본 포스팅은 Standford University의 'CS231n' 강의로 공부한 것을 정리했습니다.
Lecture 1 | Introduction to Convolutional Neural Networks for Visual Recognition
History of Computer Vision
- Obscura(‘1600, Renaissance): 초창기의 카메라, 핀홀 카메라 이론 기반
- “what was the visual processing mechanism like in primates, in mammals”(Hubel & Wiesel, 1959): 전기생리학을 이용한 표유류의 시각 메커니즘 연구. 고양이 뇌에 전극을 꽂아 실험 진행. 어떤 자극을 줘야 일차 시각 피질의 뉴런이 격렬하게 반응하는지 관찰. → 실험을 통해 경계(edges)가 움직이면 반응하는 세포를 발견.
이미지 처리는 방향의 가장자리(oriented edges) 라는 시각 세계의 단순한 구조에서 시작하여 정보가 시각적 처리 경로를 따라 이동하며, 뇌는 복잡한 시각 세계를 인식할 수 있을 때까지 시각적 정보의 복잡성을 증가시키는 방식으로 이루어져있다는 것을 발견.
1. Object recognition
60/70/80년대 : 컴퓨터 비전으로 할 수 있는 일을 고민한 시대
- Block world(Larry Roberts, 1963): 컴퓨터 비전 분야 최초의 박사 학위 논문. 눈에 보이는 사물들을 기하학적 모양으로 단순화. 눈에 보이는 세상을 인식하고 그 모양을 재구성 하는 것이 목표.

- “The Summer Vision Project”(in MIT, 1966): project purpose, “시각 시스템 전반을 구현하기 위해 프로젝트 참가자들을 효율적으로 이용하는 것”
- Stages of Visual Representation(David Marr, 1970s)
1) 저자가 비전을 무엇이라 생각하는지, 어떤 방향으로 CV 나아가야 하는지, 컴퓨터가 비전을 인식하기 위해 어떤 방향으로 알고리즘을 개발해야 하는지에 대해 기술한 책.
2) 이미지를 가지고 최종적인 3D 표현에 도달하기 위해서는 몇 단계의 과정을 거쳐야 한다고 주장.
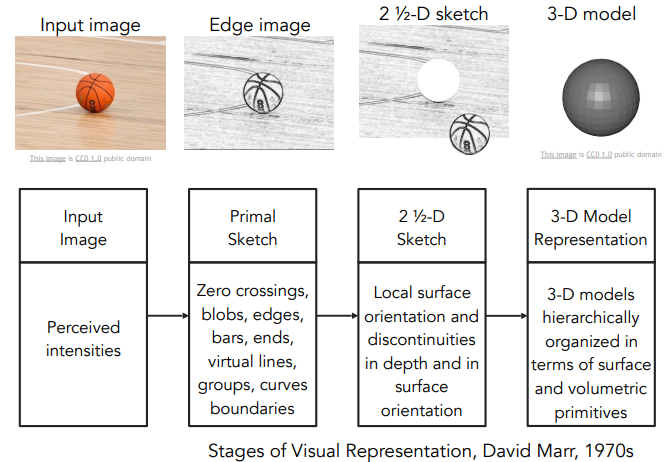
- Pictorial Structure(Fischler and Elschlager, 1973), Generalized Cylinder(Brooks & Binford, 1979): "어떻게 블록세계를 뛰어넘어 실제 세계를 인식하고 구현할 수 있을까?" → “모든 객체는 단순한 기하학적 형태로 표현할 수 있다” 개념 주장. 단순한 모양과 기하학적 구성을 이용해 복잡한 객체를 단순화 하는 방법.
- David Lowe(1987): 어떻게 하면 단순한 구조로 실제 세계를 재구성/인식 할 수 있을지 고민. 면도기를 인식하기 위해 선, 경계, 직선, 그리고 이들의 조합으로 구성.

