정규표현식 정리
정규표현식에서는 메타 문자(meta characters)를 사용한다. 메타 문자에는 아래와 같다.
※ 메타 문자란? 원래 그 문자가 가진 뜻이 아닌 특별한 용도로 사용하는 문자를 의미한다.
. ^ $ * + ? { } [ ] \ | ( )
정규표현식에 위 메타 문자를 사용하면 특별한 의미를 갖게 된다. 이번 시간에 알아보도록 하자.
1. 문자 클래스 []
'[] 사이의 문자들과 매치'라는 의미를 가진다.
※ 문자 클래스를 만드는 메타 문자 [] 사이에는 어떤 문자도 들어갈 수 있다!
(Ex)
[abc]:= a,b,c 중 한개의 문자와 매치를 의미한다.
a --> 정규식과 일치하는 문자인 'a'가 있으므로 매치 O
before --> 정규식과 일치하는 문자인 'b'가 있으므로 매치 O
ddr --> a,b,c 중 하나라도 포함하고 있지 않으므로 매치 X
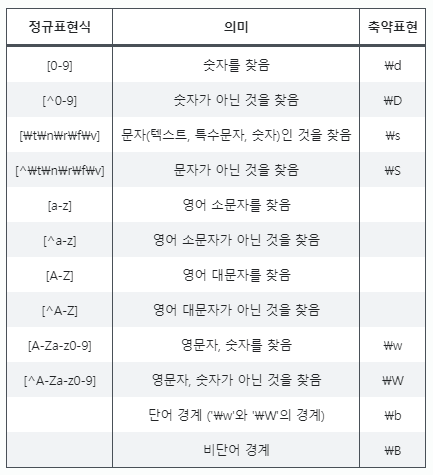
[]클래스를 표로 정리하면 아래와 같다.
| 정규표현식 | 의미 | 축약표현 |
|---|---|---|
| [0-9] | 숫자를 찾음 | \d |
| [^0-9] | 숫자가 아닌 것을 찾음 | \D |
| [\t\n\r\f\v] | 문자(텍스트, 특수문자, 숫자)인 것을 찾음 | \s |
| [^\t\n\r\f\v] | 문자가 아닌 것을 찾음 | \S |
| [a-z] | 영어 소문자를 찾음 | |
| [^a-z] | 영어 소문자가 아닌 것을 찾음 | |
| [A-Z] | 영어 대문자를 찾음 | |
| [^A-Z] | 영어 대문자가 아닌 것을 찾음 | |
| [A-Za-z0-9] | 영문자, 숫자를 찾음 | \w |
| [^A-Za-z0-9] | 영문자, 숫자가 아닌 것을 찾음 | \W |
| 단어 경계 ('\w'와 '\W'의 경계) | \b | |
| 비단어 경계 | \B |
표를 보면 ^는 '~이 아닌'을 의미하고, ^로 인해 서로 반대되는 의미의 축약표현은 대소문자로 구별됨을 알 수 있다.
2. Dot(.)
'Dot(.)은 줄바꿈 문자인 \n을 제외한 모든 문자와 매치됨'을 의미한다.
※ 정규표현식을 쓸 때 re.DOTALL 옵션을 주면 \n 문자와도 매치된다.
(Ex)
a.b:= "a + 모든문자 + b" , 즉 a와 b라는 문자 사이에 어떤 문자가 들어가도 모두 매치된다는 의미
aab --> a와 b사이에 a가 있으므로 정규식과 매치 O
a0b --> a와 b사이에 0이 있으므로 정규식과 매치 O
abc --> a와 b사이에 어떤 문자가 없으므로 매치 X
혼동 주의!
(Ex2)
a[.]b:= "a + Dot(.)문자 + b"
위 정규식 예제와 달리[]내에Dot(.)메타 문자가 사용되면 문자.그대로를 의미한다. ("모든 문자"라는 의미가 아니다!)
a.b --> a와 b사이에.있으므로 정규식과 매치 O
a0b, aab, abc --> a와 b사이에.이 없으므로 정규식과 매치 X
3. 반복 (*)
예제를 보면서 설명하겠다. *은 * 바로 앞에 있는 문자가 0부터 무한대로 반복될 수 있다는 의미이다.
