[CS] 메모리 파편화 및 접근 효율성, 캐시 히트와 미스
알고리즘 문제를 푸는 도중에 분명 똑같은 코드인데 코드의 위치만 바뀌었을 때 메모리 사용량이 크게 늘어나며 오답처리가 되는 현상을 겪었다.
왜 이러한 결과가 나타났는지 찾아보는중 CS지식과 관련하여 흥미로운 사실들을 배우게 되어 정리한다.
배열의 초기화 위치와 사용하는 위치에 따라 메모리 사용량이 크게 차이나는 것을 확인할 수 있었다.

- Softeer 출퇴근길 문제
https://softeer.ai/practice/6248/talk
문제는 단방향 그래프 형태의 루트가 주어진다. 이때 가능한 출퇴근 루트 중에서 출근과 퇴근시 모두 방문가능한 노드의 개수를 찾는 문제이다.
강한연결요소를 구하는 알고리즘인 코사라주 알고리즘을 적용하면 풀 수 있었다.
이 과정에서 dfs를 총 4번이나 돌려야했고 각각의 dfs에서 방문 지점을 저장할 visit배열을 4개를 먼저 선언하고 차례로 사용했다.
처음 코드
#softeer
import sys
sys.setrecursionlimit(10**6)
n,m = map(int,sys.stdin.readline().split())
graph = [[] for _ in range(n+1)]
graph_rev = [[]for _ in range(n+1)]
for _ in range(m):
i,j = map(int,sys.stdin.readline().split())
graph[i].append(j)
graph_rev[j].append(i)
s,t = map(int,sys.stdin.readline().split())
def dfs(cur,g,visit):
if visit[cur] == 1:
return
visit[cur] = 1
for i in g[cur]:
dfs(i,g,visit)
