2020 데이터 청년 캠퍼스(경기대)에서 학습한 내용을 간단하게 요약하였습니다.
2020.07.06 ~ 2020.07.10
인공지능 (Artificial Intelligence)
- 인간의 학습능력과 추론능력, 지각능력 등을 컴퓨터 프로그램으로 실현한 기술
- 입력값(Input)으로부터 결과값을 내는 함수를 만들어 내는 것
-> 결국 함수를 Training한다고 생각하면 될 듯 하다.
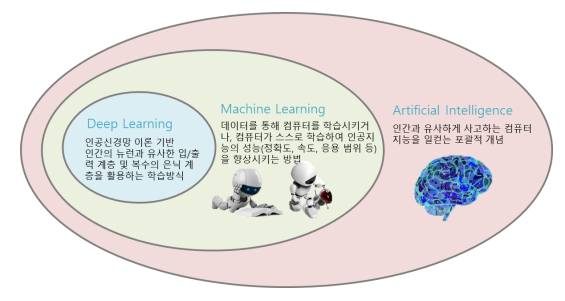
기계학습 (Machine Learning)
- 인공지능의 한 분야로 경험을 통해 자동으로 개선하는 컴퓨터 알고리즘의 연구
- 인간이 하나부터 열까지 다 가르치는 것이 아닌, 학습할 것을 일단 기계에 넘겨주면 이걸 가지고 스스로 학습하는 기계를 의미
- 데이터를 이용한 모델링 기법 : 모델링하기 어려운 문제에 주로 적용한다.
- 영상인식, 음성인식, 언어 이해 등 주로 지능과 관련
(ex) "고양이인가? 강아지인가?"
- 판별 모델 개발 : 사람의 기준은 경험적(직감적)이다. 명확한 정의가 불가능
- 이러한 경험적 기준을 -> 모델링화 -> Machine Learning - 완벽한 기계학습 알고리즘을 설계하는 것은 사실상 불가능에 가깝다.
다양한 기계학습(Machine Learning) 방법론
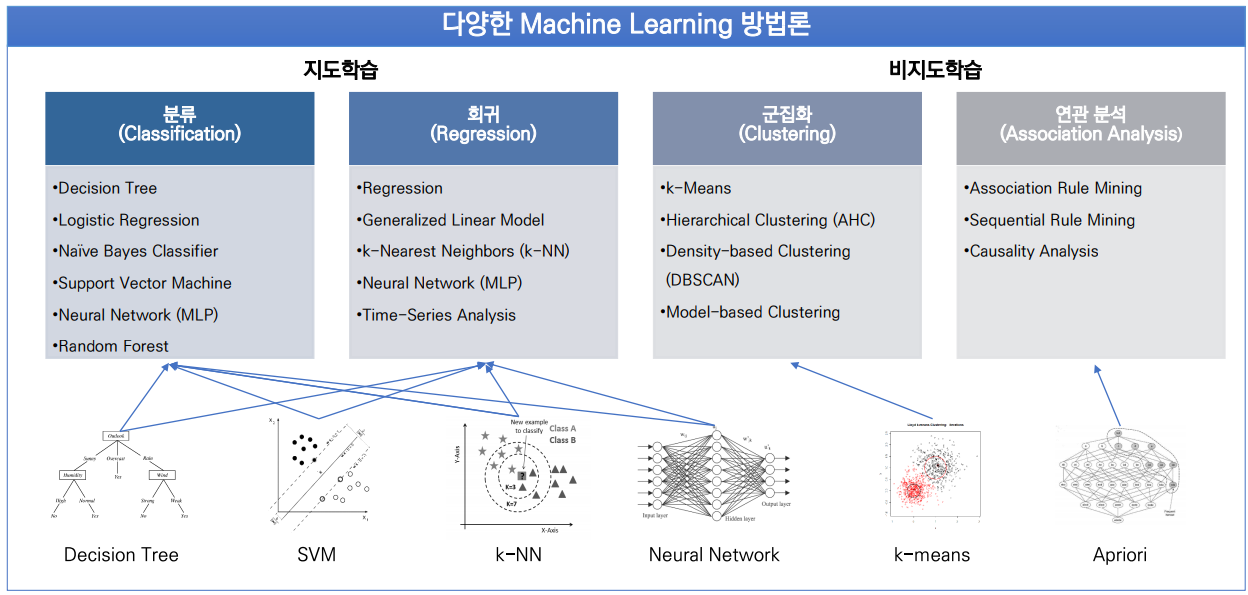
- + 기계학습의 기본 : 로지스틱 회귀(분류) / 회귀(회귀)를 공부해보자
기계학습 (Machine Learning)의 핵심요소
-
Feature Extraction (요인 추출) : 기존의 sample로부터 새로운 features(요인)을 추출 -> 이를 학습 model의 입력값으로 대신 사용 -> 예측 정확도를 효과적, 효율적으로 향상시키기 위함
- 학습 model의 성능에 엄청난 영향을 끼침 -> 거의 모든 ML 문제에서 Feature Extraction을 수행!
