본 포스팅은 Standford University의 'CS231n' 강의로 공부한 것을 정리했습니다.
Lecture 5 | Convolutional Neural Networks
History of CNN
Mark I Perceptron Machine
- Frank Rosenblatt, ~1957: Mark I Perceptron Machine
- the first implementation of the perceptron.
- 퍼셉트론은 와 유사한 함수를 사용하나 출력 값이 1 또는 0이라는 차이가 있다. 또한 가중치 를 갱신하는 Update Rule이 존재한다. 이 Update Rule은 역전파(Backpropagation)와 유사하나 당시에는 역전파라는 개념이 없어 가중치를 수동으로 맞추는 방식이었다.
Adaline & Madaline
- Widrow and Hoff, ~1960: Adaline and Madaline
- the first Multilayer Perceptron Network
- 비로소 Neural Network의 구색을 갖추기 시작하였으나 여전히 역전파와 같은 학습 알고리즘이 전무한 상태이다.
The First Back-Propagation
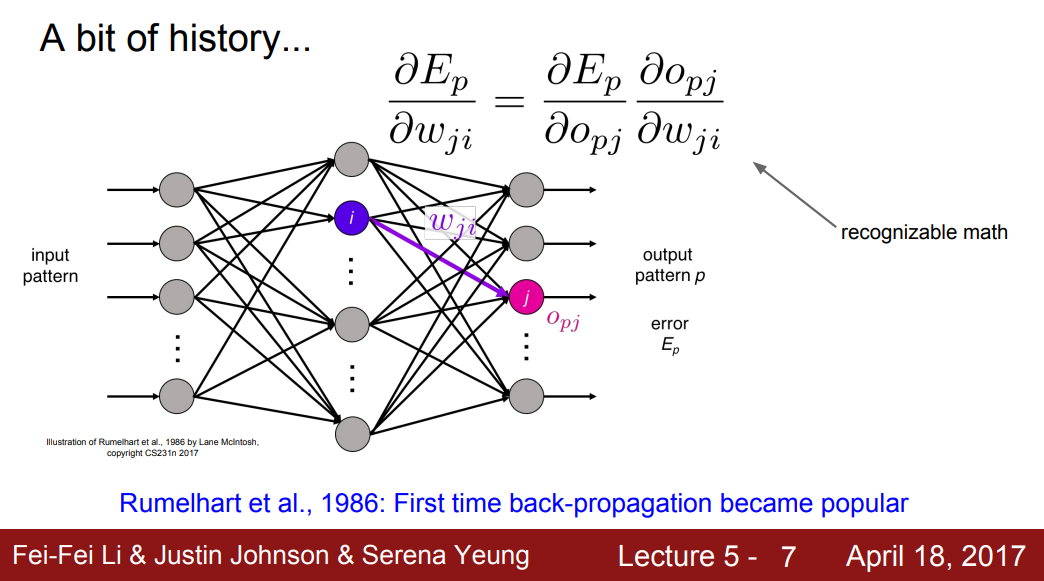
- Rumelhart et al., 1986: First time back-propagation became popular
- 현대에 사용하는 Chain rule과 Update rule와 유사한 형태이다.
- 최초로 Network를 학습하는 것에 관한 개념이 정립되기 시작하였으나 Neural Network를 확대시키지는 못하였다. 한동안 새로운 이론이 나오지 못하였고, 널리 사용되지도 않았다.
(Deep Learning) Reinvigorated research
- Hinton and Salakhutdinov, 2006: Reinvigorated research in Deep Learning
- 2006년, Geoff Hinton과 Ruslan Salakhutdinov가 최초로 논문에서 심층신경망(Deep Neural Network, DNN)의 학습 가능성을 선보였다.
- 역전파가 가능하기 위해서는 세심한 초기화를 요구하므로 전처리 과정이 필요하였고, RBM을 이용해 각 히든레이어의 가중치를 학습하였다. 이후 초기화된 히든레이어를 이용해 전체 신경망에 역전파를 적용하거나 미세 조정(fine tune)하는 방식이었다.
