Hadoop의 코어 프로젝트(Framework)인 맵리듀스에 대해 정리해보겠습니다.
(참고 : https://12bme.tistory.com/154)
MapReduce 란?

-
하둡의 계산을 담당한다. (HDFS는 하둡의 저장소를 담당)
-
대용량의 데이터를 처리하기 위한 분산 프로그래밍 모델 (소프트웨어 Framework)
-
정렬된 데이터를 분산처리(Map)하고 이를 다시 합치는(Reduce) 과정을 수행
-> 프로그래머가 직접 작성하는 Map과 Reduce 라는 2개의 메소드로 구성 -
MapReduce Framework를 이용하면 대규모 분산 컴퓨팅 환경에서 대량의 데이터를 병렬 (Parallel : 동시에 많은 분석을 수행)로 분석 가능하다.
-
하둡에서 대용량 처리를 위한 기술들 중 가장 인기가 있다.
흩어져 있는 데이터를 수직화 -> 그 데이터를 각각의 종류별로 모으고(Map) -> 필터링과 정렬을 거쳐 데이터를 추출(Reduce)하는 분산처리 기술과 관련된 Framework를 의미!
Map 작업을 수행한 각각의 블럭의 결과 정보를 합치는 작업(Reduce)를 수행하게 되는 방식. 하둡에서는 계산시, 큰 파일을 블럭단위로 나누고 모든 블럭은 같은 Map 작업을 수행하고 이후 Reduce 작업을 수행하게 된다.
MapReduce의 원리
(출처 : http://www.incodom.kr/hadoop_%EC%B4%9D%EC%A0%95%EB%A6%AC)
 맵 리듀스를 비유한 그림예시
맵 리듀스를 비유한 그림예시
1명이 100개의 데이터를 보는 것과 / 100명이 1개씩 데이터를 보는 것 중에 어느 것이 더 빠를까? 상식적으로 100명이 1개씩 데이터를 보는 것이 훨씬 더 빠를 것이다. 이것이 분산처리의 핵심이지만 100명이 훑어본 결과를 취합하고 정리하는 시간의 소모가 있기 마련이다. 또한 탐색할 데이터의 양이 101개라거나 1개의 길이가 서로 다르다면 이를 동일한 업무크기로 나누는 일도 쉽지가 않다.
MapReduce는 이러한 처리를 도와주는 역할을 한다. 명칭 그대로 Map단계 & Reduce단계로 이루어진다.
먼저 Map단계에서는 흩어져 있는 key, value로 데이터를 묶어준다. 예를 들면 key는 몇 번째 데이터인지, value는 값을 추출한 정보를 가진다. 그리고 Reduce 단계에서는 Map단계의 key를 중심으로 필터링 및 정렬을 진행한다. 하둡에서는 위 Map & Reduce를 함수를 통해서 구현하고, MapReduce Job을 통해서 제어한다.
Map & Reduce 구성
-
MapReduce는 Hadoop 클러스터의 데이터를 처리하기 위한 시스템으로, 총 2개(Map & Reduce)의 phase로 구성되어 있다.
-
Map과 Reduce사이에는 Shuffle과 Sort라는 스테이지가 존재한다. 각 Map Task는 전체 데이터 세트에 대한 별개의 부분에 대한 작업을 수행하게 되는데, 기본적으로 하나의 HDFS Block을 대상으로 수행하게 된다. 모든 Map Task가 종료되면 -> MapReduce 시스템은 intermediate 데이터를 Reduce phase를 수행할 노드로 분산하여 전송한다.
분산형 파일시스템에서 수행되는
① MapReduce 작업이 끝나면 HDFS에 파일이 써지고(write),
② MapReduce 작업이 시작될 때는 HDFS로 부터 파일을 가져오는(Read) 작업이 수행된다.
Map (맵)
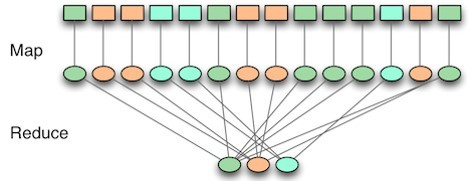
-
인풋 데이터를 가공하여 데이터를 연관성 있는 데이터들로 분류하는 작업 -> (key, value)의 형태로 분류
-
맵 리듀스 Job의 입력 크기를 스플릿이라고 한다. -> 각 스플릿마다 하나의 Map Task를 생성하게 됨 -> 만들어진 Map Task는 스플릿의 레코드를 Map 함수로 처리 -> (key, value) 구조를 가지는 중간 산출물이 생성됨!
Reduce (리듀스)
-
Map에서 출력된 데이터에서 중복 데이터를 제거하고 원하는 데이터를 추출(Extract)하는 작업
-
중간 산출물을 key 기준으로 각 Reduce로 분배 -> 사용자가 정의한 방법으로 각 key의 관련된 정보를 추출하는 단계
-
중간 산출물을 정렬(Sort)하고 하나로 합쳐 Reduce Task로 생성 -> 사용자 정의 Reduce 함수로 전달 -> 만들어진 결과물은 안정성을 위해 일반적으로 HDFS에 저장!
(EX) 맵 리듀스의 처리 과정
위 그림은 문자열 데이터를 포함된 단어의 빈도수를 출력해주는 과정
- Splitting : 문자열 데이터를 라인별로 나눔
- Mapping : 라인별로 문자열을 입력 -> (key, value) 형태로 출력
- Shuffling : 같은 key를 가지는 데이터끼리 분류
- Reducing : 각 key 별로 빈도수를 합산해서 출력
- Final Result : 리듀스 메소드의 출력 데이터를 합쳐서 하둡 파일시스템에 저장
(더 자세한 설명 : https://blog.acronym.co.kr/312)

