NLP Preprocessing (Advanced)
prepocessing기법 중 POS(part-of-speech) tagging, Named entity recognition, parsing 등에 대해서 알아보겠습니다.
Sequence labelling tasks
POS tagging
POS tagging은 문장에서 각 단어가 어떠한 역할로 사용되는 지를 태깅하는 것입니다. 여기서 역할이란 noun, pronoun, verb, adjective 등을 의미합니다.
예를 들어 "I want to book a hotel room"이라는 문장이 있다면 I는 proper noun, want는 verb, book도 verb이런 식입니다.
이는 문장의 문맥과, 이웃 단어들과의 관계를 고려하여 부여되며 이를 통해 단어의 모호함을 해소(disambiguation)하는 것이 주 목적입니다.
만약 "I left the book in the hotel room"이라는 문장이 있다면 여기서 book은 noun으로 태깅되므로 위 문장에서의 book과는 다르다는 것을 모델이 인식할 수 있습니다.
spacy를 통해 쉽게 구현가능합니다.
[(t.text, t.pos_) for t in doc]
###
[('John', 'PROPN'),
('watched', 'VERB'),
('an', 'DET'),
('old', 'ADJ'),
('movie', 'NOUN'),
('at', 'ADP'),
('the', 'DET'),
('cinema', 'NOUN'),
('.', 'PUNCT')]pos_가 아닌 tag_를 이용하면 보다 자세한 분류(fine-grained tag)를 수행할 수 있습니다.
[(t.text, t.tag_) for t in doc]
###
[('John', 'NNP'),
('watched', 'VBD'),
('an', 'DT'),
('old', 'JJ'),
('movie', 'NN'),
('at', 'IN'),
('the', 'DT'),
('cinema', 'NN'),
('.', '.')]Named Entity Recognition
NER(Named Entity Recognition)이란 POS태깅과는 다르게 실제 존재하는 사람, 장소, 조직 등을 태깅하는 것입니다.예를 들어, "Alice"나 "Issac Newton"은 person으로 태깅하고 "Microsoft"나 "Google"은 organization으로 태깅하는 것이 예입니다.
"Vokswagen is developing an electric an electric sedan which could poteentially come to America next fall"라는 문장이 있다고 가정해봅시다.
이를 NER 엔진에 돌리면 다음과 같이 태깅될 수 있습니다.
"Vokswagen[ORG] is developing an electric an electric sedan which could poteentially come to America[GPE] next fall[DATE] "
이는 어디에 활용할 수 있을까요?
이는 특별한 도메인과 관련된 Organizing/Categorizing을 수행하거나 전문적인 question에 대한 answering을 수행할 수 있고, 정보 추출(Information extraction)에도 이용될 수 있습니다.
다만 크게 2가지 한계점을 안고 있습니다.
하나는 토큰이 여러 단어에 걸쳐있을 경우 엔진이 이에 대한 boundaries를 적절하게 식별할 수 있어야 한다는 것이고 둘째는 동일한 토큰이 "이름", "지명" 등등 다양한 타입에 해당될 수 있어 ambiguity를 내재하고 있다는 점입니다.
spacy ent_type으로 구현 가능합니다.
s = "Volkswagen is developing an electric sedan which could potentially come to America next fall."
doc = nlp(s)
[(t.text, t.ent_type_) for t in doc]
###
[('Volkswagen', 'ORG'),
('is', ''),
('developing', ''),
('an', ''),
('electric', ''),
('sedan', ''),
('which', ''),
('could', ''),
('potentially', ''),
('come', ''),
('to', ''),
('America', 'GPE'),
('next', 'DATE'),
('fall', 'DATE'),
('.', '')]POS와 NER모두 다음과 같이 explain을 통해 각 태그의 설명을 확인할 수 있습니다.
spacy.explain('GPE')
###
Countries, cities, states그리고 doc.ents를 이용하여 존재하는 엔티티가 존재하는 단어들만 볼 수도있습니다.
print([(ent.text, ent.label_) for ent in doc.ents])
###
[('Volkswagen', 'ORG'), ('America', 'GPE'), ('next fall', 'DATE')]Visualization
spacy에는 별도 visualizer가 내장되어있어 pos, ner, parsing을 수행할 때 이쁘게 시각화 할수도 있습니다.
from spacy import displacy
# We need to set the 'jupyter' variable to True in order to output
# the visualization directly. Otherwise, you'll get raw HTML.
displacy.render(doc, style='ent', jupyter=True)
Parsing
파싱은 문장의 형식적인 구문 구조(syntactic structure)를 결정하는 것입니다.
