Artificial Intelligence basic
1. DNN이란?
- Rule-based Knowledge Engineering
- Data-based Deep Learning - more powerful
- 데이터의 모양만 만들어주면 딥러닝 모델이 예측하는 시스템.
- Rule을 사용하지 않아도 새로운 test 문제가 있을 때 예측 가능- image, audio, text .. 등 다양한 데이터셋에도 적용 가능
- 데이터의 모양만 만들어주면 딥러닝 모델이 예측하는 시스템.
공간을 회전시키(Rotating) + 찌그러뜨리기(Squasing)
- Andrew 'Crumpled Paper Analogy'
- Rotating(weight multiplication) & Squash (Activation)
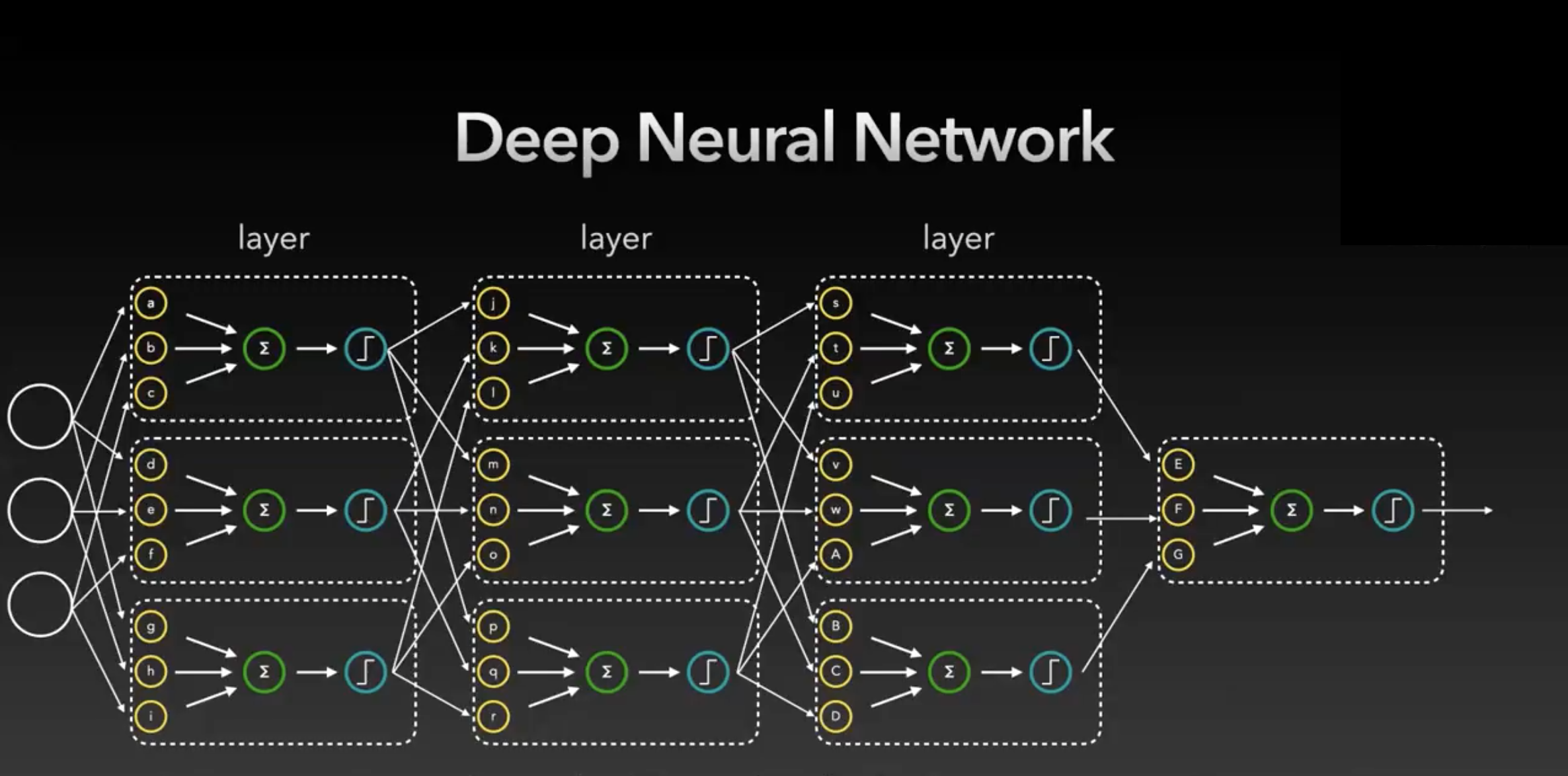
2. Model Parameters
Parameters = Weight + Bias
- 뉴런의 개수 : 10개
- 파라미터의 개수 : 30개 (각각의 가중치들은 각각 다른 실수)
- input에 대하여 원하는 output을 출력하기 위해 각각의 parameter의 값을 찾는 것이 "학습 과정"
Gradient : 파라미터 한 개의 값의 변화가 output에 얼만큼의 영향을 줄 것인가의 정도
Optimization(최적화) : 미리 정의한 손실 함수(loss function)를 최소화하는 파라미터의 상태를 찾는 것
Gradient Descent : Optimization 하는 과정
- current loss의 기울기(magnitude)를 구한 뒤, learning rate만큼 이동
- magnitude x learning rate
- 너무 많이 움직이면 반대로 가서 계속 왔다갔다 할 수 있으니, learning rate를 너무 높게 잡으면 안된다.