 맵 리듀스의 전체 처리 과정이다.
맵 리듀스의 전체 처리 과정이다.
맵 리듀스의 잡 (Job)
Job은 'Full Program' 즉, 전체 프로그램을 의미한다. 데이터 집합을 통해 Mapper와 Reducer를 전체 실행한다. Task는 데이터 조각을 통해 하나의 Mapper 또는 Reducer를 실행하게 된다.
-
클라이언트가 수행하려는 작업단위로, 입력데이터, 맵리듀스 프로그램, 설정 정보로 구성.
-
하둡은 Job을 Map Task와 Reduce Task로 작업을 나누어서 실행
-
Job이 실행되는 과정을 제어 해주는 노드
맵 리듀스 시스템 구성
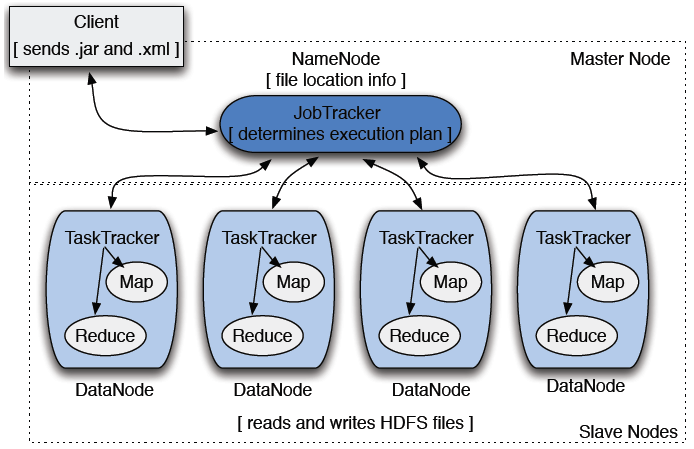
-
맵 리듀스 시스템은 Client, JobTracker, TaskTracker로 구성
-
JobTracker 는 NameNode에 위치
TaskTracker 는 DataNode에 위치
Client
- 분석하고자 하는 데이터를 Job의 형태로 JobTracker에게 전달
JobTracker
- NameNode에 위치
- 하둡 클러스터에 등록된 전체 Job들을 스케줄링하고 모니터링 수행
맵 리듀스 Job들은 JobTracker라는 소프트웨어 데몬에 의해 제어된다. JobTracker들은 마스터 노드에 존재하면 다음과 같은 역할을 수행한다.
- 클라이언트는 맵리듀스의 Job을 JobTracker에게 보냄 -> JobTracker는 클러스터의 다른 노드들에게 맵과 리듀스 Task를 할당 -> 이 노드들은 TaskTracker라는 소프트웨어 데몬에 의해 각각 실행 -> TaskTracker는 실제로 맵 or 리듀스 Task를 인스턴스화하고, 진행 상황을 JobTracker에게 보고해야함
TaskTracker
- DataNode에서 실행되는 데몬 (DataNode에 위치)
- 사용자가 설정한 맵리듀스 프로그램을 실행
- JobTracker로부터 작업을 요청받고, 요청받은 Map과 Reduce 개수만큼 -> Map Task와 Reduce Task를 생성
- JobTracker에게 상황 보고