Restricted Boltzmann Machines(RBM)이란 제한된 볼츠만 머신이라는 의미이며, Generative Model이라고도 부른다. RBM은 두 개의 층(입력층 1개, 은닉층 1개)으로 구성되어있기 때문에 심층 신경망이 아니다. 다만 심층 신뢰 신경망(DBN:Deep Belief Network)을 구성하는 요소로 사용된다. 초보자용 RBM(Restricted Boltzmann Machines) 튜토리얼
(DNN) Speech Recognition
- George Dahl, Dong Yu, Li Deng, Alex Acero, 2012: Context-Dependent Pre-trained Deep Neural Networks for Large Vocabulary Speech Recognition
- Acoustic modeling(음향 모델링)과 Speech recognition(음성 인식)에 관한 NN 연구를 진행한 Hinton Lab에서 기반하였다. Acoustic Modeling using Deep Belief Networks(Abdel-rahman Mohamed, George Dahl, Geoffrey Hinton, 2010)
- 대규모 어휘 음성 인식을 위한 심층 신경망, 음성 인식에서 좋은 성능을 보였다.
(DNN) ImageNet classification
- Alex Krizhevsky, Ilya Sutskever, Geoffrey E Hinton, 2012: Imagenet classification with deep convolutional neural networks
- 영상 인식 연구의 기념비적인 논문으로 ImageNet Classification에서 최초로 NN을 사용하였다. AlexNet은 ImageNet benchmark의 Error를 극적으로 감소시켰다. 이후로 ConNets는 널리 사용되고 있다.
How did CNN become famous?
Receptive Fields of Single Neurones
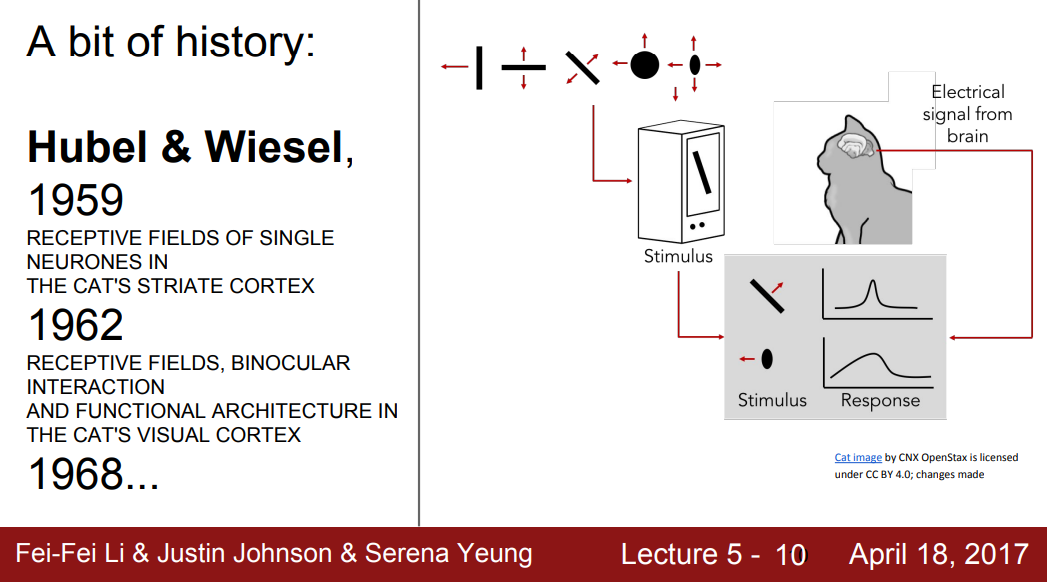
- 1950년대, Hubel & Wiesel의 일차시각피질 뉴런에 관한 연구가 선행되었다.
- 해당 연구는 고양이의 뇌에 전극을 꽂고 다양한 자극을 주는 실험이 진행되었다. 그 결과 뉴런이 oriented edges와 shapes에 반응한다는 사실을 알게 되었다.
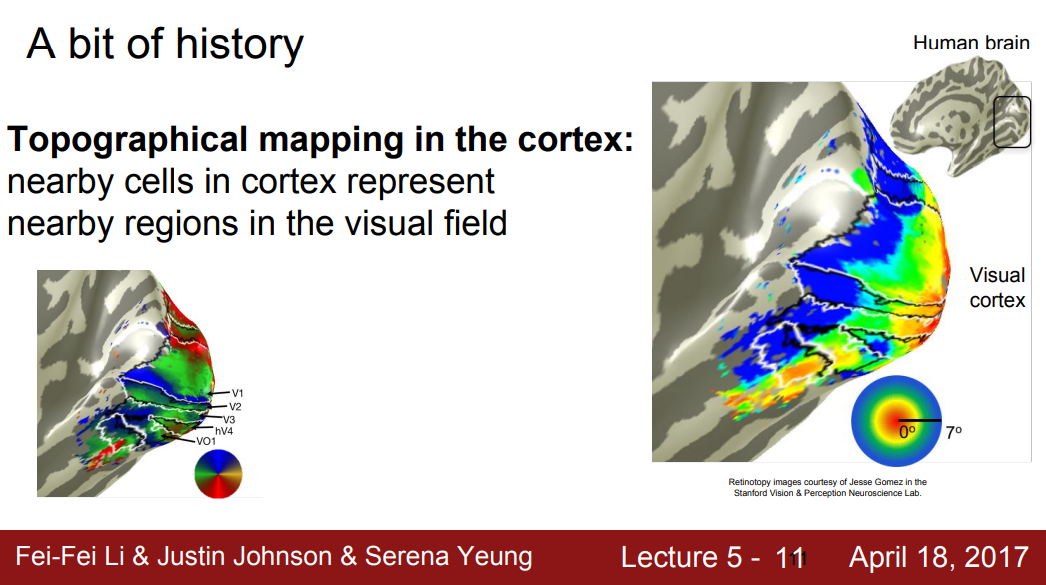
- 결론1) 피질 내부에 지형적인 매핑(topographical mapping)의 존재
- 피질 내 서로 인접해 있는 세포들은 visual field 내에 어떠한 지역성을 띄고 있다.
- 오른쪽 그림을 보면 해당하는 spatial mapping을 볼 수 있고, 중심에서 벗어난 파란색 지역도 관찰 가능하다.