-
Loss Function (손실 함수) : 비용함수(Cost Function)라고도 함. 손실에는 그만큼의 비용이 발생한다는 개념에서 나옴

- 학습의 목적 : 주어진 데이터의 값과 Function이 예측한 값의 차이를 나타내는 손실 함수를 감소시키는 것
- 최적화 (Optimization) : 특정의 집합 위에서 정의된 실수값, 함수, 정수에 대해 그 값이 최대 or 최소가 되는 상태를 해석하는 문제
- 목적 : 복잡하고 넓은 해공간에서 지역최적해(Local optimal Solution)에 빠지지 않고 전역최적해(Global optimal solution)를 찾아갈 수 있게 한다.
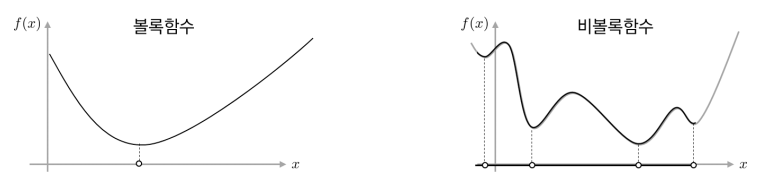
- 위 그림의 볼록함수(아래로 볼록) -> 간단하게 최적해를 구할 수 있음
- 위 그림의 비볼록함수 -> 최적해를 구하기 복잡함 (지역 최적해에 빠질 수도 있음)
★ 일반적으로 기계학습에서 모델의 성능은 손실함수를 최소화할 수록 -> 증가
★ 지역최적해에 빠져서 전역최적해를 찾지 못하는 것을 경계해야함
기계학습(Machine Learning)의 분류
-
1. 지도 학습 (Supervised Learning)
- 답은 미리 주어져있고, 틀린 값을 넣었을 때 그 값을 맞추는 것
- 모든 정보가 존재 (완벽한 학습 = 정답 데이터(레이블))
- Classification : 정해진 여러 개의 집단 중 하나로 판단
- Regression : 특정 값 맞추기
-
2. 비지도 학습 (Unsupervised Learning)
- 답이 주어져 있지 않음
- 정답에 대한 정보가 일부 존재 (불완전한 학습 데이터)
- 의미 있는 (정답과 가까울 것으로 생각되는) Y(반응 변수)값 도출
- Clustering : 관련이 있는, Density가 높은 것들끼리 묶어서 분류하는 것
-
3. 강화 학습 (Reinforcement Learning)
- 연속적인 의사결정 문제에서 최적의 의사결정을 하도록 학습
- 최적의 의사결정 --> DP를 Learning으로 풀려는 시도
- 매 순간 최고의 보상(reward)을 얻으려고 하는 궁극적인 목적을 가지고 있음
- (ex) 미로찾기, 구글 딥마인드의 알파고, 자동차 자율주행 등...