Summary
Block world, Pictorial Structure, Generalized Cylinder 모두 눈에 보이는 사물을 기하학적 구성으로 단순화 하는데 집중함.
2. Object segmentation
1999/2000년대: 객체 인식이 너무 어렵다면, 이미지를 가져와 픽세를 의미있는 영역으로 그룹화 하는 작업인 이미지 분할(image segmentation)부터 하자는 생각
→ “기계학습”, 특히 “통계적 기계학습”이 탄력을 얻음. "Support Vector Machine", "Boosting", "Graphical models", 초기 "Neural Network" 등이 있음.
- Normalized Cut(Shi & Malik, 1997): 영상분할 문제를 해결하기 위해 그래프 이론 도입.
- Face Detection(Viola & Jones, 2001): AdaBoost algorithm를 이용해 실시간 얼굴 인식에 성공. → Fujifilm(2006): 실시간 얼굴인식 지원 최초의 디지털카메라
- “SIFT” & Object Recognition(David Lowe, 1999): “특징 기반 객체 인식 알고리즘”, 특징 중 일부는 변화에 강인하고 불변하다는 점을 발견. 이와 같은 중요 특징을 찾아내고 그 특징을 다른 객체에 매칭 하는 원리.
- Spatial Pyramid Matching(Lazebnik, Schmid & Ponce, 2006): 장면 전체 인식. 특징을 잘 뽑아내면 특징이 일종의 “단서”를 제공한다는 아이디어. 이미지 내의 여러 부분과 여러 해상도에서 추출한 특징을 하나의 특징 기술자로 표현하고 Support Vector Algorithm 적용. → 이러한 연구들은 사람 인식에도 탄력을 줌.
- Histogram of Gradients (HoG) (Dalal & Triggs, 2005), Deformable part models(Felzenswalb, McAllester, Ramanan, 2009): 사람 인식. 어떻게 해야 사람의 몸을 현실적으로 모델링 할 수 있을지에 대한 연구.
3. Benchmark Dataset
2000년대 초: 객체인식 과정을 측정할 수 있게 하는 Benchmark Dataset을 갖기 시작.
- PASCAL Visual Object Challenge(VOC)
가장 영향력 있는 데이터셋 중 하나. 20개의 클래스, 클래스당 수천 수만 개의 이미지가 있음. 그러나 Graphical Model, SVM, AdaBoost 같은 기계학습 알고리즘들이 트레이닝 과정에서 Overfit 함. → (Group of Princeton, Stanford): “우리는 이 세상의 모든 객체를 인식할 준비가 되었는가?”
Overfit의 원인 중 하나: 복잡한 시각 데이터. 모델의 입력은 복잡한 고차원 데이터이고, 이로 인해 모델을 fit 하기 위해서 더 많은 파라미터가 필요함. 학습 데이터가 부족하면 overfiting이 더 빠르게 발생하고 일반화 능력이 떨어지는 문제점이 발생함.
- 이 세상의 모든 것을 인식하고 싶다
- 기계학습의 Overfiting 문제를 극복해보자
→ 위와 같은 동기를 바탕으로 ImageNet 프로젝트가 시작됨
- ImageNet 프로젝트(약 3년)
모델을 학습 시킬 수 있고 Benchmark도 가능한 구할 수 있는 모든 이미지를 담은 가장 큰 데이터셋을 만드는 것이 목표.
인터넷에서 다운 받은 수십억 장의 이미지를 WordNet이라는 Dictionary로 정리. (WordNet: 수천 가지의 객체 클래스 존재), Clever Crowd Engineering trick 도입(Amazon Mechanical Turk에서 사용하는 이미지의 정렬, 정제, 레이블 등 제공하는 플랫폼) → 그 결과 ImageNet은 대략 15만 장에 달하는 이미지와 22만 가지의 클래스 카테고리를 보유하게 됨 - ILSVRC (since 2009~)
ImageNet을 Benchmark에 활용하기 위해 주최된 국제 규모 대회. 대회를 위해서 1000개의 객체에서 140만 개의 test set 이미지를 엄선. 대회의 목적은 이미지 분류 문제를 푸는 알고리즘들을 테스트하기 위함.
(하단) Image Classification Challenge의 결과(2010~2015). x은 연도, y축은 오류율. 오류율이 점차 감소.
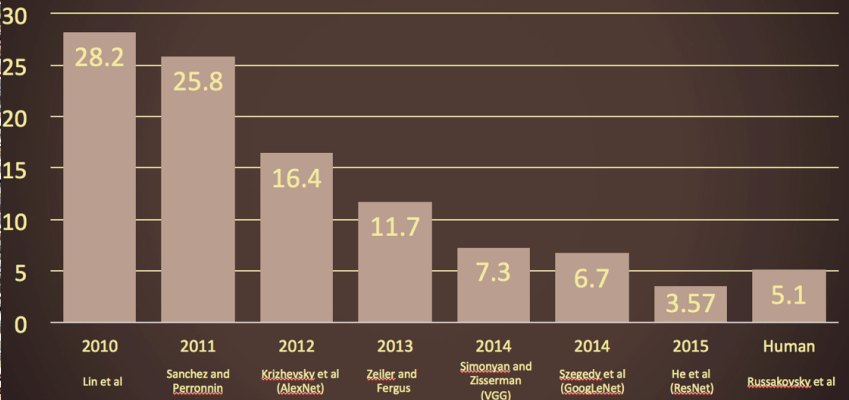
- 2012년: 오류율이 10% 가량 떨어짐. 우승에 성공한 알고리즘은 convolutional neural network(CNN) 모델. 컴퓨터 비전 분야의 진보를 이루어냄.
CS231n Overview
- image classification: 알고리즘이 이미지 한 장을 보고 몇 개의 고정된 카테고리에서 하나의 정답을 고름. 다양한 환경에서 적용 가능.
- object detection: 객체가 어디에 있는지 정확한 위치에 네모박스를 그려야 됨.
- image caption: 이미지가 입력으로 주어지면 이미지를 묘사하는 적절한 문장을 생성해야 됨.
Image Challenge의 우승자

- NEC-UIUC(Lin et al, 2011): 여전히 계층적(hierarchical), 특징 추출 → 지역 불변 특징 계산 → Pooling → … 여러 단계를 거침 … → 최종적 특징 기술자를 Linear SVM에 태움
- 7-Layer CNN, (aka) AlexNet, Supervision (Alex Krizhevsky, Ilya Sutskever, 2012)
- GoogleNet(Google), VGG(Oxford): 네트워크가 훨씬 깊어짐
- MSRA(2015): Residual Network Layer 수가 152개에 육박.
- 2012년에 CNN의 시대가 도래했고, 이후 CNN을 개선하고 튜닝하려는 여러 시도가 존재하였음.
- CNN은 2012년에 ImageNet Challenge을 통해 유명해졌으나, 실제로는 1998년에 개발되었다. (1998년의 CNN) 숫자 인식을 위한 CNN, 자필 수표 자동 판독과 우편주소 자동인식에 CNN을 적용하고자 함. 이미지를 입력 받아 숫자와 문자를 인식하는 CNN 개발.
- 알고리즘이 현대에 와서 유명해진 이유?
- 90년대 이래로 컴퓨터의 계산 능력이 향상됨.
- graphics processing units의 진보

gaeul0024