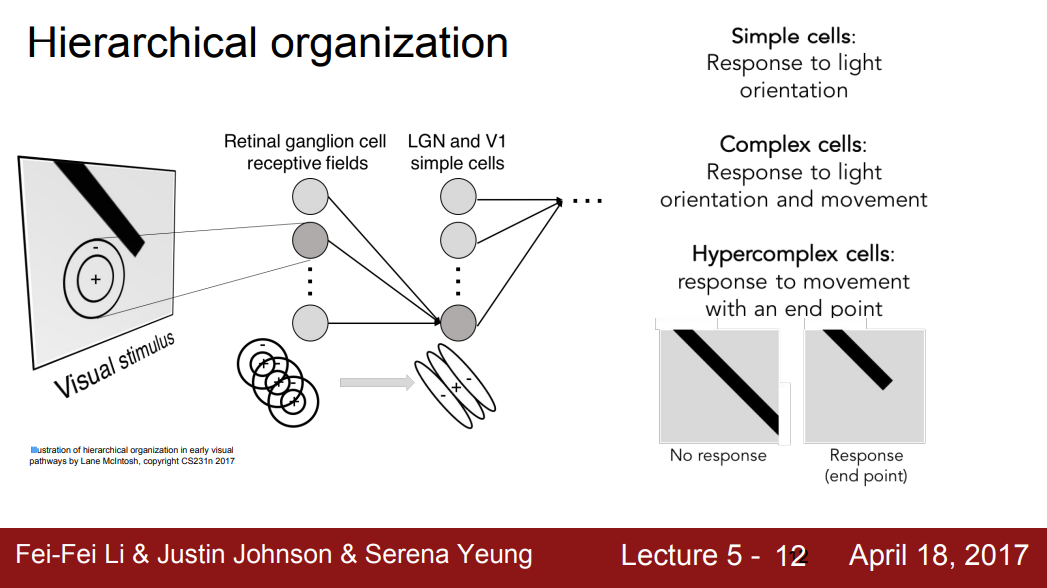
- 결론2) 뉴런들이 계층구조를 지닌다는 사실 발견
- 시각 신호가 가장 먼저 도달하는 곳이 Retinal Ganglion이라는 사실 발견하였다.
- Retinal Ganglion Cell은 원형으로 생긴 지역으로, 상위에는 다양한 edges와 빛의 방향에 반응하는 Simple cells가 있다. 이 Simple Cells는 움직임에 반응하는 Complex cells와 연결되어 있다.
- 즉, 복잡도가 증가함에 따라, hypercomplex cells는 끝 점(end point)과 같은 것에 반응하게 된다.
- 이러한 결과로부터 "corner"나 "blob"에 대한 아이디어를 얻기 시작하였다.
Neocognitron
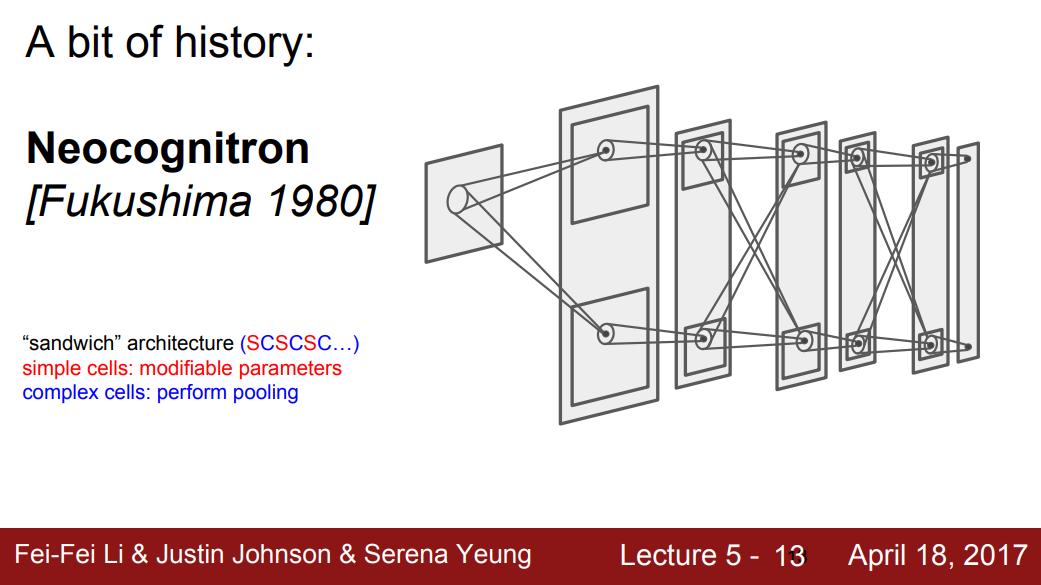
- Fukushima, 1980: Neocognitron
- Hubel과 Wiesel이 발견한 simple/complex cells의 아이디어를 사용한 최초의 NN이다. Simple/complex cells를 교차시켰다. (SCSCSC...)
- Simple cells는 학습 가능한 parameters를 가지고, Complex cells는 pooling으로 구현하였는데 이는 작은 변화에 강인하다.
Document Recognition
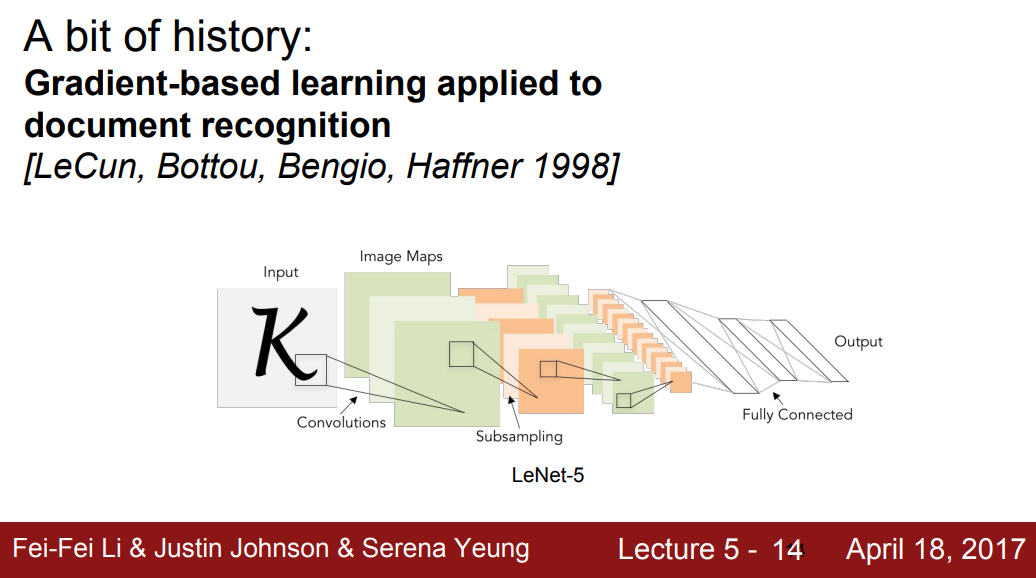
- LeCun, Bottou, Bengio, Haffner, 1998: Gradient-based learning applied to document recognition
- 최초로 NN을 학습하기 위해 역전파와 gradient-based learning을 적용하였다.
- 이는 문서인식에 적용되었으며 우편번호의 숫자를 인식하는 작업에서 잘 동작하였다. 이후 실제 우편 서비스에서 우편번호 인식에 널리 사용되었다.
- 그러나 해당 Network를 확장시키는 것을 어려웠고, 숫자라는 데이터는 너무나 단순하였다.
(DCNN) ImageNet Classification
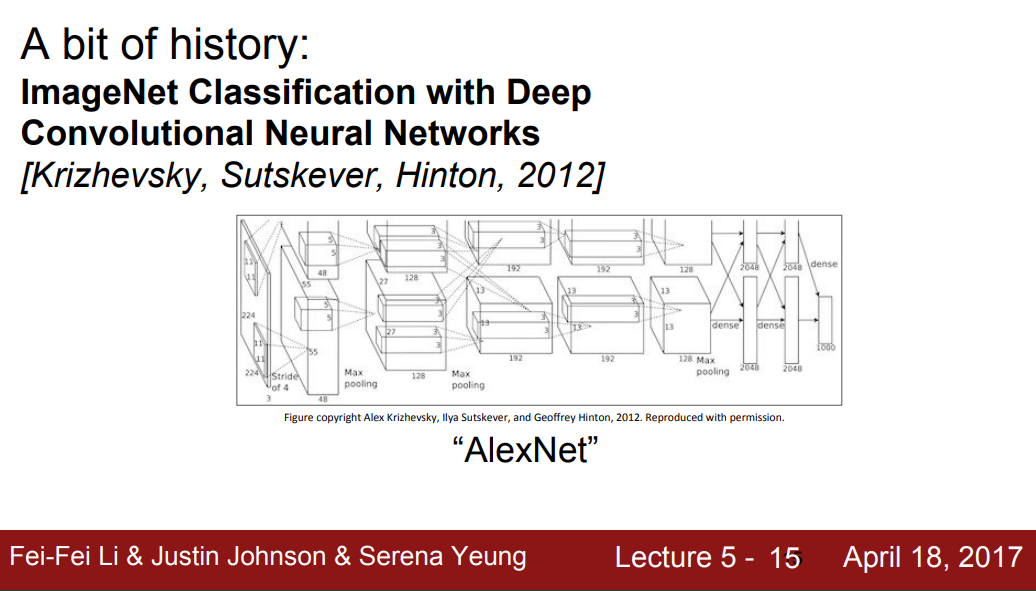
- Krizhevsky, Sutskever, Hinton, 2012: ImageNet Classification with Deep Convolutional Neural Networks
- Yann LeCun의 CNN과 크게 달라진 점은 없으나 보다 크고 깊어졌다. 따라서 ImageNet dataset와 같은 대규모 데이터를 활용할 수 있다. (GPU의 힘도 있음)
Nowadays