- 연속적인 의사결정 문제에서 최적의 의사결정을 하도록 학습
혼동 행렬 (Confusion Matrix)
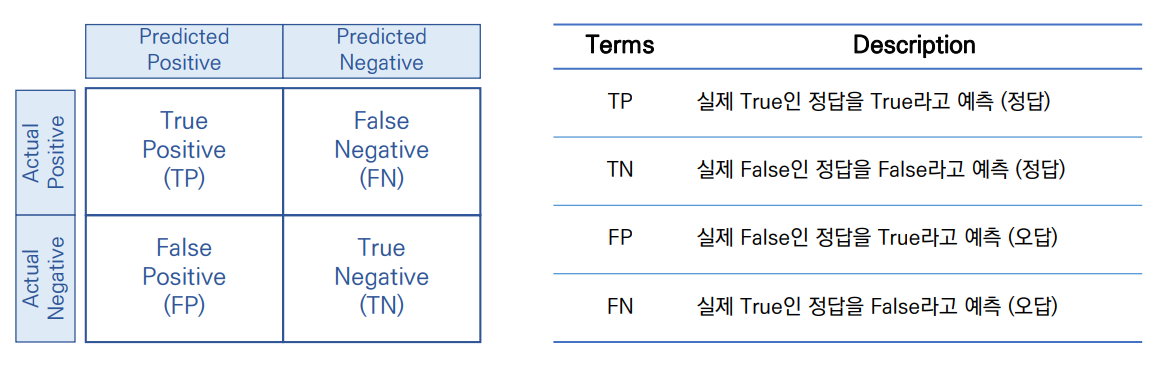
- 여기를 참고하자
- 가장 직관적으로 모델의 성능을 나타내는 척도
- 주어진 데이터를 올바르게 분류한 비율을 나타냄
- 분류기(Classifier)가 특정 dataset에 대해 산출하는 분류결과를 요약하는 역할
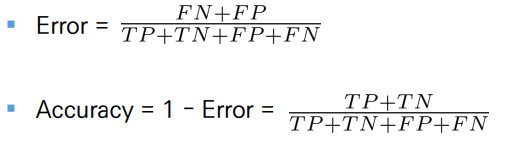
- 데이터가 불균형(imbalanced)한 상태에서는 Accurary로 모델의 성능을 판단할 수 없음 -> 아무 의미가 없음 // 너무 정확성에 의존하면 안됨
혼동 행렬과 Type1 & Type2 Errors

- False Negative (FN) : Type1 error
- False Positive (FP) : Type2 error
- 2개의 error는 서로 trade-off 관계
Precision & Recall
Precsion
- 모델이 True라고 분류한 것 중에, 실제로도 True인 것의 비율
When it predicts yes, how often is it correct?
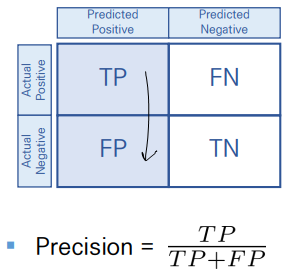
- Precision이 높으면 -> type2 error가 낮음
- (ex) 날씨를 맑다고 예측했을 때, 실제로도 맑은 날의 비율
Recall
- 실제 True인 것 중에, 모델이 True라고 분류한 것의 비율
When it's actually yes, how often does it predict yes?
