Natural Language Processing 2022
1. Word-Vector
word2vector, word embedding 처럼 단어/텍스트를 distributed하게(분산적으로) 표현하는 방식이고, 각 단어의 similarity를 vector간의 dot(scalar) product로 계산해서 얻어지는 vector를 말한다.
- WordNet : "synonym sets + hypernyms" 으로 이루어진 사전
- localist representation : 특정 feature를 표현하는 정보가 대응되는 것, 대표적으로 one-hot encoding처럼 어떠한 정보를 표현하기 위해 하나 혹은 소규모의 뉴런들만 사용되어짐을 Local representation이라고 한다.
one-hot encoding은 discrete symbols를 사용한 대표적 예시인데, 0과 1로만 표현되기 때문이다. 그러면 단어의 의미간 similarity를 표현하기 어렵다는 단점이 생긴다. 단점을 보완하기 위해 vector간의 encode similarity를 배우게 할 수 있다. - Orthogonal : 직교, perpendicular(수직선)와 비슷한 의미, a·b로 나타낸다.
- Word2Vect : text간의 각 position을 t, center word를 c, context(center word 외의 뜻의 "outside") word를 o라고 했을 때, c와 o사이의 Similarity를 구해서 둘의 확률을 계산하고 그 확률을 maximize하도록 word vector를 계속해서 조정(adjusting)한다. 여기서 c의 앞 2개의 outside word, 뒤 2개의 outside word로 계산한다면 window size는 2이다. (아래 그림 설명)
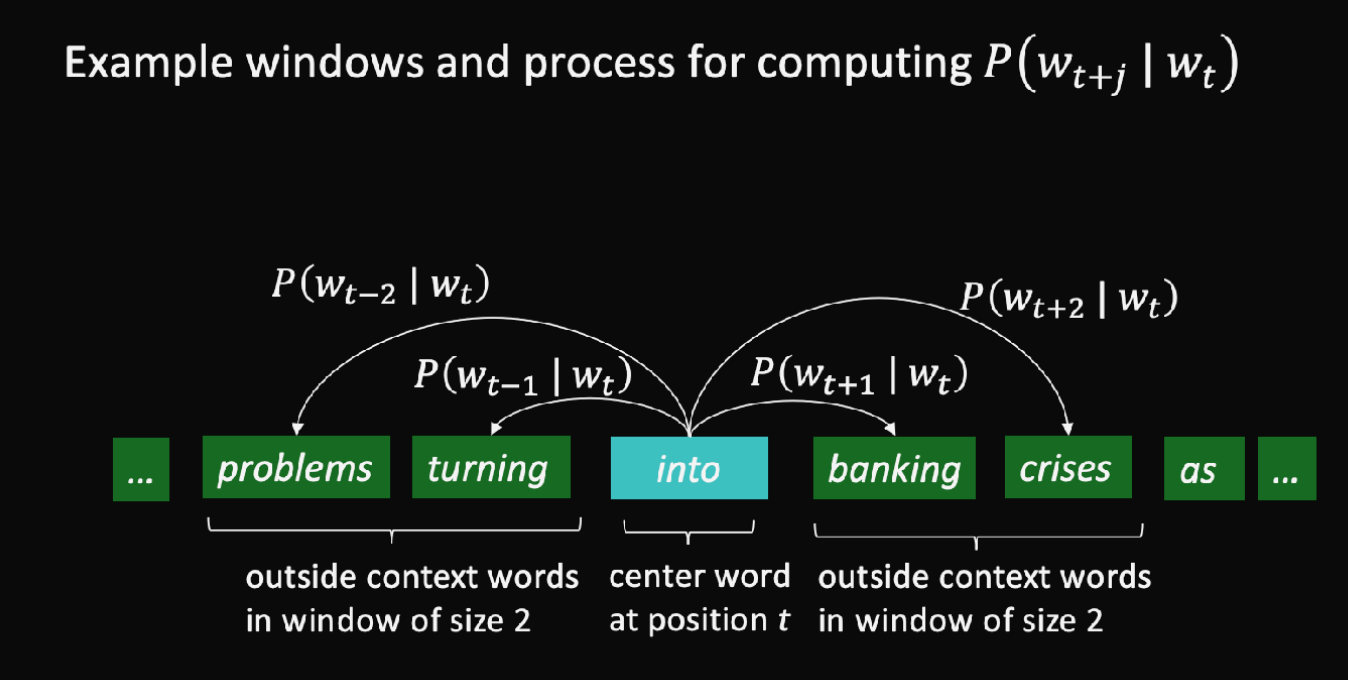
- Conditional Probability : 조건부가 있는 확률, 내가 어떤 조건에서 특정하게 또 이러할 확률. 확률 P안에 |로 표시하는 게 오른쪽이 context 조건이고 왼쪽이 거기서 또 알고싶은 specific한 조건.