- ConvNets은 널리 사용되며, AlexNet의 ImageNet 데이터 분류 결과를 살펴보자면 이미지 검색에 우수한 성능을 보이고 있다.
- 학습된 특징이 유사한 것을 매칭시키는데 아주 강력하다.

- in Detection : ConvNet을 사용하여 영상 내 객체의 위치를 찾아내고 네모박스를 정확하게 그린다.
- in Segmentation : 객체를 구별하는데 픽셀 하나 하나에 모두 레이블링을 한다.

- in self-driving cars : 대부분의 작업은 GPU가 수행할 수 있으며, 병렬처리를 통하여 ConvNet을 효과적으로 훈련하고 실행 가능하다.
- 자율 주행에 들어가는 임베디드 시스템 내에서도 동작할 뿐만 아니라 최신 GPU에서도 가능하다.
- face-recognition : 얼굴 이미지를 입력으로 받아 이 사람이 누구인지에 대한 확률을 추정할 수 있다.
- in video: 비디오에 활용하면 단일 이미지의 정보 뿐만 아니라 시간적 정보도 함께 활용할 수 있다.

- pose-recognition: 다양한 관절을 인식할 수 있으며, 다양하고 비정형적인 포즈를 잡는 것도 가능하다.

- 의학 영상을 가지고 해석하거나 진단할 수 있다.
- 은하를 분류하거나 표지판을 인식할 수 있다.

- 최근의 Kaggle Chanllange에서는 고래를 분류하는 것도 있었다.
- 공항지도를 가지고 길과 건물을 인식할 수 있다.

- image captioning : Classification과 Detection에서 좀 더 나아간 방법으로 주어진 이미지에 대한 설명을 문장으로 만들어내는 기능이다.

- NN을 이용해 예술작품을 만들 수 있다. 원본 이미지를 기반으로 특정 화풍으로 다시 그려주는 알고리즘도 존재한다.
Convolutional Neural Networks
Fully Connected Layer
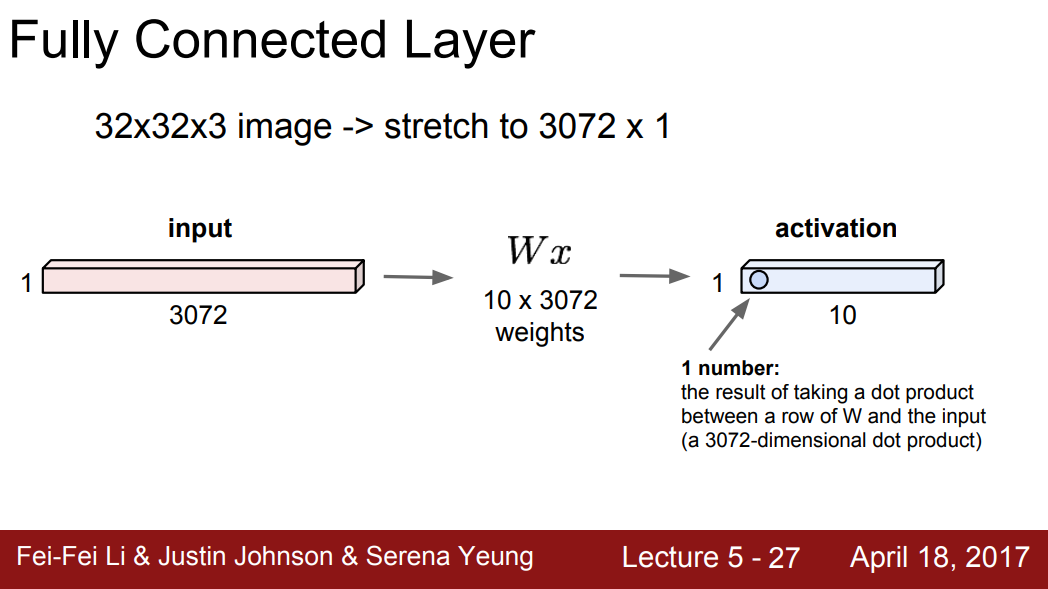
- Fully Connected Layer는 이미지 형태를 보존하지 않는다.
- 지금까지 학습한 데이터를 기반으로 분류하는 층으로, CNN의 가장 마지막에 출력값을 얻기 위해 활용되는 층으로 사용된다.
- 벡터를 가지고 연산하므로 입력값으로 들어온 32x32x3 이미지를 3072차원의 벡터로 변환한다. (32x32x3 image -> stretch to 3072x1)
- 가중치 를 벡터와 곱한다. ()
- 10개의 행으로 구성된 Activaton을 얻는다. 이때 얻게 되는 숫자가 해당 Neuron의 값이다. 예제의 경우 10개의 Neuron을 얻게 된다.
Convolution Layer
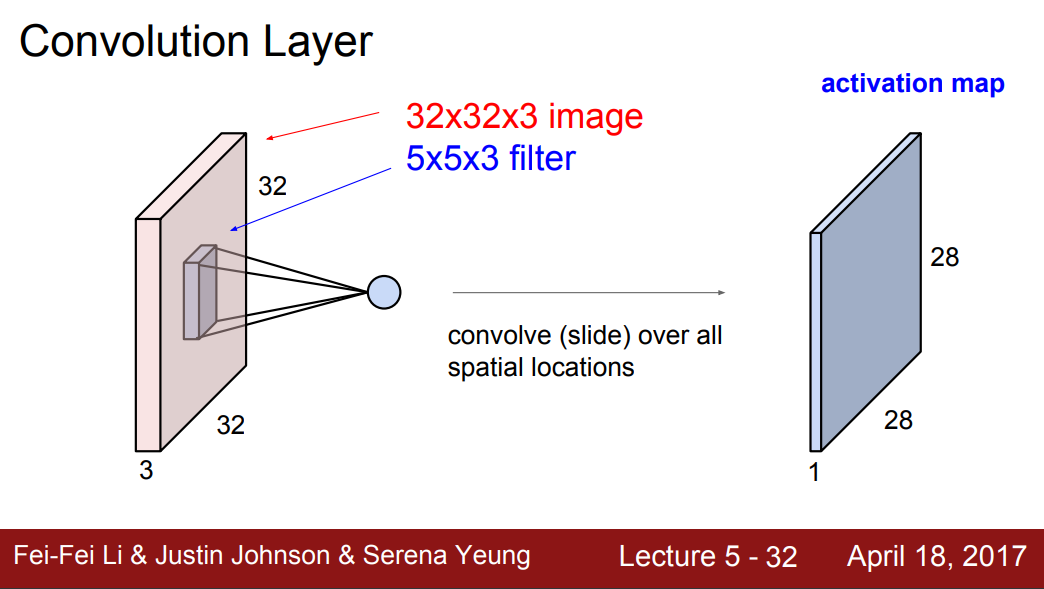
- Convolution Layer는 이미지 형태를 보존한다.
- 입력된 데이터에서 테두리, 선, 색 등을 감지하기 위한 층이다.
- 필터로 이미지를 슬라이딩 하며 공간적 내적을 수행하게 된다.
Filter가 1개인 경우
- 필터는 입력의 depth 만큼 확장 되어야 하므로 32x32x3의 spatial structure을 가진 image에 5x5x3 필터로 convolution 해준다.
- 행렬곱을 위해 가중치 행렬 을 전치 행렬로 바꾸고, input data 와 곱한다. 이후 편향 를 더해준다. () 결과는 내적을 통해 계산된다.
- 따라서 28x28x1 크기의 activation map이 나온다.
Convolution Layer의 input data를 필터가 sliding하며 convolution한 값을 feature map (또는 activation map)이라고 한다. Activation map의 크기와 수는 stride(보폭)과 padding, filter 값에 따라 상이하다.
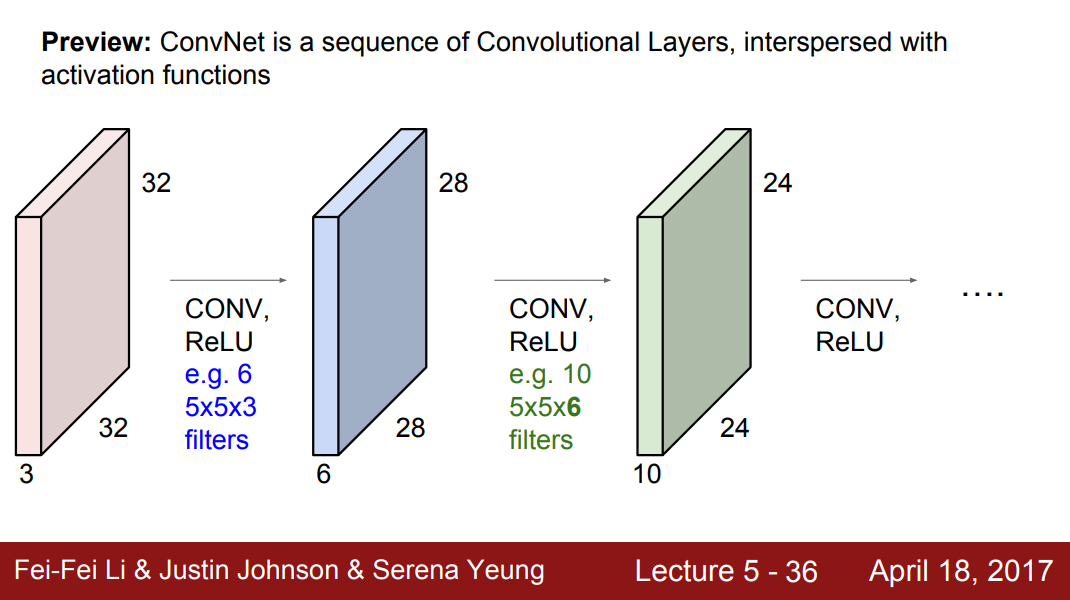
Filter가 여러 개인 경우

