[HSAT 7회 정기 코딩 인증평가 기출] 자동차 테스트
자동차 제조 과정에서는 다양한 테스트를 통해 해당 자동차가 잘 만들어졌는지를 평가합니다.
이러한 평가 지표 중 하나는 자동차의 연비입니다.
자동차의 연비가 높을수록 연료 소비가 적고, 더 많은 거리를 주행할 수 있으므로 이는 자동차가 잘 만들어졌는지의 지표로 사용될 수 있습니다.
만약 3대의 자동차를 테스트하고, 각각의 연비를 측정한다고 가정해봅시다.
첫 번째 자동차의 연비는 9km/L,
두 번째 자동차의 연비는 15km/L,
세 번째 자동차의 연비는 20km/L이라고 합시다.
이 경우, 중앙값은 15km/L이 됩니다.
따라서 이 데이터에서는 중앙값을 이용하여 자동차의 평균적인 연비를 파악할 수 있으며, 이는 자동차 제조 과정에서 테스트의 결과를 평가하는 데 활용될 수 있습니다.
n대의 자동차를 새로 만들었지만 여건상 3대의 자동차에 대해서만 테스트가 가능한 상황입니다.
n대의 자동차의 실제 연비 값이 주어졌을 때, q개의 질의에 대해 임의로 3대의 자동차를 골라 테스트하여 중앙값이 mi값이 나오는 서로 다른 경우의 수를 구하는 프로그램을 작성해보세요.
제약조건
* 1 ≤ n ≤ 50,000
* 1 ≤ q ≤ 200,000
* 1 ≤ 자동차의 연비 ≤ 1,000,000,000
* 1 ≤ mi ≤ 1,000,000,000 (i는 1 이상 q 이하입니다. 즉, mi 는 각 질의에 대응하는 중앙값을 의미합니다.)Java 기준 3초를 주어주기에 웬만해선 시간초과가 안날 줄 알고, 아래처럼 순차탐색을 통해 구하려고 했다.
문제 해결의 핵심은 다음과 같다.
- 정렬을 진행
- 기대값이 배열에 있다면 기대값 기준 좌,우에 있는 개수를 각각 구해서 곱함
- 기대값이 배열에 없거나, 범위를 벗어난다면 0
역시 최악의 경우 n * q 만큼 진행하기 때문에 10_000_000_000번 연산이 진행되어서 시간초과가 나게 된다.
틀린코드
import java.io.*;
import java.util.*;
/*
시간 : 3초
메모리 : 1024MB
---
n = 자동차 수
q = 테스트 기댓값 수
ex) 자동차 연비 5 2 3 1 6 -> 1 2 3 5 6
이 중에서 3대의 자동차를 골라 중앙값이 m 이 나오는 경우의 수
테스트 기대값 1 -> -
테스트 기대값 3 -> 1 3 5, 1 3 6, 2 3 5, 2 3 6
테스트 기대값 6 -> -
즉, 정렬을 진행하고, 해당 기대값의 좌,우에 있는 개수를 곱하면 됨.
*/
public class Main {
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringBuilder sb = new StringBuilder();
StringTokenizer st = new StringTokenizer(br.readLine());
int n = Integer.parseInt(st.nextToken()); // 자동차 수
int q = Integer.parseInt(st.nextToken()); // 테스트 기댓값 수
int[] cars = new int[n];
st = new StringTokenizer(br.readLine());
for (int i=0; i<n; i++) {
cars[i] = Integer.parseInt(st.nextToken()); // 자동차별 연비를 저장
}
Arrays.sort(cars); // 정렬
for (int tc=0; tc<q; tc++) {
int expectValue = Integer.parseInt(br.readLine());
boolean flag = false;
for (int i=0; i<n; i++) {
// 예상값을 배열에서 찾았다면, 해당 값 보다 작은 인덱스의 개수와 큰 인덱스와 개수를 곱함
if (cars[i] == expectValue) {
int minIdxNum = i;
int maxIdxNum = n-i-1;
flag = true;
sb.append(minIdxNum*maxIdxNum).append("\n");
}
}
if (!flag) { // 중앙값이 존재하지 않는다면 0
sb.append(0).append("\n");
}
}
System.out.println(sb);
}
}
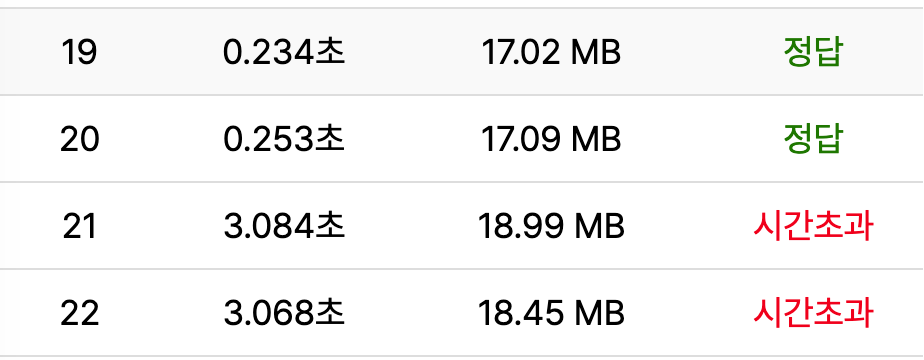
그래서 해결방법은 배열을 진행하기 때문에 이진탐색을 적용할 수 있다.