- Collaborative filtering : 각각이 independent할 때 수학적으로 예측이 어려워(orthogonal하여) 새로운 차원을 사이에 filter처럼 만들어서 예측하기 쉽게 만드는 것, 여기서 그 새로운 차원을 latent embedding(bottleneck)라고 하기도 한다.
- Dot Product : 각 대응하는 dimension의 값을 곱한 것으로 주어진 input의 single neuron의 wegithed sum이라고도 표현한다. 그리고 보통 각 word를 x축에 놓았을 때, y축은 각각의 다른 dimension이라고 한다.
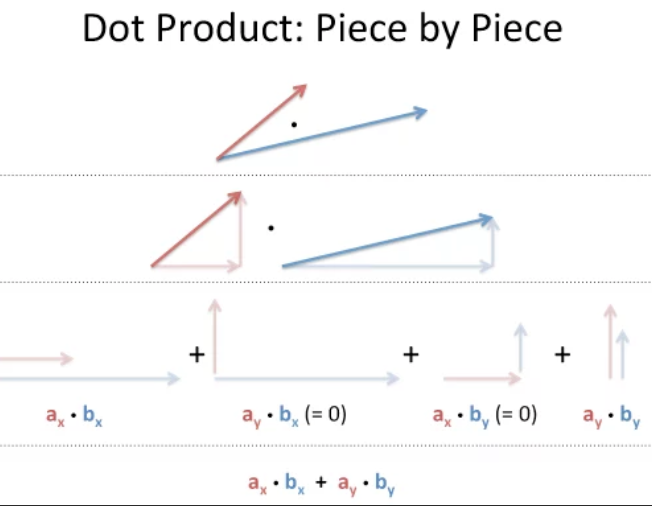
- Cosine Similarity : vector간의 similarity를 계산하는 방법 중 하나. dot product값에서 전체 vector 길이로 나누기, 길이니까 절댓값이고 이 값은 -1에서 1 사이의 값이다. 두 벡터 값이 같으면 1, orthogonal하면 0, opposite이면 -1.
- Word Analogy : king 빼기 man 더하기 woman 하면 queen이다 뭐 이렇게 단어끼리 덧셈 뺄셈으로 나타내는 것