- 32x32x3의 spatial structure을 가진 image, 5x5x3 filter 6개 -> 28x28x6 size activation map이 생성되었다.
CNN 수행과정
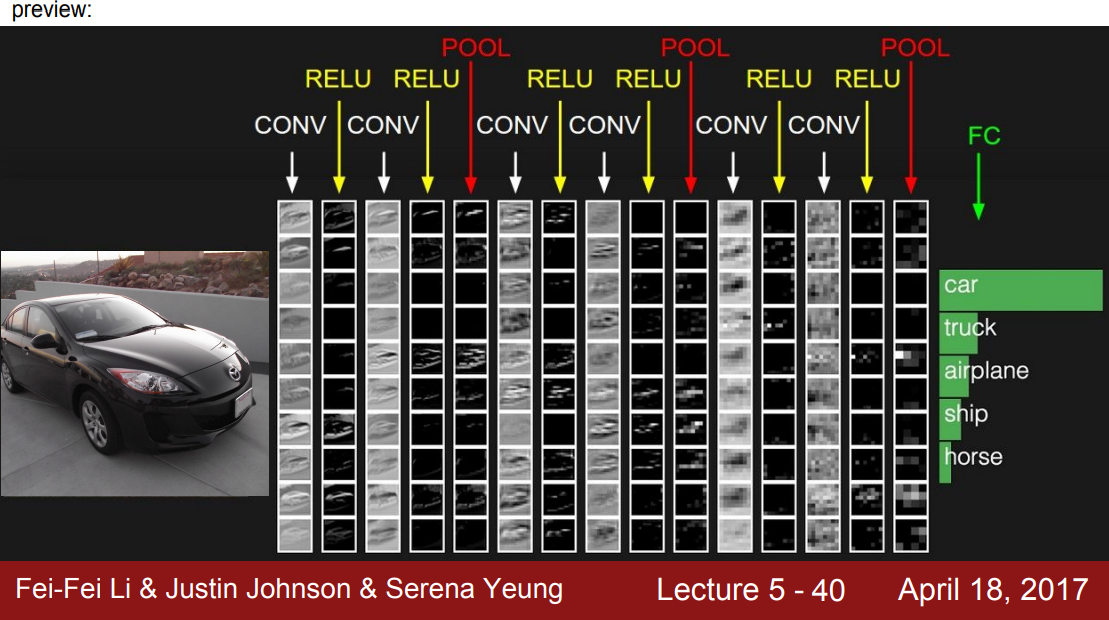
- 입력 이미지가 여러 layer를 통과한다.
- ex. 첫 번째 Conv layer를 통과한 후 non-linear layer(ReLU)를 통과
- Conv - ReLU - Conv - ReLU 를 통과한 후, pooling layer를 거치게 된다.
- 이때 pooling은 activation map의 사이즈를 줄이는 역할을 수행한다.
- CNN의 끝단에는 FC-layer가 있음
- 마지막 Conv 출력 모두와 연결되어 있으며, 최종 스코어를 계산하기 위해 사용한다.
Activation Map 생성
Sliding
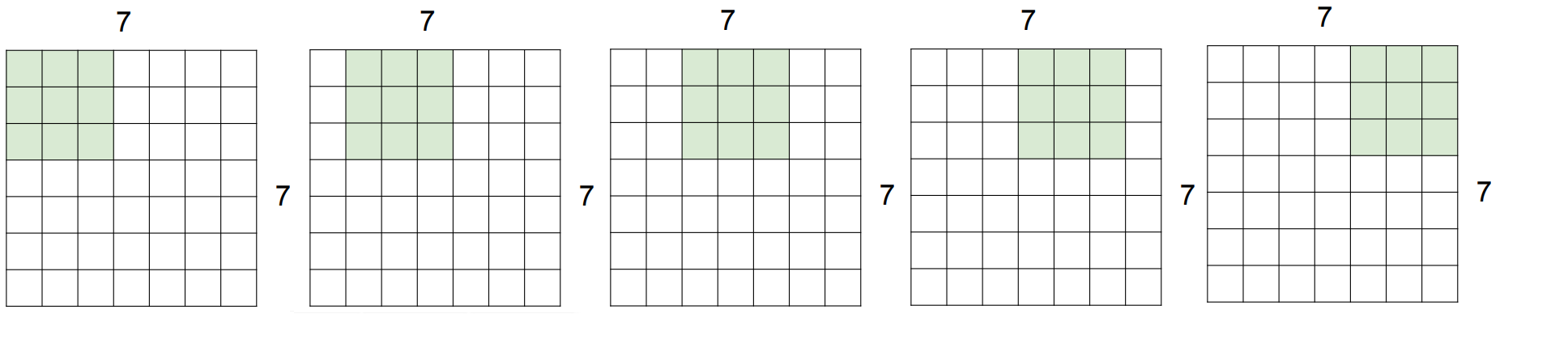
- 이미지에 필터가 sliding 되며 5x5 output activation map을 생성한다.
Stride