- 너무 적게 learning rate를 적으면 local minima에 빠질 수 있다.(기울기에서 가장 낮지 않은 구덩이에 빠짐, 가장 낮은 지점에 가야하는데)
- 우리는 주어진 현재 상황의 gradient만 알 수 있는데, 모든 면의 모든 점을 구해서 gradient를 구하려면 10개의 number에서 1000개의 parameter의 경우의 수면 10의 1000승을 계산해야 하기 때문에 불가능하다.
- neural network machine laerning은 끊임없이 정답을 맞추려고 노력하는 과정이다.
Backpropagation : Gradient Descent를 계산하는 과정
손실 함수(loss function)
- Simple Loss
ex. 정답(1) - 예측값(0.8) = Simple Loss(0.2) - Cross Entropy
ex. H(q)=−∑c=1Cq(yc)log(q(yc))
log값 만큼 정답과의 차이의 비율에 차등을 둠
3. Backpropagation, 역전파
- 각각의 parameter가 최종적인 loss값에 미치는 영향인 gradient를 뒤에서부터 계산하여 앞으로 보내주는 것
- Forward propagation 에서 편미분 해주면 역전파
- Upstream gradient : 내 출력이 바뀔때 최종 output이 어떻게 바뀌는지
- local gradient : current gradient
- Downstream gradient : Upstream gradient * local gradient
4. Fully Connected Layer(FC)
- 뉴런의 각각의 feature 순서가 상관 없다.
- row별이던, column별이던 상관없이 쭉 flatten해서 뉴럴 네트워크가 값을 보고 있음.
- 각각의 값이 독립적인 값이다. 자유도가 높음/문제를 똑같이 외워버리는 문제점
5. Convolution Neural Network (CNN)
-
Translation Invariance : 같은 이미지이지만 한 픽셀씩 밀어져있는 왼쪽으로 조금 이동한 이미지마저도 인식이 어려운 FC의 문제점을 개선한 것. 다른 쪽으로 평행 이동을 하면 출력도 평행 이동을 한다.
-
3x3의 kernel=3인 kernel/filter가 하나의 FC라고 생각할 수 있다. 각 칸 안에 있는 값은 weight. Conv2d에서 각각 안에 있는 걸 곱하고 전부 더한 값을 내뱉는다.
-
입력의 이미지의 크기와 상관 없이 파라미터의 수는 정해져있음
ex 7x7 이미지가 있을 때, 49개의 weight가 있음. 3x3 CNN으로 보겠다면, 9개가 필요할 때, 100x100이든, 1000x1000의 이미지이든 CNN은 3x3으로 보는 거고, 이게 파라미터가 정해져있다는 뜻. 3x3으로 요약값을 찾아 낸 걸 local pattern이라고 한다.
-
Conv1d, Conv3d도 가능
-
1960s Wiesel's experiment on cat's visual cortex : 작은 것부터 패턴을 찾고, 큰 패턴을 찾는 고양이 뇌 인식 실험에서 CNN 고안
-
Stride : 한 칸씩 움직이면 Stride가 1, 2칸 띄면 Stride 2 --> 출력되는 output shape이 작아진다.
- 출력 결과가 작아지거나 커질 수도 있음- 쓰고 남는 건 버리거나 쓸 수도 있다.
-
Padding : 모서리 부분이 중복적으로 보이지 않으므로 패딩으로 모서리 부분을 활용시킬 수 있도록 한다.
-
출력 크기를 맞추려면 Padding을 써야 한다.
-
Padding 1이면 모서리가 정 중앙에 온 경우부터 볼 수 있다.
-
Padding을 1로 두면 인풋과 아웃풋의 shape을 맞출 수 있다.
-
Max Pooling : FN -> CNN ---> 점점 요약된 정보를 사용하기 위해 Stride를 사용하거나 Max Pooling을 사용한다.
- 정해진 구역 안에서 제일 큰 값만 뽑아서 새로운 대표값을 하나 뽑는다.- 필요하면 mean pooling, minimum만 쓴다던지 다른 여러 방법이 있을 수 있음
-
Channel x {H x w} 원래 이미지 사이즈가 100x100이고, RGB 값이어서 3개
= 3 x 100 x 100
-> kernel 수를 16개를 쓰겠다. 16x{50x50} --> Max Pooling해서 절반을 줬다. -
CNN 하고 나면 output의 shape은 줄어들었지만 channel의 수는 늘어남, (큐브 작아지고 두꺼워짐) 대표하는 이미지가 커졌기 때문에 차원의 정보가 많이 담을 수 있는 벡터를 사용해야함. 그래서 channel이 두꺼워 지는 것이 일반적이다.
-
점점 크기를 줄여서 전체 이미지를 대변할 수 있게 만든 다음, 마지막에 Classify를 붙이는게 일반적
-
앞에서는 선, 색상을 주로 보고 뒤로 갈 수록 특징적이고 고차원적인 결과를 찾으려고 한다.
-
Receptive Field : 얼마나 많은 픽셀을 보고 결과를 냈는지
이미지가 7x7인데 receptive field가 5x5이면 나머지 들어있지 않은 부분은 결과에 영향을 안끼친다. 연결이 안되어 있기 때문에, receptive field 밖의 값을 줄이거나 크게 키워도 최종 output은 변하지 않는다.
receptive field를 알 수 있는 제일 쉬운 방법은 Backpropagation 활용하는 방법 -
Conv1d kernel3면 shape-2, maxPooling size2면 /2
ex. 32개 input이면 Conv1d, kernel=3 -> 32-2=30, MaxPooling size 2 --> 30/2=15