오늘의 단어 정리 : WordNet, Word2Vect, Local representation, Orthogonal, Conditional Probability, Collaborative Probability, Bottle Neck, Cosine Similarity, Dot Product, Word Analogy
Likelihood
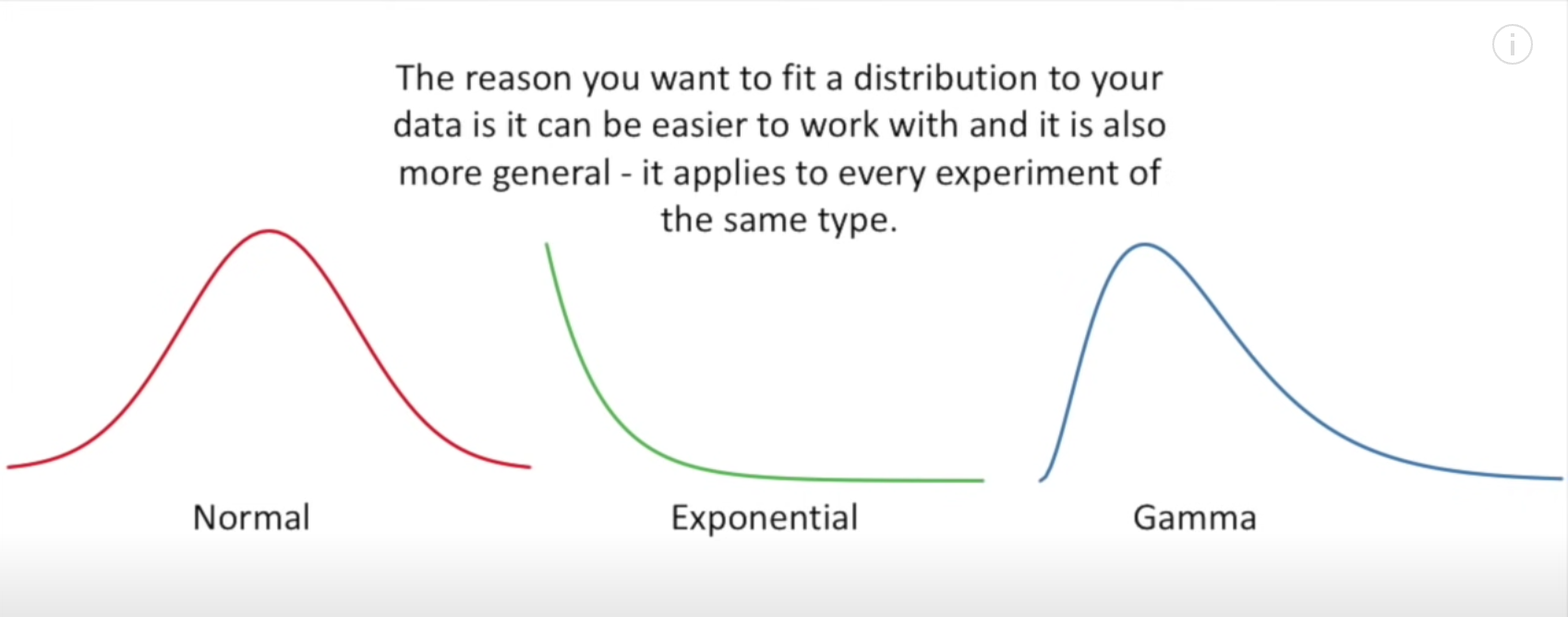
다양한 distribution (왼쪽 부터 정규분포, 지수분포, 감마분포)가 있는데 우리는 데이터들이 이 중에 어떤 데이터 분포를 가지고 있는지 효율적으로 알아맞춰야 한다. 그래야 예측이 되니까! 여기서 이제 weight가 중요한데, 분포에서 weight란 무게중심이 어디 있냐는 거니까 어디에 몰려있는지, 어디에 집중적으로 분포되어있는지 그 부분이 바로 weight인거다. (symmatrical - 대칭적이다 / skewed - 치우쳐져있다) / (skinny - 갑자기 훅 올라갔다 내려오는 형태 / medium - 중간 / large-boned - 뭉툭하고 넓게 살짝만 올라온 형태) 이 weight가 mean value에서 얼마나 떨어져있고 얼마나 가까운지를 다시 값을 확인해본게 likelihood이다.