- 2칸, 3칸 건너뛰며 이동하는 것을 stride 2, stride 3라고 부른다.
- Input이 7x7인 경우 stride 2에서 3x3 output activation map이 생성되지만, stride 3에서는 정수로 나누어 떨어지지 않으므로 activation map을 생성할 수 없다.
- 단, padding을 추가하여 2.33을 반올림 할 수 있다.
Zero Padding
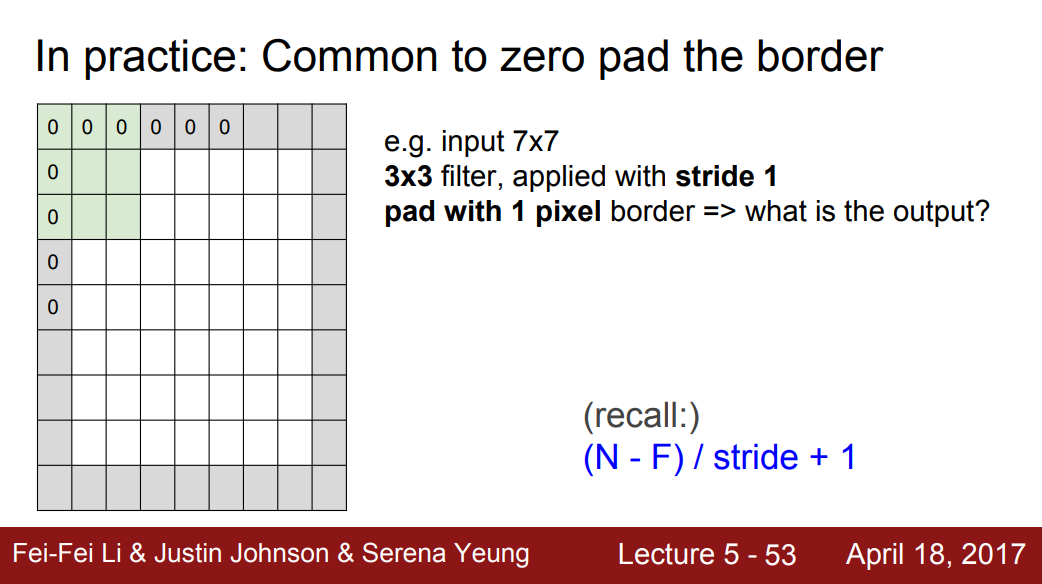
- Zero Padding이란 양쪽에 0의 값을 가지는 픽셀을 추가하여 image의 크기를 늘려주는 방식이다.
- Convolution 연산을 할 때마다 Activation Map의 크기가 감소하여 image가 없어지는 것을 방지할 수 있다. 또한 측면에 존재하여 필터로 내적되지 못한 데이터를 계산할 수 있다.
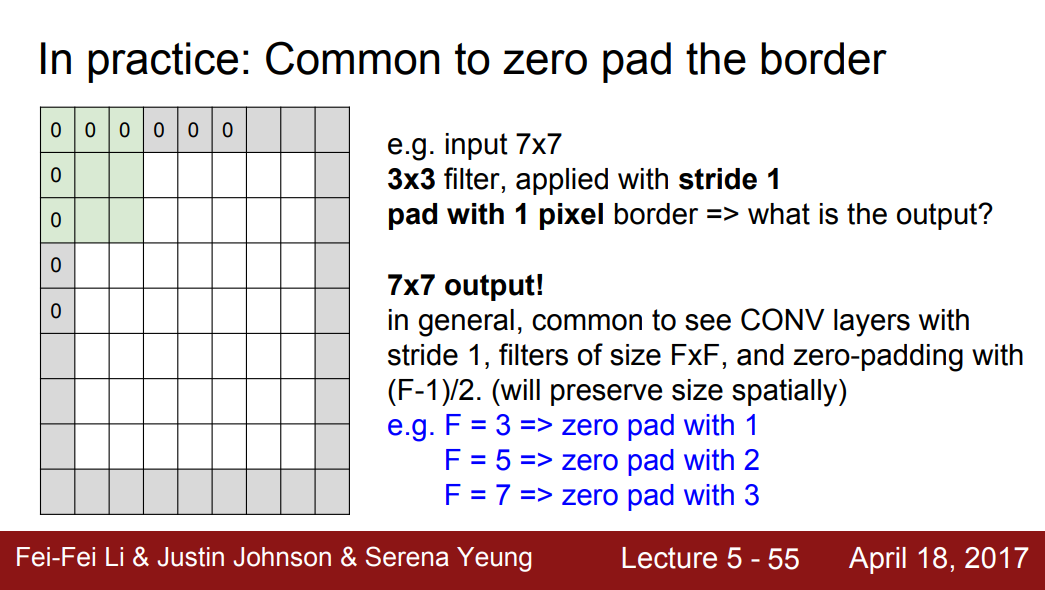
- Zero Padding을 사용하면 이와 같이 앞서 발생한 Stride 3 문제를 해결할 수 있다.
Example
Q1. Output volume size?
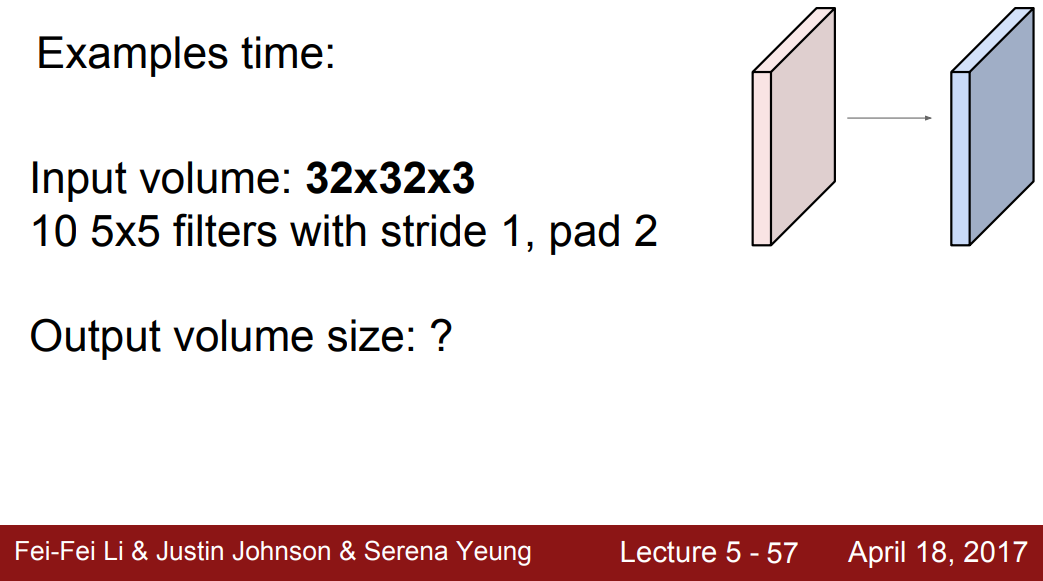