다음과 같은 크게 2가지 접근론이 있습니다.
Constituency Parsing
parse tree를 만듭니다.
root에는 보통 해당 sentence가 오고
트리를 내려가면서 phrases / clausesr로 분해되며, 그리고 리프노드에는 각 단어가 존재하게 됩니다.
constituency parsing은 context-free grammer(CFG)를 사용합니다.
이는 이미 정해진 엄격한 규칙에 따라 구문을 분해하는 것입니다.
Dependency Parsing
자연어 처리에서 좀 더 사용되는 이 방법은 단어들 사이의 binary relationships을 규정하는 것입니다.
즉 단어들 사이의 dependancy grammer를 정의해야 하는 것입니다.
예를 들어 the course이 있다면 the는 course이 한정사(determiner)라는 관계를 맺게되는 것입니다.
이러한 dependency parsing은 contituency parsing에 비해 문장속 단어들의 순서의 변화에 유연하게 대처할 수 있다는 장점이 있습니다.
s = "She enrolled in the course at the university."
doc = nlp(s)
# Note the 'style' argument is assigned a 'dep' flag this time around.
displacy.render(doc, style='dep', jupyter=True)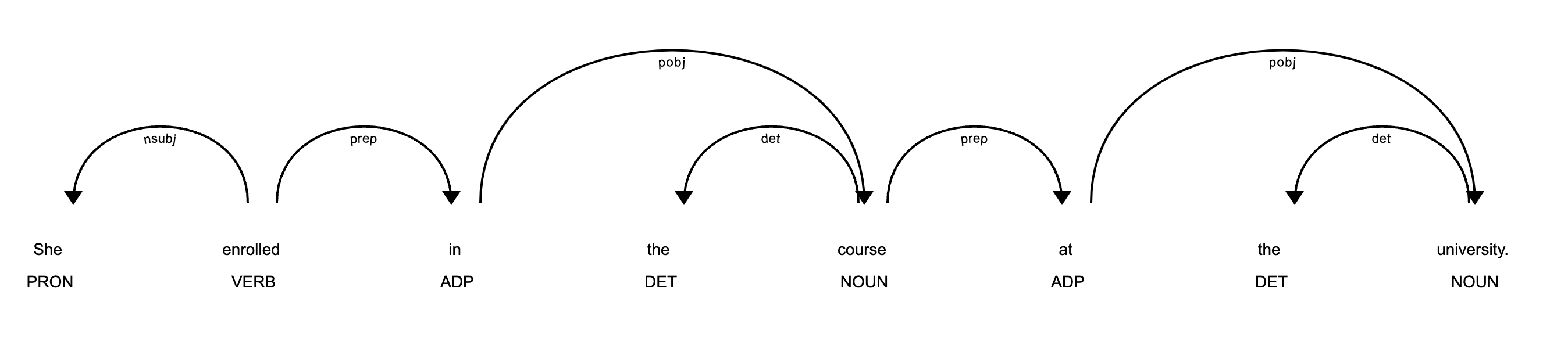
다음과 같이 dependency label을 확인할 수 있습니다.
[(t.text, t.dep_) for t in doc]
###
[('She', 'nsubj'),
('enrolled', 'ROOT'),
('in', 'prep'),
('the', 'det'),
('course', 'pobj'),
('at', 'prep'),
('the', 'det'),
('university', 'pobj'),
('.', 'punct')]그럼 이러한 parsing은 왜 하는 것일까요?
첫째로 문법적인 오류를 찾을 수 있고, 둘째로 문장속 구조를 규명하여 ambiguitiy를 제거할 수 있으며, 마지막으로 자연어를 처리함에 있어 머신이 이해할 수 있게 문장들을 정제된 형태로 정리하여 의미를 부여(semantic parsing)을 구현함에 있습니다.
Information extraction system
이러한 POS tagging, NER, Parsing을 적절히 조합하면 information extraction system을 만들 수 있습니다.
이는 금융, 게임 등 다양한 말뭉치 데이터에서 key entities와 그들의 관계를 규명하고 정리하는 것 입니다.
예를 들면 "Elon Musk is the CEO of SpaceX"라는 문장이 있다면 이를 (subject, relation, object)라는 triples의 형태의 지식베이스로 정리하여
(Elon Musk, CEO, SpaceX)를 추출할 수 있습니다.
References
[1] nlpdemystifed, https://www.nlpdemystified.org/