※ 여기서 무한대라고 했는데 사실상 메모리 제한으로 2억개 정도까지라고 한다.
(Ex)
ca*t:=*바로 앞에 있는 문자 a가 0부터 무한대로 반복될 수 있다는 의미이다.
ct --> a가 0번 반복되어 매치 O
cat --> a가 1번 반복되어 매치 O
caaat --> a가 3번 반복되어 매치 O
4. 반복 (+)
+는 최소 1번 이상 반복될 때 사용한다. (*는 최소 반복 횟수가 0부터라면, +는 반복 횟수가 1부터 이다.)
(Ex)
ca+t:= "c + a(1번 이상 반복) + t"
ct --> a가 0번 반복되어 매치 X (1번 이상 반복되어야함)
cat --> a가 1번 반복되어 매치 O
caaat --> a가 3번 반복되어 매치 O
5. 반복 ({m,n}, ?)
{m,n}은 반복을 고정 및 제한할 때 사용한다. {m, n} 정규식을 사용하면 반복 횟수가 m부터 n까지 매치할 수 있다. 또한, m 또는 n을 생략할 수도 있다.
{3,}이면 반복 횟수가 3이상인 경우이고, {,3}이면 반복 횟수가 3이하를 의미한다. 즉, m은 0과 동일하며, 생략된 n은 무한대(2억 개 미만)의 의미를 갖는다.
※ {1,}은 +와 동일하고, {0,}은 *와 동일하다.
(Ex)
ca{2,5}t:= "c + a(2~5회 반복) + t"
cat --> a가 1번만 반복되어 매치 X
caat --> a가 2번 반복되어 매치 O
caaaaat --> a가 5번 반복되어 매치 O
?은 '있어도 되고 없어도 된다'라는 의미를 가지고 있다.
(Ex2)
ab?c:= "a+b(있어도 되고 없어도 된다) + c"
abc --> b가 1개 있어서 매치 O
ac --> b가 없어서 매치 O
Python에서 정규표현식 사용하기
import re
p = re.compile('ab*')위와 같이 Python에서는 정규표현식 지원 모듈인 re(regular expression) 모듈을 제공한다. re.compile을 사용하여 정규표현식(ab*)를 컴파일한다. re.compile의 결과로 돌려주는 객체 p(컴파일된 패턴 객체)를 사용하여 그 이후의 작업을 처리한다.
※ 패턴이란? 정규표현식을 컴파일한 결과를 의미한다.
정규표현식을 이용한 문자열 검색
컴파일된 패턴 객체를 사용하여 문자열 검색을 수행해보자. 컴파일된 패턴 객체는 아래와 같이 4가지의 메소드를 제공한다.
| Method | 목적 | 반환형 |
|---|---|---|
| match() | 문자열의 처음부터 정규표현식과 매치되는지 조사한다. | match 객체 |
| search() | 문자열 전체를 검색하여 정규표현식과 매치되는지 조사한다. | match 객체 |
| findall() | 정규표현식과 매치되는 모든 문자열(substring)을 리스트로 돌려준다. | List |
| finditer() | 정규표현식과 매치되는 모든 문자열(substring)을 반복 가능한(iterator) 객체로 돌려준다. | match 객체 |
match, search는 정규표현식과 매치될 때는 match 객체를 반환하고, 매치되지 않을 때는 None을 돌려준다.