# ---------------- 주목할 부분 시작!! --------------------------
visit1 = [0 for _ in range(n+1)]
visit2 = [0 for _ in range(n+1)]
visit3 = [0 for _ in range(n+1)]
visit4 = [0 for _ in range(n+1)]
visit1[t] = 1
dfs(s,graph,visit1)
visit2[s] = 1
dfs(t,graph,visit2)
dfs(s,graph_rev,visit3)
dfs(t,graph_rev,visit4)
# ---------------- 주목할 부분 끝!! --------------------------
count = 0
for i in range(1,n+1):
if visit1[i] and visit2[i] and visit3[i] and visit4[i]:
count+=1
print(count-2)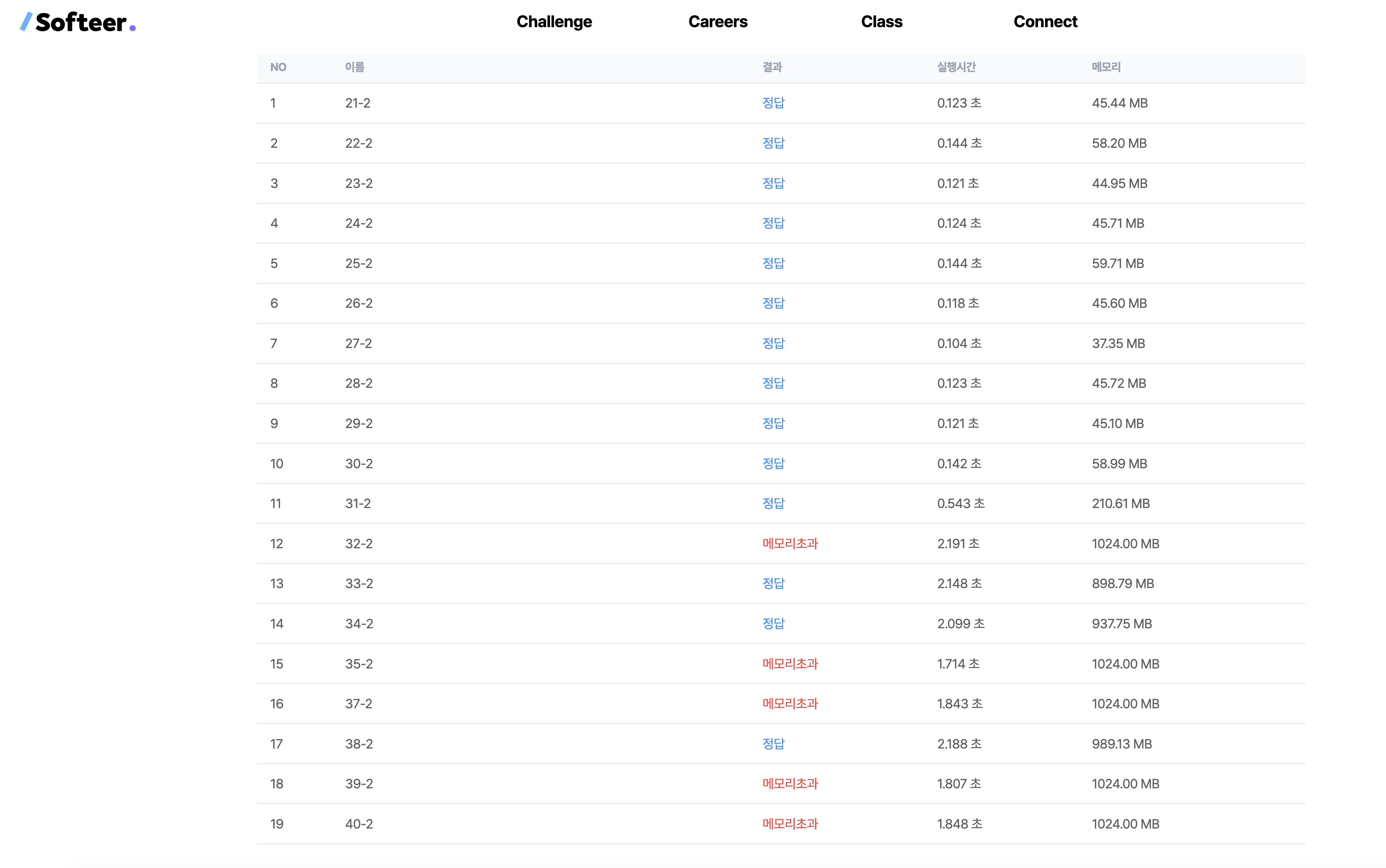
제출결과 특정 메모리 케이스에서 메모리 초과가 나타나 fail하는 것을 확인할 수 있었다..
수정한 코드
이후 코드를 아래와 같이 visit배열을 선언 후 바로 사용하는 형태로 순서만 바꾸어주었더니 메모리 초과가 발생하지 않았다.
왜 그럴까...?
#softeer
import sys
sys.setrecursionlimit(10**6)
n,m = map(int,sys.stdin.readline().split())
graph = [[] for _ in range(n+1)]
graph_rev = [[]for _ in range(n+1)]
for _ in range(m):
i,j = map(int,sys.stdin.readline().split())
graph[i].append(j)
graph_rev[j].append(i)
