티 클래스 구조 변경 이후 특정 엔티티 객체를 생성하는 과정에서도 연관객체를 조회하기 위한 쿼리문이 발생하는 로직이 필요하지 않고 외래키 필드에 직접 데이터를 저장하는 구조로 변경되었습니다.
메소드가 추가된 ParticipantRepository 클래스
@Repository
public interface ParticipantRepository extends JpaRepository<Participant, Integer> {
Participant save(Participant participant);
@Override
<S extends Participant> List<S> saveAll(Iterable<S> entities);
Optional<Participant> findById(Participant participant);
@EntityGraph(attributePaths = "user")
@Query("SELECT p FROM Participant p WHERE p.channel.id = :channelId")
List<Participant> findAllByChannelId(@Param(value = "channelId") int channelId);
// userId만을 조회하는 JPQL문을 작성
@Query("SELECT p.userId FROM Participant p WHERE p.channel.id = :channelId")
List<Integer> findAllUserIdByChannelId(@Param(value = "channelId") int channelId);
}이제 fetch Join을 사용하지 않고 userId에 대한 조회만 하는 메소드를 구현해 쿼리문의 복잡성을 줄일 수 있었습니다.
마치며
이번 케이스처럼 일대일 관계에서도 반복문을 통해 여러 개체를 조회하는 로직에서도 N+1쿼리의 문제는 야기될 수 있었지만, 대부분의 경우 일대다 관계를 가진 객체에 대한 호출을 하는 과정에서도 같은 문제가 발생할 수 있을 것이라 생각됩니다.
JPA가 Spring에 DB 연동과 관련된 여러 문제점과 반복 코드를 줄여주고 객체 지향 관점에서의 설계를 도와주는 장점이 있지만, 자동으로 쿼리문을 생성해주는 과정속에서 개발자가 직접 통제할 수 없거나 발견하기 힘들 문제가 발생할 수 있다는 것을 느꼈고, 이를 통제하고 방지하기 위해 여러 고민을 해보고 직접 해결해보는 과정을 경험해봤다고 생각합니다.
참고자료
https://incheol-jung.gitbook.io/docs/q-and-a/spring/n+1#n+1
https://cobbybb.tistory.com/18
https://jforj.tistory.com/90
https://stay-hungry.tistory.com/21