이진탐색은 탐색 대상을 절반씩 줄여 나가기 때문에 O(logN) 시간복잡도를 가진다.
그렇기에 이진탐색을 적용해서 코드를 구현하면 해결 가능하다.
이진탐색은 생각보다 쉬운 알고리즘이라 아이디어만 서칭하고 구현에 임했다.
import java.io.*;
import java.util.*;
/*
시간 : 3초
메모리 : 1024MB
---
n = 자동차 수
q = 테스트 기댓값 수
ex) 자동차 연비 5 2 3 1 6 -> 1 2 3 5 6
이 중에서 3대의 자동차를 골라 중앙값이 m 이 나오는 경우의 수
테스트 기대값 1 -> -
테스트 기대값 3 -> 1 3 5, 1 3 6, 2 3 5, 2 3 6
테스트 기대값 6 -> -
즉, 정렬을 진행하고, 해당 기대값의 좌,우에 있는 개수를 곱하면 됨.
---
현재 구조의 최악의 경우 n*q 번 반복하게 되어서 10_000_000_000번 연산이 진행
따라서 순차 탐색이 아닌 다른 방법이 필요함.
정렬이 가능하기에 이진탐색을 적용
*/
public class Main {
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringBuilder sb = new StringBuilder();
StringTokenizer st = new StringTokenizer(br.readLine());
int n = Integer.parseInt(st.nextToken()); // 자동차 수
int q = Integer.parseInt(st.nextToken()); // 테스트 기댓값 수
int[] cars = new int[n];
st = new StringTokenizer(br.readLine());
for (int i=0; i<n; i++) {
cars[i] = Integer.parseInt(st.nextToken()); // 자동차별 연비를 저장
}
Arrays.sort(cars); // 정렬
for (int tc=0; tc<q; tc++) {
int expectValue = Integer.parseInt(br.readLine());
// 예상값이 배열 값 범위를 벗어나면 0
if (cars[0] >= expectValue && cars[n-1] <= expectValue) {
sb.append(0).append("\n");
continue;
}
int left = 0;
int right = n-1;
boolean flag = false;
while (left <= right) {
int mid = (left+right)/2;
if (cars[mid] < expectValue) {
left = mid+1;
} else if (cars[mid] > expectValue) {
right = mid-1;
} else { // 예상값과 탐색하는 값이 같다면 탐색 위치 기준 왼쪽의 개수와 오른쪽 개수를 곱함
int leftNum = mid;
int rightNum = n-mid-1;
sb.append(leftNum*rightNum).append("\n");
flag = true;
break;
}
}
if (!flag) { // 배열에 존재하지 않는 값이라면 0
sb.append(0).append("\n");
}
}
System.out.println(sb);
}
}
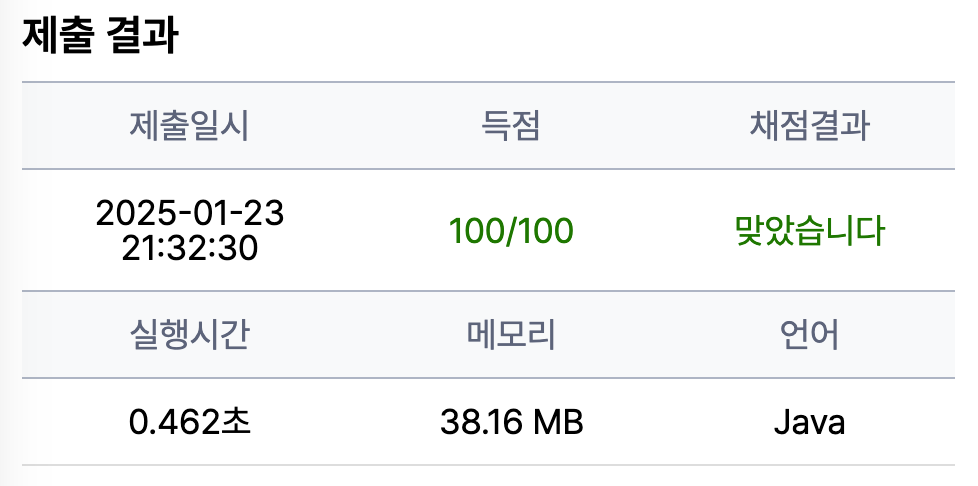

공부 정리용