s,t = map(int,sys.stdin.readline().split())
def dfs(cur,g,visit):
if visit[cur] == 1:
return
visit[cur] = 1
for i in g[cur]:
dfs(i,g,visit)
# ---------------- 주목할 부분 시작!! --------------------------
visit1 = [0 for _ in range(n+1)]
visit1[t] = 1
dfs(s,graph,visit1)
visit2 = [0 for _ in range(n+1)]
visit2[s] = 1
dfs(t,graph,visit2)
visit3 = [0 for _ in range(n+1)]
dfs(s,graph_rev,visit3)
visit4 = [0 for _ in range(n+1)]
dfs(t,graph_rev,visit4)
# ---------------- 주목할 부분 끝!! --------------------------
count = 0
for i in range(1,n+1):
if visit1[i] and visit2[i] and visit3[i] and visit4[i]:
count+=1
print(count-2)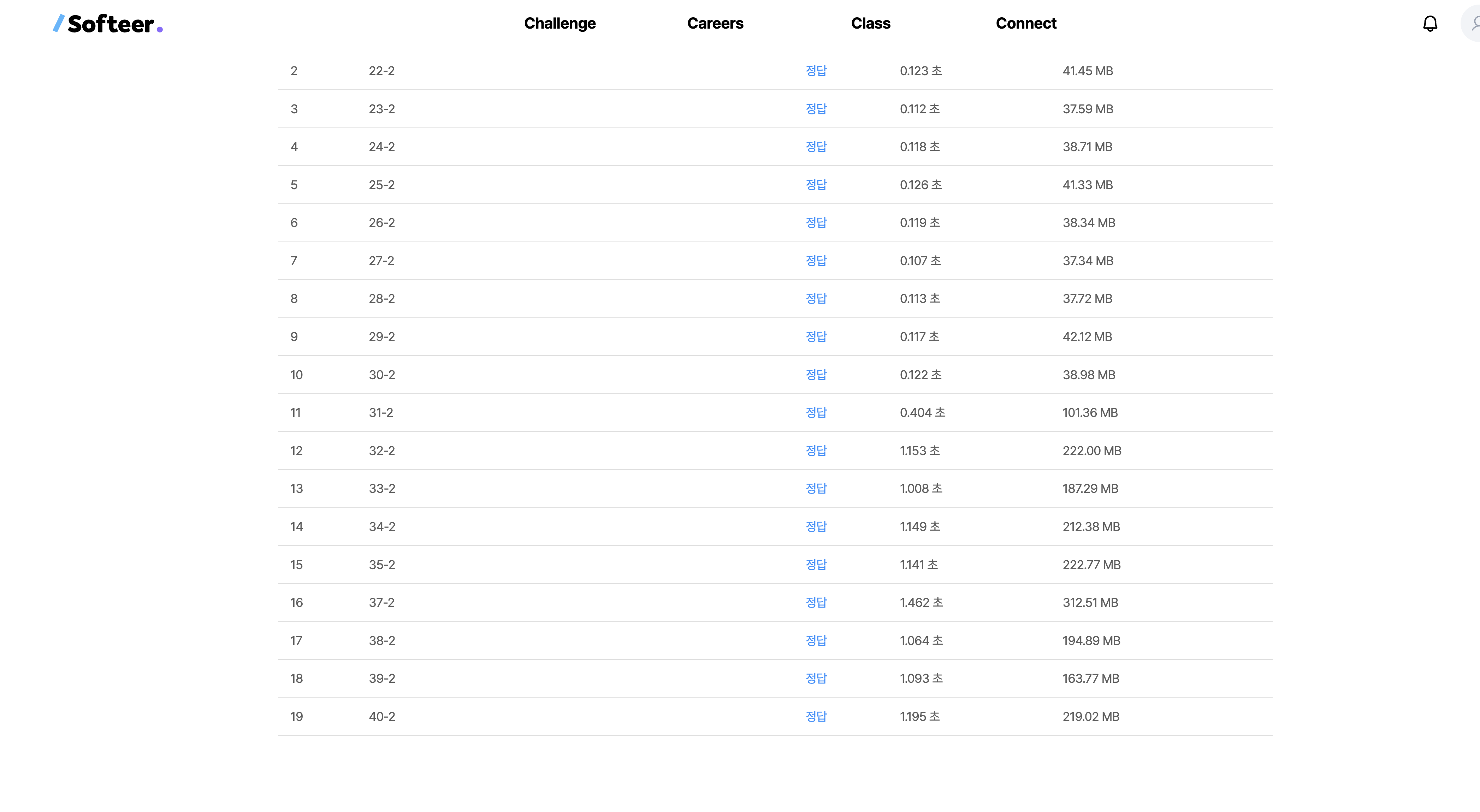
결론부터 이야기하자면 "메모리 파편화" 라는 현상에 의해 메모리가 비효율적으로 관리되었기 때문이였다.
메모리 파편화란 무엇인가?
메모리 파편화는 프로그램이 메모리를 할당하고 해제하는 과정에서 사용 가능한 메모리가 여러 조각으로 나뉘는 현상이다. 이는 크게 두 가지로 나눌 수 있다.
내부 파편화(Internal Fragmentation):
메모리 블록이 할당될 때 필요한 크기보다 더 큰 블록이 할당되어 사용되지 않는 메모리 공간이 발생하는 현상이다.