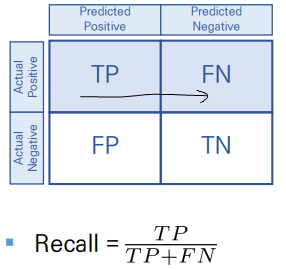
- Recall이 높으면 -> type1 error가 낮음
- (ex) 실제로 맑은 날 중에, 모델이 맑다고 예측한 비율
Precision과 Recall의 관계
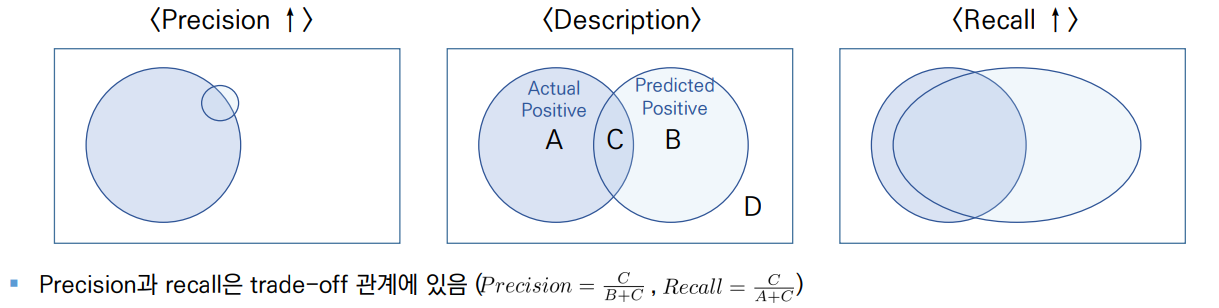
- Precision을 높이는 극단적인 방법
- 확실한 True인 소수를 제외하고 모두 False로 분류 (C낮추고, B낮추고) -> Precision 증가, Recall 감소 (B의 감소량 매우 큼) - Recall을 높이는 극단적인 방법
- 대부분의 Data에 대해서 True로 분류 (A낮추고, B높이고, C높이고) -> Recall 증가, Precision 감소 (A+C의 값은 일정)
F1 score
- Precision과 Recall의 조화평균
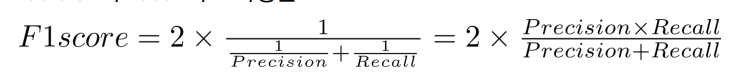
- 데이터의 label이 불균형(imbalance)이 심한 경우에도, 모델의 성능을 정확하게 평가할 수 있음. Precision과 Recall의 성능을 전부 다 고려해줌
- 성능을 하나의 숫자로 표현 가능
굳이 조화평균을 사용하는 이유는 무엇일까? 아래의 그림을 보자.
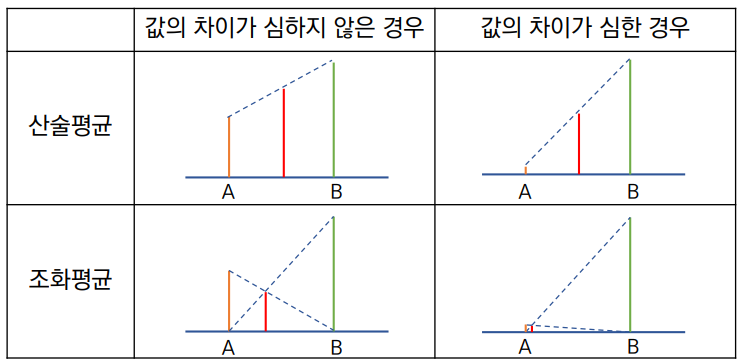
- 지표들의 값의 차이가 큰 경우 -> 산술평균은 값이 작은 지표의 성능을 고려하지 못함
- But, 조화평균은 지표의 값의 크기로 인한 bias의 영향을 감소시킴
기계학습(Machine Learning) Validation

- Validation set은 기계학습 또는 통계에서 기본적인 개념 중 하나
★ Data를 Training, test 2개의 데이터로 나누지 않고 굳이 Validation set까지 3개로 나누는 이유는 무엇일까...
-> 모델의 성능을 평가하기 위해 Validation set을 사용한다.