- 로 Height, Width의 값은 동일하다. 이때 필터가 10개이므로 32x32x10의 결과가 나온다.
Q2. Number of parameters in this layer?
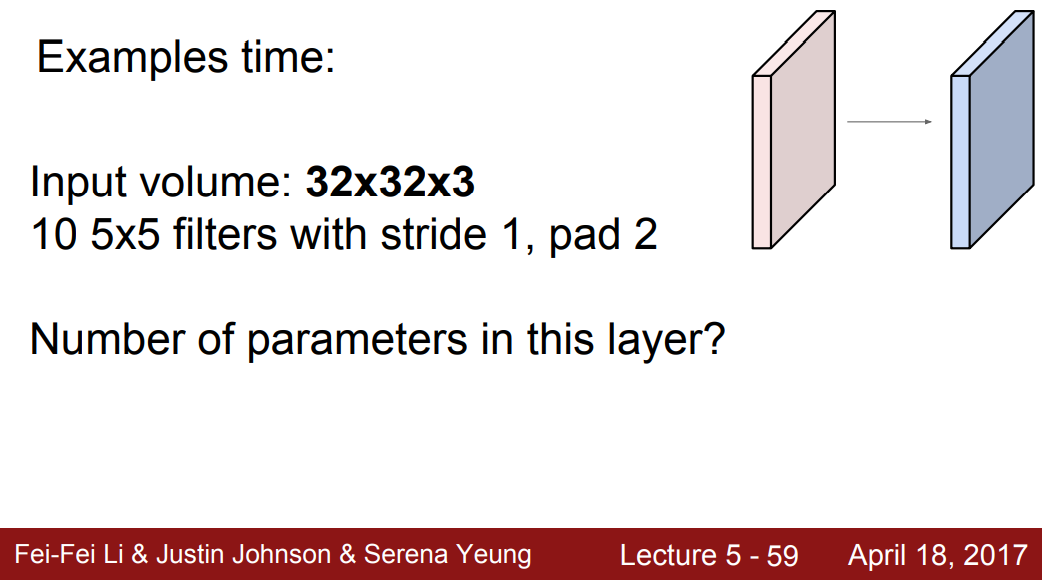

- 한 activation map의 parameter 개수는 이고, 10개의 필터가 있으므로 이 된다.
Summary

- 주로 사용되는 F, S, P의 세팅은 위와 같다.
1x1 convolution layers
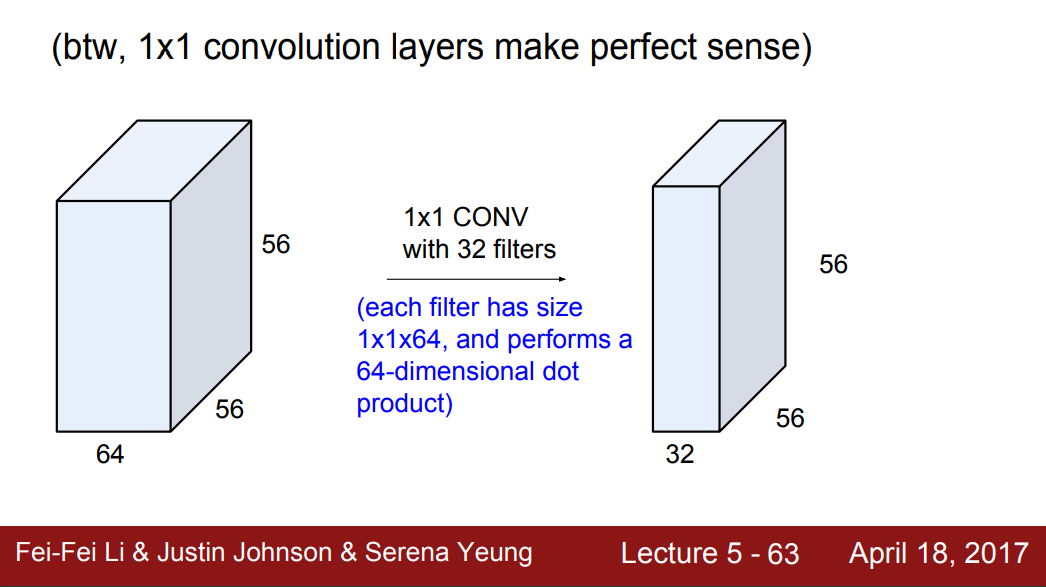
- 필터의 수에 따라 출력값의 깊이는 달라지지만 기존 이미지의 크기는 유지된다.
- 이때 필터의 수를 input dimenstion보다 작게 하면 dimension reduction의 효과가 있다.
- 즉, Convolution Layer는 Spatial Relation를 고려했다면 1x1 Spatial Relation는 한 픽셀만 고려하기 때문에 차원 축소를 위해 활용할 수 있다.
The brain/neuron view of CONV Layer
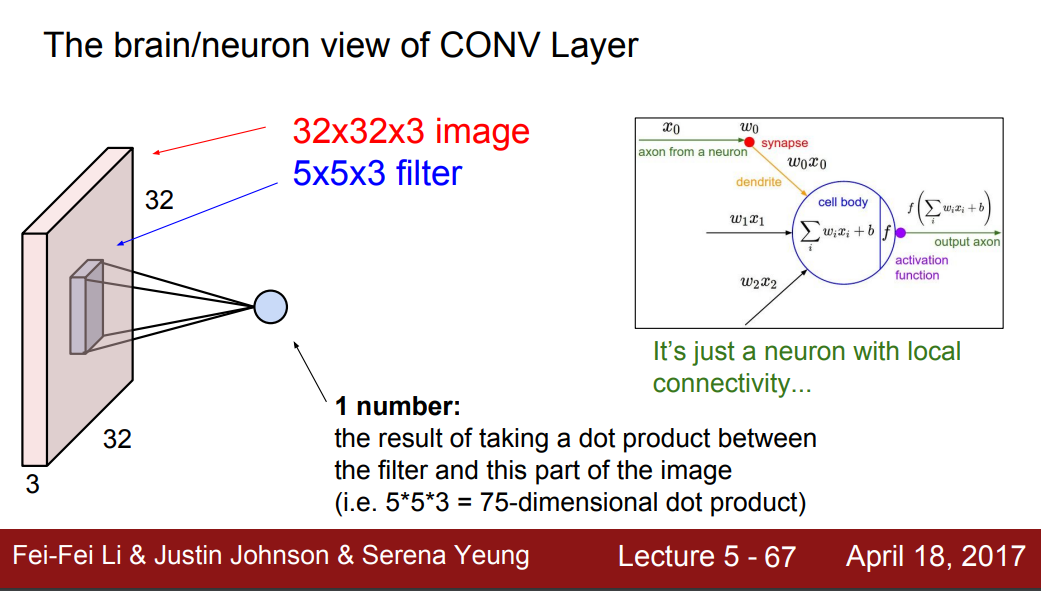
- 하나의 필터 영역 연산에 대해서는 1개의 숫자 output이 나오는데, 이것은 뉴런의 local connection과 유사하다.
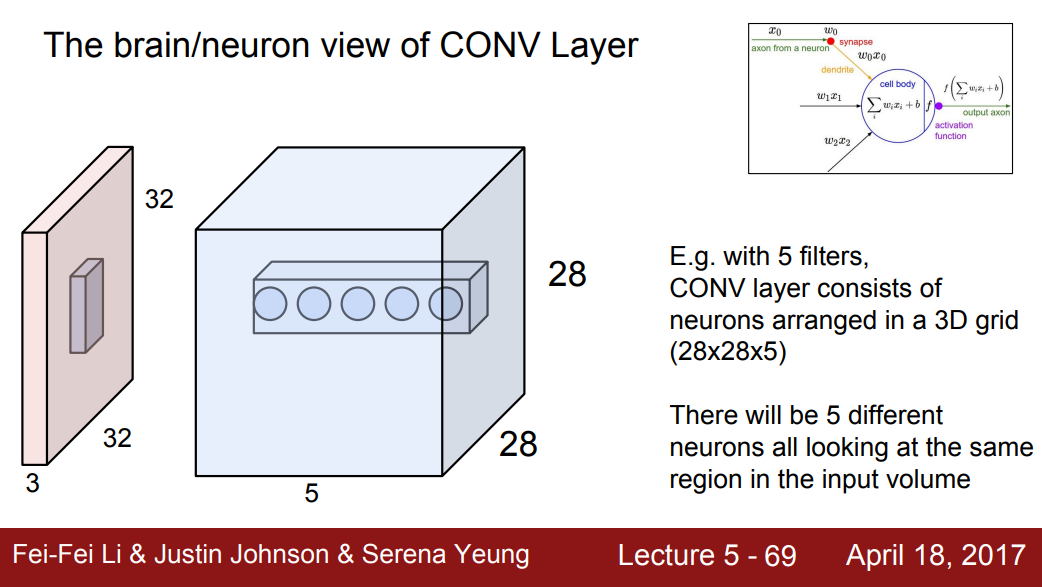
- 같은 영역의 경우 필터 개수 만큼의 값이 나오게 된다. 예제에서는 5개의 필터를 사용해 5개의 숫자가 나오지만, 각각 다른 필터를 사용했으므로 서로 다른 특징을 가질 것이다.
Fully Connected Layer
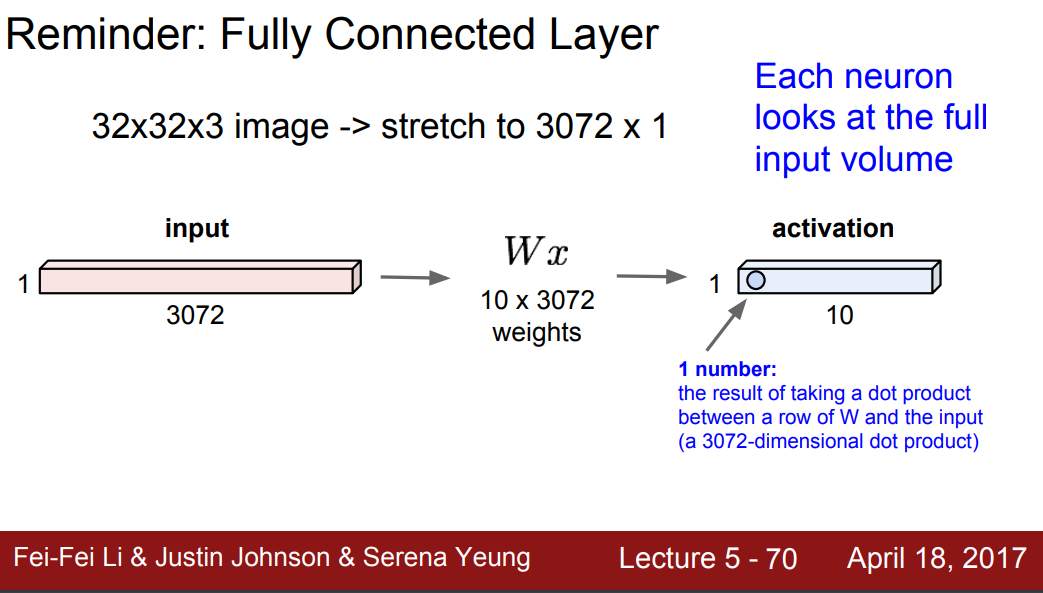
- FC의 경우 하나의 output이 모든 input에 대한 특징을 가지고 있다.
Pooling Layer