16개의 댓글

The MapReduce framework allows for parallel processing of data in a large-scale distributed computing heardle environment. It enables the analysis of massive volumes of data by dividing the work into smaller tasks that can be executed simultaneously.


Accessing large amounts of data housed in the Hadoop File System (HDFS) requires the usage of the MapReduce programming paradigm or pattern. It is essential to the operation of the Hadoop framework and a key component. geometry dash meltdown




I’m so grateful for your excellent post. The way you presented the information was clear, concise, and very helpful. It’s evident that you have a deep understanding of the topic, and your ability to communicate that knowledge effectively is much appreciated. Thank you for taking the time to share your insights and for contributing such valuable content to our community. backyard baseball
I’m so grateful for your excellent post. The way you presented the information was clear, concise, and very helpful. It’s evident that you have a deep understanding of the topic, and your ability to communicate that knowledge effectively is much appreciated. Thank you for taking the time to share your insights and for contributing such valuable content to our community. backyard baseball
I’m so grateful for your excellent post. The way you presented the information was clear, concise, and very helpful. It’s evident that you have a deep understanding of the topic, and your ability to communicate that knowledge effectively is much appreciated. Thank you for taking the time to share your insights and for contributing such valuable content to our community. backyard baseball
I’m so grateful for your excellent post. The way you presented the information was clear, concise, and very helpful. It’s evident that you have a deep understanding of the topic, and your ability to communicate that knowledge effectively is much appreciated. Thank you for taking the time to share your insights and for contributing such valuable content to our community. backyard baseball

If you are looking to get freebies and rewards in the CM game, then collect spins for coin master here. This will help you get ahead of your competitors in the Coin Master game
Coin Master ist ein beliebtes Handyspiel, das Millionen von Spielern freespinscoinmaster.de weltweit begeistert. Das Spiel kombiniert Glück, Strategie und tägliche Belohnungen in einem spannenden Abenteuer. Mit jedem Dreh am Glücksrad hast du die Chance auf Münzen, Angriffe, Überfälle oder Schutzschilde.
Coin Master Tiradas Gratis Coin Master Jogo es uno de los juegos móviles más populares del mundo, donde la estrategia y la suerte se combinan para ofrecer una experiencia divertida y adictiva. El objetivo del juego es simple: girar la ruleta, ganar monedas, atacar aldeas, y construir la tuya propia para avanzar de nivel.
The Globle game answers in the game helped to play the game with more fun. As many players get stuck on some levels of the Globle game, then it is good to have some hints to get started playing the Globle Game again

Great site. loved the information, just as your other articles. anyways. keep the good work just like moon active did with coin master free spins thank you😊👌
This is the first time I have heard about MapReduce. I like how you explain to hearts online readers some basic information about MapReduce and how does it work? contexto