-> Training의 일부를 모델의 성능을 평가하기 위해 희생 But 위 희생을 감수하지 못할만큼 Data의 크기가 작다면 cross-validation이라는 방법을 사용하기도 함
Training Data Set
- 모델의 파라미터를 정하기 위해 사용되는 data set
- Underfitting을 해결
Validation Data Set
- 모델의 성능을 평가하기 위해 사용하는 data set
- Overfitting을 방지하기 위해 사용됨 (주된 목적)
Test Data Set
- 모델의 최종 성능을 평가하기 위해 사용됨
- Training 과정에 관여하지 않음
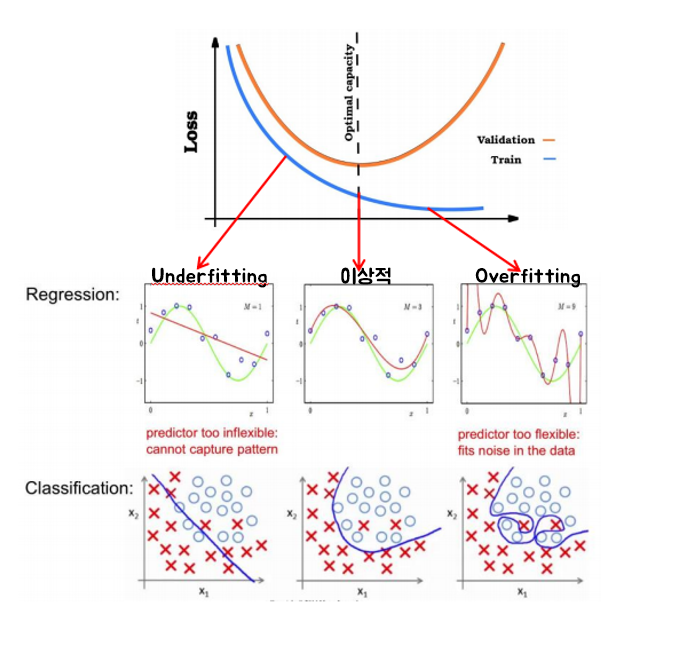
- 시간이 지나면 Train Loss Function 값은 계속 감소하게 됩니다.
- 어느 순간 Validation Loss Function 값은 증가하게 됩니다.
인공신경망(Artificial Neural Network)
- 인공지능의 한 분야로 생물학(인간)의 뇌 구조(신경망)을 모방하여 모델링한 수학적 모델
- 인간의 뇌가 문제를 해결하는 방식과 유사하게 구현한 것으로, 신경망은 각 신경세포가 독립적으로 동작하기 때문에 병렬성이 뛰어남
- 많은 연결선에 정보가 분산되어 있어, 몇몇의 신경세포에 문제가 발생해도 전체에 큰 영향을 주지 않음 -> 오류가 강함
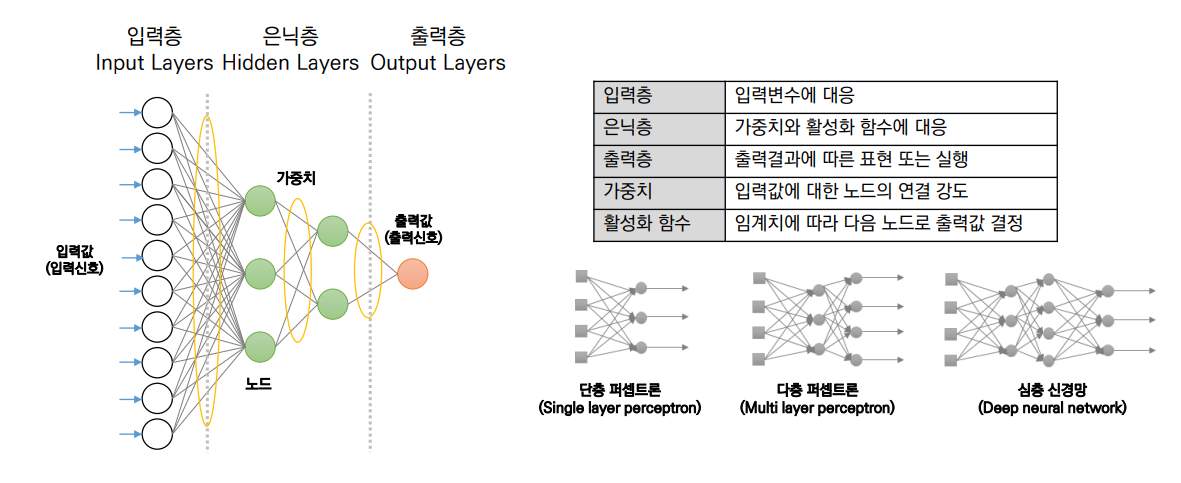
- 은닉층=1 : 단층 퍼셉트론
