Hadoop이란?
대량의 자료를 처리할 수 있는 큰 컴퓨터 클러스터에서 동작하는 분산 응용 프로그램을 지원하는 프리웨어 Java 소프트웨어 프레임워크이다. (출처 : 위키백과)
4차 산업 시대에서 '빅데이터' 라는 단어는 들어보지 않은 사람이 없을 정도로 쉽게 접할 수 있다. AI, 자율주행 등 미래를 책임지고 있다라고 표현할 수 있는 이러한 기술들은 '빅데이터' 에서 시작된다. 하지만 이러한 빅데이터를 처리하기 위해서는 데이터를 처리할 컴퓨터의 능력이 좋아져야한다. (고가의 슈퍼컴퓨터를 사용 및 구축해야함) -> Hadoop은 위의 문제점을 해결해준다.
Hadoop을 간단하게 정리해보겠습니다.
-
Hadoop 소프트웨어 라이브러리는 간단한 프로그래밍 모델을 사용하여 여러대의 컴퓨터 클러스터에서 대규모 데이터 세트를 분산처리할 수 있게 해주는 Framework이다.
<베이스 아파치 하둡 프레임워크는 다음의 모듈을 포함한다.>
- 하둡 커먼
- HDFS (Hadoop Distributed File System)
- YARN
- MapReduce
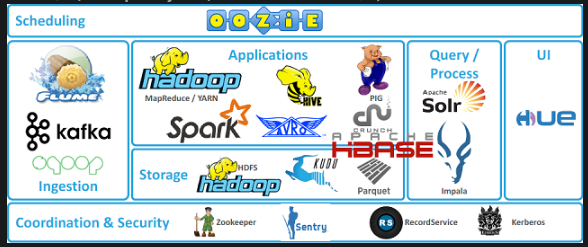 Hadoop Framework (출처 : 클라우데라)
Hadoop Framework (출처 : 클라우데라)
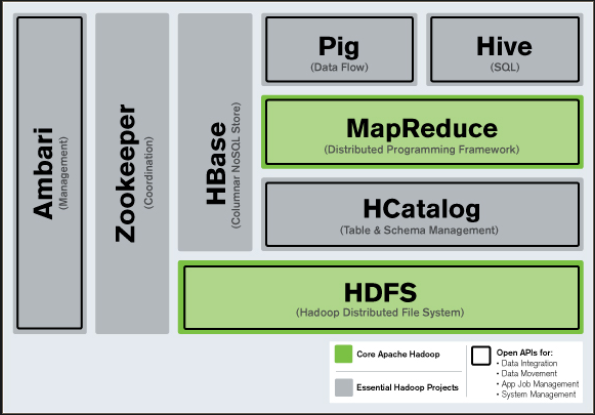 Hadoop Framework 2 (출처 : http://www.itworld.co.kr/print/73626)
Hadoop Framework 2 (출처 : http://www.itworld.co.kr/print/73626) -
하둡 코어 프로젝트(Framework) : HDFS(분산 데이터 저장), MapReduce(분산 처리)
-
하둡 서브 프로젝트(Framework) : 나머지 프레임워크들 -> 데이터마이닝, 수집, 분석 등 수행
이러한 Framework 중에도 가장 핵심적인 기능을 수행하는 것은 HDFS와 MapReduce이다!!
-
엄청난 데이터를 분산처리를 통해 많은 데이터를 저장 및 처리하는 기술 (저렴한 비용, 확장성 용이)
-
단일 서버에서 수천대의 머신으로 확장할 수 있도록 설계되었다. -> 가장 강력한 기능은 확장성이다. (자유자재로 규모를 축소, 확장할 수 있다.)
-
Hadoop은 HDFS, MapReduce Framework로 시작되었다. 그러나 빅데이터 저장, 실행 엔진, 프로그래밍 및 데이터 처리 같은 Hadoop 생태계 전반을 포함하는 의미로 확장 및 발전되었다.
-
Hadoop은 트랜잭션, 락 관리가 되지 않으므로 배치성 데이터를 저장 및 처리하기에 좋다. 즉 데이터를 막 집어넣기에 좋다는 의미이다.
<-> RDBMS(관계형 데이터베이스 시스템)은 트랜잭션, 락 관리가 가능하므로 실시간 데이터(거래 데이터)를 처리하기에 좋다.
별첨
Hadoop 아키텍처 설치는 다양한 방법으로 설치 가능 -> 일반적인 방법으로는 3~4대의 머신에 centos나 linux 설치 후 Java, Hadoop 설치하고 하나하나 다 설치하는 방법
BUT 이 방법은 굉장히 까다롭고 복잡함! 왜냐하면 하둡, 주키퍼, 스파크, 제플린 등의 설치까지는 괜찮으나 플럼, 카프카, 스쿱 등 다양한 하둡 에코 시스템을 설치하다보면 까다롭고 복잡해지기 때문이다.
이 과정을 좀 단순하고, 명확하게 해주면서 설치를 쉽게 해주는 방법이 존재 -> 그 중 하나가 Cloudera를 이용하는 방법
Cloudera : 빅데이터 아키텍처 오픈 소스들을 모아서 잘 조립해주기도 하고, 제품으로 판매한다.
각종 애플리케이션들을 패키지화 하여 개발자들에게 제공하는 회사로 자신들만의 Manager를 통해 각종 애플리케이션 배포, 설정을 쉽고 빠르게 할 수 있도록 도와준다.
다음에는 Hadoop의 코어 프로젝트를 알아보는 시간을 가지겠습니다.