예를 들어, 8KB의 메모리 블록이 필요하지만, 메모리 관리 시스템이 16KB 블록만 할당할 수 있다면, 8KB는 사용되지 않고 낭비되게 된다.
외부 파편화(External Fragmentation):
메모리 블록이 해제된 후, 여러 개의 작은 빈 공간이 메모리에 흩어져 있어 새로운 큰 메모리 할당 요청을 처리할 수 없는 현상이다.
예를 들어, 여러 개의 작은 메모리 블록이 해제되어 비어 있는 공간이 있지만, 이 공간들이 연속되지 않아 큰 메모리 블록을 할당할 수 없게 된다.
메모리 파편화가 발생하는 이유
메모리 파편화는 주로 동적 메모리 할당과 해제 과정에서 발생한다. 프로그램이 실행되면서 다양한 크기의 메모리를 요청하고 해제할 때, 메모리 관리자는 이러한 요청을 처리하기 위해 메모리를 할당한다. 시간이 지나면서, 메모리의 할당 및 해제 패턴이 복잡해지면, 연속된 메모리 공간을 유지하기 어려워져 파편화가 발생한다.
메모리 사용량이 증가한 이유
-
동시 메모리 할당:
첫 번째 코드에서는 네 개의 visit 배열을 한꺼번에 선언한다. 이때 최대 몇십만 크기의 배열이므로, 큰 메모리 공간을 동시에 요청하게 된다. 이렇게 한꺼번에 많은 메모리를 할당하면, 메모리 관리자가 이를 효율적으로 처리하기 어려워지며, 메모리 사용량이 급격히 증가할 수 있다고 한다.
-
메모리 접근 패턴의 비효율성(캐시 히트/미스) :
한꺼번에 할당된 배열들은 메모리 상에서 서로 인접하지 않거나, 메모리의 조각난 공간에 배치될 가능성이 크다. 이로 인해 메모리 접근이 비효율적으로 이루어지며, 캐시 적중률(cache hit rate)이 낮아지며 캐시 미스가 발생하게 된다. 이는 성능 저하를 초래할 수 있다.
-
파편화:
한꺼번에 큰 메모리를 할당받고 이를 사용하는 과정에서, 메모리 파편화가 발생할 수 있다. 메모리 파편화란 사용되지 않는 작은 메모리 조각들이 여기저기 흩어져 있는 상태를 의미하며, 필요한 크기의 연속된 메모리를 확보하기 어렵게 만든다. 이는 메모리 사용량이 증가하는 원인이 된다.
결론
결국, 메모리 초과 발생 코드와 발생하지 않는 코드의 차이는 메모리 할당과 접근 패턴의 차이로 인해 나타났다.
첫 번째 코드에서처럼 한꺼번에 큰 메모리 공간을 요청하고 접근할때 메모리 접근 패턴이 비효율적이라는 것을 알 수 있었다.
반면, 두 번째 코드에서는 메모리를 순차적으로 할당하고 바로 사용함으로써, 메모리 공간의 연속성을 유지하고, 메모리 관리자가 효율적으로 메모리를 할당할 수 있게 되어 메모리 효율성이 증가했다. 또한 이에 따라 캐시 히트율이 증가하며 전체적인 코드 성능도 높아졌다고 볼 수 있다.
이번 경험을 통해 메모리 동적 할당시 할당 후 바로 사용하는 것이 메모리 접근 효율성에서 큰 차이가 날 수 있다는 것을 알 수 있었다. 물론 작은 크기의 할당은 큰 차이가 없겠지만 위 문제 처럼 사이즈가 몇십만 단위의 크기에서는 메모리 사용량의 차이가 4~5배 가까이 증가 하는 것을 직접 눈으로 확인하며 대규모 프로젝트의 경우 이런 메모리 할당과정 하나하나를 최적화 하는 것이 매우 중요하겠다고 느꼈다.
c언어로 여러 프로젝트를 진행하며 메모리 효율성을 항상 숙지하고 효율적인 코드를 짜기 위한 부분을 많이 배웠는데 파이썬도 GC가 작동을 하지만 실제 코드 설계 상으로도 메모리 효율성을 확인해야 된다는 것을 알 수 있었다.
