GPT Key idea
대규모 unsupuervised 데이터셋에 대해 language model을 학습시킨 후 특정 task에 맞는 supervised finetuning 진행
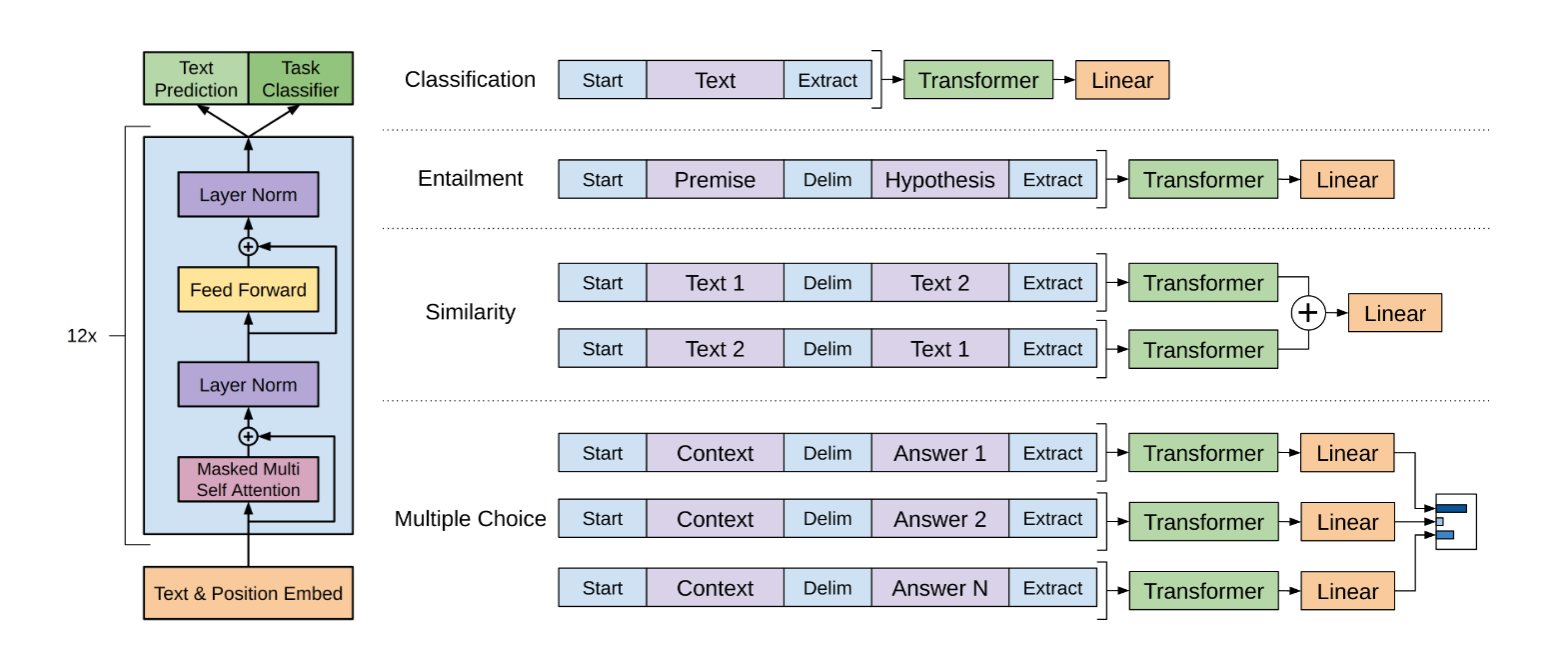
기존 transformer 모델에서 decoder만 갔다가 쌓아서 사용한다. 인코딩 과정에서 bpe사용한다.(oov 문제 때문에) 위치 정보에 대한 positional encoding도 당연히 입력으로 넣어줘야
language모델 학습은 단방향으로 이전 임베딩이 주어졌을 때 다음 단어 임베딩이 등장할 likelihood를 계산한다.
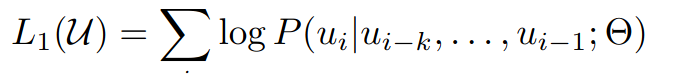
먼저 language model 학습시킨 후 supervised finetuning 과정에서 기존 language model과 finetuning model 모두에 대해서 손실함수 계산
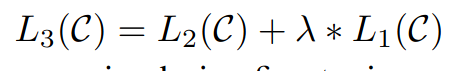
모델 구조

AI 개발자를 목표로 하고 있는 꿈 많은 공대생입니다. a deo vocatus rite paratus