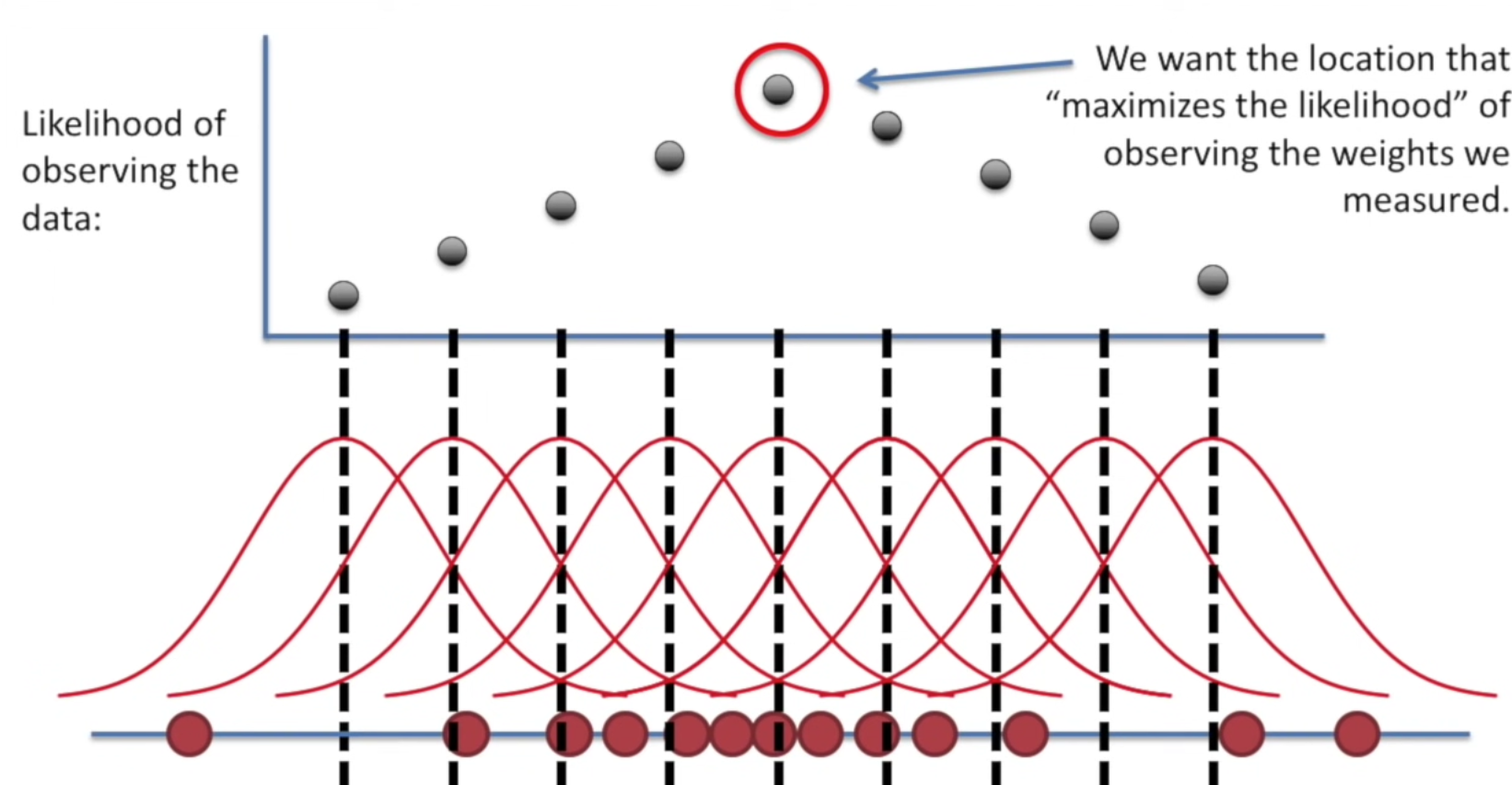
-
MLE(Maximum Likelihood Estimation) - Maximum Likelihood Estimation은 Likelihood 함수의 최대값을 찾는 방법이라 할 수 있다. log 함수는 단조증가 함수이기 때문에 likelihood function의 최대값을 찾으나 log-likelihood function의 최대값을 찾으나 두 경우 모두의 최대값을 갖게 해주는 정의역의 함수 입력값은 동일하다. 따라서, 보통은 계산의 편의를 위해 log-likelihood의 최대값을 찾는다.
-
Object Function : 목적 함수라고도 하고, 보통 MLE를 할때 최댓값을 찾길 원하기 때문에 감소하는 방식이 아닌, 즉 비용함수가 아닌 목적함수로 언급해야 한다. Object Function-MLE/Cost Function(오차 계산, 데이터에서 나간 모든 비용)-Gradient Descent/Loss Function(실제값과 예측값 간의 오차 하나씩 계산, 이걸 sum을 하면 cost function)
즉, object function는 negative log likelihood의 평균이기 때문에 마이너스 로그라서 object function을 최소화해야 predict accuracy를 최대로 할 수 있다. -
softmax : exp(x) = exponentiation(e^x =~ 2.718^x), 즉 모두 positive이다. 더 큰 dot product일 수록 더 큰 probability. softmax의 max는 largest x_i라는 뜻이고 soft는 더 작은 x_i의 확률을 여전히 갖고있기 때문에 완전 딱 정확은 아니지만 이정도~ 라는 뜻의 soft를 쓴다고 한다. output sum이 1이 나오게 0과 1사이의 수로 분포를 재배치(normalization, squash)한다고 생각하면 될 듯.