- 은닉층=2 : 다층 퍼셉트론
- 은닉층>2 : 심층 신경망
Deep Learning
- 컴퓨터가 스스로 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 머신러닝 방법의 한 종류로, 인간의 뇌가 작용하는 방식과 동일하게 컴퓨터가 학습하여 결과물을 산출하는 것을 의미
- 인공신경망(ANN)의 다층 구조가 심화된 알고리즘
- 컴퓨터에게 학습을 시키는 기계학습(Machine Learning)의 일종
- 여러 단계의 정보 표현과 추상화를 학습하는 (Neural network를 사용한) 최신 머신러닝 알고리즘의 총칭
- 데이터를 기반으로 학습하고 패턴을 찾아 사물을 분별할 수 있도록 성장
- (ex) CNN(Convolutional Neural Network), RNN(Recurrent Neural Network)
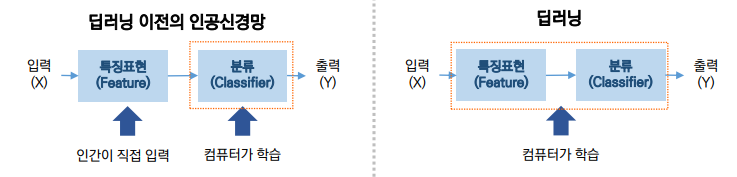
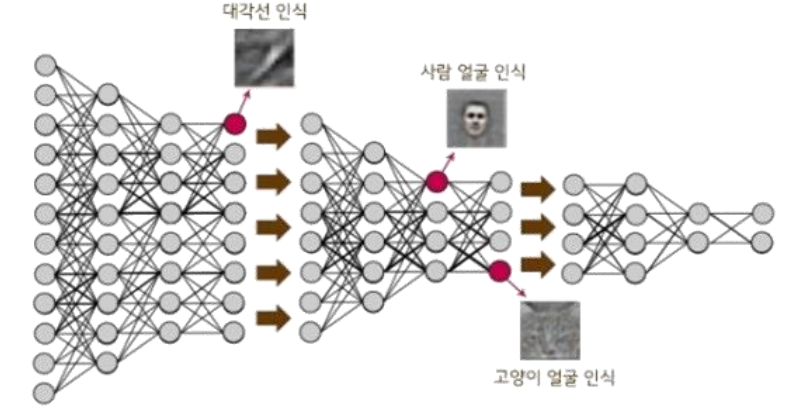
- 수많은 데이터 속에서 패턴을 발견 -> 객체를 분별
- 초기에는 단순하게 선 or 색만 구별한다면, 나중에는 모양을 인식하고 추상적인 레벨까지 구분할 수 있게 학습시킴
<문제점>
- 자세한 설명이 부족, 근거가 없음. 따라서 금융권 같은 곳에서는 딥러닝을 내세우는 경우는 없음
- 딥러닝은 신경망의 구조가 쌓일수록 학습은 강화되나, 가중치 문제가 발생
- 엄청나게 많은 데이터가 필요하다. (데이터를 직접 만들어야 하는 경우도 발생)