- Pooling은 이미지의 특징을 유지하며 크기를 줄이는 역할을 한다.
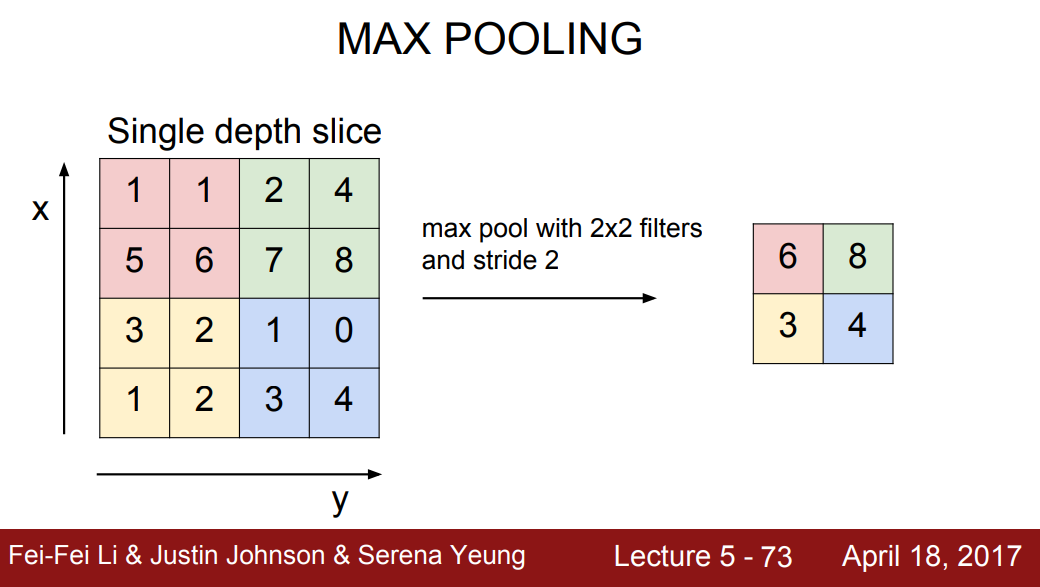
- 주로 Max Pooling을 사용한다. 위와 같이 각 구역 별로 최댓값을 찾고, 나머지 값은 버려 크기를 줄일 수 있다.

- Pooling layer에 대한 요약으로, 보통 필터의 사이즈에 무관하게 stride 2를 사용한다.

gaeul0024