-
Negative log-likelihood(NLL) : -log(x)라고 생각하면 됨. 우리는 Loss의 최솟값을 찾아야 하기 때문에 network가 높은 confidence를 정답 class에 할당하면 우리는 loss의 최솟값을 찾을 확률이 높아지므로 불행지수도 낮아지는 것. 낮은 confidence를 정답 class에 할당하면 반대로 불행지수가 높아짐. 이러한 불행지수 그래프가 nll 그래프인 것이다. loss값을 찾을 수 있는지 없는지 확률을 그려본 그래프라고 할 수 있음. 즉, softmax 값이 1이면 완전 정답이니까 내가 loss값을 못찾을 수는 없는 일임 완전 기뻐서 -log값은 0이고, softmax 값이 0이면 완전 틀려먹어가지고 loss값이 뭔지를 모르겠으니까 loss값을 알기 위해 이거저거 다 써봐야됨. 그래서 loss는 infinity로 감. 완전 불쾌 만땅
-
Gradient : 모든 파라미터들은 조금의 변화도 output에 영향을 미친다. 우리는 Loss 값을 줄이는게 최종 목표이므로 어디로 파라미터가 이동해야 loss값을 줄일 수 있는지 알아낼 수 있다. 이 방향값, 변화량은 미분해서 알 수 있다.
-
Derivative, Partial Derivative : 미분, 편미분은 방법만 할 줄 알면 됨. Gradient Descent를 이해하는데 필요하다. 자세한 설명은 링크에 들어가면 잘 설명되어있다. 우리는 하나의 입력 변수에만 미분을 할 수 있는 것을 편미분이라고 하고, 다변수 함수인 다차원 함수에서는 기울기를 스칼라값이 아닌 벡터값으로 갖고 있고, 이를 Gradient라고 한다. 즉, 우리는 해당 값을 벡터, 스칼라값 행렬로 미분하면서 편미분의 과정을 거쳐 Gradient를 구하게 된다. 경사하강법을 통해 미분 가능한 함수에서 해당 함수의 최소값을 찾을 수 있다.
Error Backpropagation
활성화 함수 사용조건은
1. 미분값을 구할 수 있어야 한다.(기울기가 있어야 한다.)
2. 비선형을 표현할 수 있어야 한다.
Sigmoid의 Gradient Vanishing --> ReLU의 음수 값 네트워크 끊김 --> Leaky ReLU
Loss = |y-RELU(h w)|
-
Optimization
Optimal points(최적의 포인트)를 찾기 위한 시스템 과정. 최적의 포인트란 Maxima가 될 수도 있고 minima가 될 수도 있음.
딥러닝에서는 loss값의 최솟값. 우리가 놓치고 있는 값들을 최소로 줄이고 싶기 때문에 backpropagation으로 parameters gradient들을 구하여 loss를 최소로 줄이는 update를 하는 것이다. -
Gradient Descent
learning rate가 너무 높게 설정하면 수렴이 아닌, 진동 또는 발산할 것. 값에 가까워지는 것 보다는 값이 계속 변하게 될 것. -
CBOW
- Continuous Bag of Words
context vectors의 sum을 사용한다. -
Skip-gram
- 모든 word pair가 독립적이라고 가정함. context word를 예측할 때, 우리는 다른 context word를 고려하지 않음. 이런 추정 방식을 Naïve Bayes 라고 한다. (베이즈 정리 공식)- 나이브 베이즈 분류 (Naive Bayes Classifier)
P(Yes|Overcast) = P(Overcast|Yes) P(Yes) / P(Overcast) : Naive 처럼 순진한 방법인데, 주어진 class에 대해 각각의 특징들이 어떤 상관관계가 있는지 따져봐야 하지만 모두 conditionally independent하다고 가정하는 것. 임의의 bias를 걸어준 것으로도 볼 수 있다. 임의의 두 feature가 있다고 했을 때, joint probability를 각각의 probability의 곱으로 표현 가능하다. - laplace smoothing : 듣도 보도 못한 새로운 값이 data에 등장! 잘 분류하지 못하는 overfitting 문제가 생길 수 있다. 이 때 클래스의 개수에 k배를 해주어 분모에 더하고 분자에는 k를 더한다. 그래서 원래 확률이 0이 될 어떤 feature에 대해 k라는 값을 더해 전체를 0으로 만들어버리는 불상사를 막아줄 수 있다. k에 따라 smoothing의 정도가 달라진다.
