문자열 다루기
- replace()
- 문자열을 바꾸는 함수이다. 첫 인자 문자열을 두 번째 문자열로 바꾼다.
str = "i am very hungry"
str2 = str.replace("hu", "a")
str3 = str.replace("gryp", "ting") # 안바뀜
print(str)
print(str2)
print(str3)
hu를 a로 바꿨다.
첫 인자를 찾지 못하면 아무것도 바뀌지 않는다.
- strip()
- 앞뒤에 공백이 있을 때 공백을 제거한 새로운 문자열을 생성
str = " 앞뒤로 공백이 존재 "
print(str)
print(str.strip()) # 앞뒤 공백만 제거
print(str.replace(" ", "")) # space를 제거
- split()
- 특정 문자열로 문자열을 분리하는 함수
str = "#나는#잠을#자고#싶다."
print(str[3])
splitResult = str.split("#") # '#'으로 분리해라
print(splitResult[0]) # '#'앞의 공백
print(splitResult[1])
print(splitResult[2])
print(splitResult[3])
print(splitResult[4])
- len(), index(), count()
- len(x) : 시퀀스x의 길이를 알려준다.
- index(x) : 리스트 내에 x가 등장하는 첫 인덱스를 알려준다.
- count(x) : 리스트 내에 x가 몇 번 등장하는지 알려준다.
list = [2, 3, "ab", "abc", "come", 3, 3]
print(len(list)) # list 의 길이
print(list.index("abc")) # 처음 "abc"나오는 index
print(list.count(3)) # list 내 3이 등장하는 횟수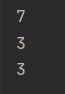
텍스트 파일 다루기
- 파일 읽기
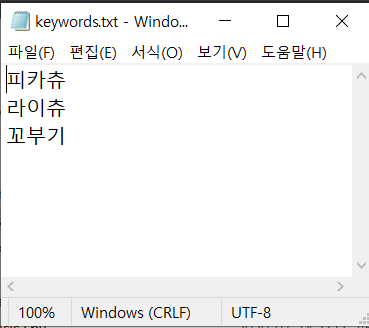
# keywords.txt파일을 읽기전용으로, utf8로 인코딩하여 읽어라
f = open("keywords.txt", "r", encoding="utf8")
for i in f:
print(i, end="") # end=""는 붙여 출력하기 위함 = 줄바꿈 X
f.close()
- 파일 쓰기
f = open("text.txt", "w")
for i in range(10):
f.write(str(i) + "번째 줄입니다.\n")
f.close()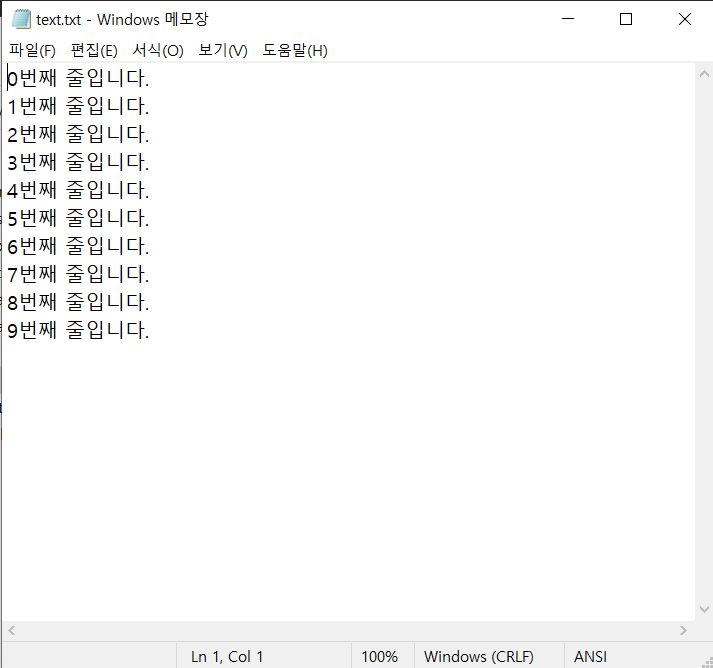
날짜 처리
- 현재시각, 날짜, 시간 출력
from datetime import datetime
x = datetime.now()
print(x)
print(x.date())
print(x.time())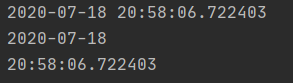
- 기본 날짜 설정
from datetime import datetime
x = datetime(2020, 5, 20)
print(x)
- 형식에 따른 출력 방법
from datetime import datetime
x = datetime(2020, 5, 20)
print(x.strftime("%d.%m.%Y"))
print(x.strftime("%Y-%m-%d"))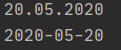
- 문자열을 형식에 따라 읽기
from datetime import datetime
str = "09/19/2018"
date = datetime.strptime(str, "%m/%d/%Y")
print(date.date())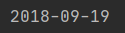
<추가 설명>
- strftime() : 시간을 문자열로 변환.
- strptime() : 문자열(날짜)을 날짜, 시간 객체로 변환.
- 날짜 대소비교
from datetime import datetime
str = "09/19/2018"
date = datetime.strptime(str, "%m/%d/%Y")
print(datetime.now() < date)
print(datetime.now() > date)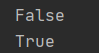
- 시간 변경
from datetime import timedelta, datetime
date = datetime(2020, 2, 1)
for i in range(5):
date += timedelta(days=1)
print(date.date())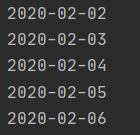
리스트, 튜플, 셋, 딕셔너리
1. 리스트 (List)
- [] , list()로 선언
- 순서가 있다. (sequence 구조) -> [1,2,3] ≠ [2,1,3]
- 삽입, 삭제, 수정이 가능하다.(mutable)
2. 튜플 (Tuple)
- () , tuple()로 선언
- 순서가 있다. (sequence 구조) -> (1,2,3) ≠ (2,1,3)
- 삽입, 삭제, 수정이 X (immutable)
리스트와 튜플의 공통점 : 원소로 구성 / seq형 구조 / indexing과 slicing이 가능
3. 셋 (Set)
- 수학의 집합이라고 생각하면 된다.
- 교집합, 합집합, 차집합, 배타적 논리합, 부분집합, 진부분집합, 상위집합, 진상위집합 연산을 수행할 수 있다.
- {} , set()로 선언
- 순서가 없다. -> {1,2,3} = {2,1,3}
- 중복 허용이 안된다.
- 삽입, 삭제, 수정이 가능하다.
- index로 호출이 안된다. -> indexing과 slicing이 안됨.
- Set의 값들을 for문으로 출력할 때 무작위로 출력된다.
4. 딕셔너리 (Dictionary)
- {} , dict()로 선언
- {key : value} 값의 쌍으로 이루어짐.
- 삽입, 삭제, 수정이 가능하다.
- key 구조 (index 구조 X)
- key는 중복 허용 X (유일한 구분자)
- value는 중복 허용!
- Set과 마찬가지로 원소들의 출력 순서가 무작위로 출력된다.

Computer Science!!