링크 (https://velopert.com/436)의 강의를 참고하여 학습 및 실습한 내용을 정리하였습니다.
MongoDB

- 아페로 GPL과 Apache License를 결합하여 공개된 DB, 무료 오픈 소스 SW이다. (위키백과)
- C++로 작성된 오픈소스 Cross-Platform 데이터베이스
- 문서지향적(Document-Oriented) --> 테이블의 구조(schema)가 없음
- NoSQL DB 중 1위
NoSQL
- Not Only SQL의 약자 --> "SQL과 다른 언어이다... SQL말고 NoSQL을 쓰면 어떠한 장점이 있나보다..."
- 기존 RDBMS의 한계를 극복하기 위해 만든 새로운 형태의 SQL
- 관계형 DB는 SQL을 사용 / MongoDB는 NoSQL을 사용 --> 구조(schema)와 JOIN 연산이 존재X
- 자주 변경되지 않는 데이터에 적합하다!
Document
- RDBMS의 튜플(행, 레코드, 인스턴스)의 개념이라 생각하면 쉽다. 문서라고 생각하면 안됨!!
- Document의 데이터 구조는 1개 이상의 key-value쌍으로 구성
(Ex) Document내의 데이터 1개 구조 == "RDBMS의 Table내 데이터 하나의 행이라고 생각하면 쉽다."
{
"_id": ObjectId("5099803df3f4948bd2f98382"),
"username": "velog",
"name": { first: "J.H", last: "Park" }
}--> _id, username, name 은 key이다.
--> 콜론(:) 오른쪽 값들은 value이다.
-
_id는 12bytes의 hexadecimal 값
-
각 document의 유일성을 제공
-
첫 4bytes는 현재 timestamp + 다음 3bytes는 machine id + 다음 2bytes는 MongoDB 서버의 프로세스 id + 마지막 3bytes는 순차번호(추가될 때 마다 값이 높아짐)
-
Document는 동적(dynamic)의 schema를 가지고 있다. 같은 Collection내의 Document끼리 다른 schema를 가지고 있을 수 있다. 즉, 서로 다른 데이터(서로 다른 key)를 가질 수 있다. --> RDBMS에서는 테이블의 schema가 고정되어 있어 같은 테이블 내의 데이터의 구조(schema)가 다를 수 없음.
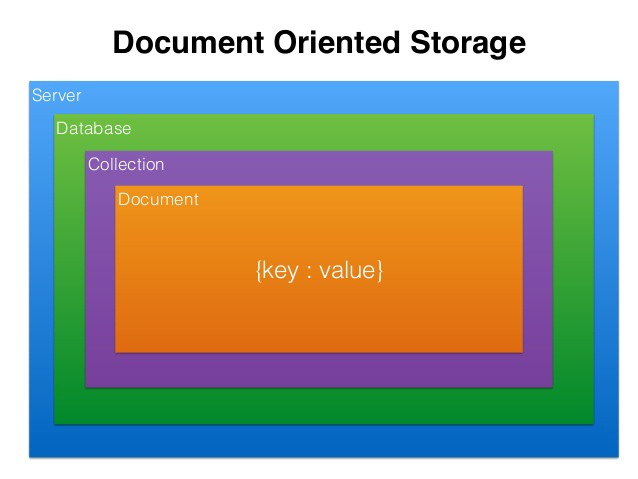
Collection
- "RDBMS의 Table의 개념과 비슷하다고 생각하면 쉽다."
- MongoDB의 Document의 그룹(Document들의 집합) --> Document("데이터 1행이라 생각하면 쉽다...")들이 Collection 내부에 위치한다.
- schema가 없다!! --> why? 각 Document들이 동적인 schema를 가지고 있기 때문이다.
Database (MongoDB)
- Collection들의 물리적인 컨테이너
- 각 Database는 FileSystem에 여러개의 파일로 저장된다.
MongoDB vs RDBMS
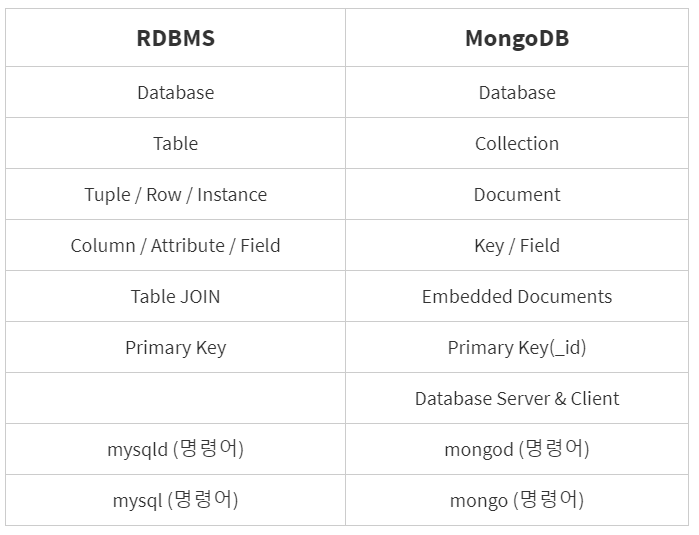
MongoDB의 장점
-
schema가 없다. --> Collection내의 데이터 구조(=Document의 구조)가 다를 수 있다.
-
각 객체의 구조가 뚜렷하다.
-
복잡한 연산인 JOIN 연산이 없다.
-
Deep Query Ability : 문서지향적 Query를 사용할 수 있어 SQL만큼 강력한 Query 성능을 제공한다.
-
Application에서 사용되는 객체를 DB에 추가할 때 Conversion, Mapping이 필요X
MongoDB 연산자

https://docs.mongodb.com/v3.2/reference/operator/query/ --> 더 많은 MongoDB 연산자를 학습할 수 있습니다.
db.컬렉션.update() vs db.컬렉션.replace()
-
update() : 데이터의 구조 변경X + 값만 변경
-
replace() : 데이터의 구조와 값을 변경
(Ex)
name : "Betty" / age : 20 / city : Redmond
의 구조인 Document를 수정해보자- age를 30으로 update() -->
name : "Betty" / age : 30 / city : Redmond
데이터의 구조(틀)은 유지된 채 age의 값만 변경된다!- age를 30으로 + name은 남겨두고 replace() -->
replace() --> name : "Betty" / age : 30
데이터의 구조가 변경된다. Document의 city가 없어졌으며 age는 30으로 변경되었다.+ MongoDB는 db.컬렉션.find() (조회) // db.컬렉션.sort() (정렬) // db.컬렉션.limit() (출력 행수 제한) // db.컬렉션.skip() (건너뛰기) // db.컬렉션.update() (수정) 등의 다양한 함수를 지원한다. 또한, 함수안에 많은 옵션들을 정할 수 있다. 그리고 index의 개념도 있다.
("연산자 및 함수와 옵션(매개변수)가 너무 많아 따로 정리하지는 못했다. 필요할 때 마다 공식문서를 참고하면 될 것 같다...") ("SQL과 문법이 달라 많이 헷갈렸다...")

The way you have presented your fnf game ideas in this opinion is both articulate and eloquent.