- 나이브 베이즈 분류 (Naive Bayes Classifier)
-
Semantic vs Syntactic
Semantic한 것은 말 그대로 의미론적인 것, brother-sister, man-woman 이러한 pair이라고 하면 Syntactic한 것은 Syntax, 문법적인 것. mouse/mice, dollar/dollars, is/be 이러한 느낌이라 Semantic-의미, Syntactic-문법오류 이런식으로 보면 될 것 같다. 코드에서는 Semantic/Syntactic Error가 중요하게 작용하는데, 아무래도 Syntactic Error가 나오면 뭔가 Typo의 문제정도로 끝나겠지만 Semantic Error면 코드 문맥상 말이 안되는 느낌으로 잘못 짠 느낌이어서 오류를 제대로 파악하기 어려울 수 있다. -
Bag of Words
각각의 word들의 등장만을 count한 것. word onset같은거라고 생각하면 되려나, 아무튼 word position이나 index는 상관 안하고 등장 했다! Counter같은 느낌인 것 같다. CBOW에서 Continuous bag of words가 Continuous인 이유는 distributional representation(분산표현)을 사용하고 word vector에서 평균을 사용하기 때문이라고 한다. 즉 CBOW는 주변 단어를 통해 ___ 에 들어갈 단어를 예측하는데 학습시킬 모든 단어들을 one-hot encoding으로 벡터화하고 주변의 단어들이 주어졌을 때 다음 center 단어의 조건부 확률을 최대화한다는 것. Skip-gram은 CBOW와는 반대로 하나의 단어에서 여러 단어를 예측하는 방법. 중심 단어에서 주변 단어를 예측하는 방식인데 CBOW보다 성능이 좋다. CBOW와 마찬가지고 input이 one-hot 으로 들어가고 hidden layer-softmax-output lyaer로 나온다. output layer에서 여러 단어가 나오게 된다는 것이 다른 점이다.
아주 잘 설명되어있는 링크를 첨부하니 다시 읽어보길!
(https://simonezz.tistory.com/35) -
Negative Sampling, Sub-sampling
- Negative Sampling : Softmax 계산이 너무 시간낭비일 때 하는 방법. 주어진 word pair의 score는 높이되 나머지 word pair들은 낮추고 싶을 때. vocab size가 높아질 수록 time complexity가 높아지니까. 즉, 처리할 단어량이 많아질 수록 시간이 오래걸리니까. 그래서 모든 단어들을 dot product하지 않고 랜덤한 negative word sample을 fake로 만드는 거야. relative probability를 내뱉는 softmax보다는 True/False처럼 0, 1을 내뱉는 sigmoid를 써서 corpus가 크면 2-5개 negative sample을 만들고, corpus가 작으면 5-25개 sample을 만든다.
- Sub-sampling은 어떤 단어들이 너무 자주 나오면(예. 'a'나 'the' 같이) 제거할 확률이 커져버리는 것. (sqrt(x/0.001)+1) * 0.001/x 의 그래프.
- DCG : normalize DCG --> IDCG 1점을 맞을 수 있을 때 우리가 몇 점 맞았는지,
- storage, memory, computing -- memory에 가장 올리는게 낫고, 매번 computing을 하는게 제일 느리다. computing을 해서 데이터셋이 너무 크면 storage에 넣어놓거나 memory에 넣어놓는 방법이 있음.
200G 중에 60G를 메모리에 올려 놓고 거기서 계속 학습을 얼마 이상 돌리고, 그 다음을 넣어 돌리고, 이런 방식이 전체 하나 쫙 다 돌리는 것보다는 편리하다. 학습 시간은 줄이기 위해 뭐든 해야 함.