1. match()
문자열의 처음부터 정규표현식과 매치되는지 조사한다. 아래 예제를 통해 알 수 있다.
import re
p = re.compile('[a-z]+')
m = p.match("python")
print(m)
>>> <re.Match object; span=(0, 6), match='python'>
# 'python' 문자열은 [a-z]+ 정규식에 부합되므로 match 객체를 돌려준다.
m = p.match("3 python")
print(m)
>>> None
# '3 python'은 '3' 때문에 [a-z]+ 정규식에 부합되지 않으므로 None을 돌려준다.match() 메소드는 결과를 match 객체 혹은 None을 반환하기 때문에 보통 아래와 같이 구현을 한다.
import re
p = re.compile('[a-z]+')
m = p.match('string goes here')
if m:
print('Match found: ', m.group())
else:
print('No match')2. search()
문자열 전체를 검색하여 정규표현식과 매치되는지 조사한다. 예제를 통해 이해해보자.
p = re.compile('[a-z]+')
m = p.search("python")
print(m)
>>> <re.Match object; span=(0, 6), match='python'>
# search 메소드를 수행하면 match와 동일한 결과형태가 나온다.
# 반면!
p = re.compile('[a-z]+')
m = p.search("3 python")
print(m)
>>> <re.Match object; span=(2, 8), match='python'>
# match와 다르게 search는 문자열의 처음부터가 아닌 전체를 검색하기 때문에 '3'이후 'python'의 문자열과 매치된다.
# search와 match의 차이라고 볼 수 있다.
3. findall()
정규표현식과 매치되는 모든 문자열(substring)을 리스트로 돌려준다. 아마 제일 많이 쓰이는 메소드가 아닐까 조심스럽게 생각한다.
p = re.compile('[a-z]+')
result = p.findall("life is too long")
print(result)
>>> ['life', 'is', 'too', 'long']
# life, is, too, short 단어를 각각 정규식과 매치해서 리스트로 돌려준다.4. finditer()
정규표현식과 매치되는 모든 문자열(substring)을 반복 가능한(iterator) 객체로 돌려준다.
p = re.compile('[a-z]+')
result = p.finditer("life is too long")
print(result)
>>> <callable_iterator object at 0x019D7A50>
for r in result: print(r)
>>> <re.Match object; span=(0, 4), match='life'>
<re.Match object; span=(5, 7), match='is'>
<re.Match object; span=(8, 11), match='too'>
<re.Match object; span=(12, 16), match='long'>위 예제를 보면 finditer는 findall와 동일한 기능을 하지만, finditer는 반복 가능한 객체(iterator object) 를 돌려준다. 이 반복 가능한 객체가 포함하는 각각의 요소는 match 객체이다.
findall은 리스트 형태로 반환해주기 때문에 다루기 쉽다. 그렇다면 나머지 메소드를이 반환하는 match 객체는 어떻게 사용할까? match 객체의 메소드가 존재한다! 아래에서 간단히 정리하겠다!!
match 객체의 메소드
match 객체의 메소드를 이용하면 match 객체안의 어떤 문자열이 매치되었는지, 매치된 문자열의 인덱스가 몇 번인지를 알 수 있다.
| Method | 목적 |
|---|---|
| group() | 매치된 문자열을 돌려준다. |
| start() | 매치된 문자열의 시작 위치를 돌려준다. |
| end() | 매치된 문자열의 끝 위치를 돌려준다. |
| span() | 매치된 문자열의 (시작,끝)에 해당하는 튜플을 돌려준다. |
p = re.compile('[a-z]+')
m = p.match('python')
print(m.group())
print(m.start())
print(m.end())
print(m.span())
>>> python
>>> 0
>>> 6
>>> (0, 6)이렇게 정규표현식과 정규표현식을 사용하여 Python에서의 문자열을 처리하는 메소드들을 정리해보았다. 코딩테스트 문제를 풀거나 프로젝트 개발을 할 때 많이 사용해봐야겠다는 생각을 했다. 중간에 정리했던 match(), search(), findall(), finditer(), ... 등의 메소드에 맨 처음 배운 정규표현식을 직접 넣어보면서 문자열 처리에 익숙해지도록 연습해봐야겠다!!
참고 : https://wikidocs.net/4308
https://wikidocs.net/4309
https://greeksharifa.github.io/%EC%A0%95%EA%B7%9C%ED%91%9C%ED%98%84%EC%8B%9D(re)/2018/07/20/regex-usage-01-basic/
https://nachwon.github.io/regular-expressions/
https://devkingdom.tistory.com/131
