RabbitMQ
메시지 브로커로, 메시지를 큐(queue)에 저장하고, 필요할 때 적절한 수신자에게 전달한다.
- 비동기 처리 : 데이터를 비동기적으로 처리해 시스템의 응답성을 높인다.
- 부하 분산 : 여러 소비자에게 메시지를 분산시켜 시스템의 부하를 균형 있게 분산한다.
- 내결함성 : 메시지를 안전하게 저장하여 시스템 장애 시 데이터 손실을 방지한다.
장점
- 신뢰성
- 메시지 지속성 : 메시지를 디스크에 저장하여 시스템 장애 발생 시에도 메시지가 손실되지 않도록 한다.- 확인 매커니즘 : 메시지가 성공적으로 소비자에게 전달되었는지 확인하는 ACK 매커니즘을 지원한다.
- 유연성
- 다양한 메시지 패턴 : 단일 소비자, 다중 소비자, 라운도 로빈, 팬아웃, 주제 기반 등을 지원- 프로토콜 지원 : 기본적으로 AMQP 를 사용하지만 STOMP, MQTT 등 다양한 프로토콜도 지원
- 확장성
- 클러스터링 : 여러 노드로 구성된 환경에서 높은 가용성과 부하 분산을 제공- 분산 아키텍처 : federation 및 sharded nodes 을 통해 분산된 메시징 시스템 구축
- 관리 및 모니터링
- 관리 인터페이스 : 웹 기반 관리 인터페이스를 통해, 큐, 익스체인지, 바인딩 등을 쉽게 관리- 플러그인 시스템 : 다양한 플러그인을 통해 기능을 확장 (관리, 모니터링)
- 성능
- 높은 처리량 : 높은 메시지 처리량을 제공해 대규모 애플리케이션에서도 효과적 사용 가능
단점
- 설정 및 운영 복잡성
- 성능 문제
- 메시지 브로커가 모든 메시지를 전달하기에 오버헤드가 발생할 수 있다.
- 아이러니 하게도 매우 대규모의 메시지를 처리할 때 성능 저하가 발생할 수 있다. - 운영 비용
- 리소스 소비, 모니터링 및 유지보수 - 제한된 메시지 크기
- 매우 큰 메시지 처리에 제한이 있을 수 있어, 대용량 파일 전송에는 적합하지 않을 수 있다. - 러닝 커브
기본 구성 요소
- 메시지
- 프로듀서
- 큐
- 컨슈머
- 익스체인지
- 메시지를 적절한 큐로 라우팅 하는 역할을 한다.
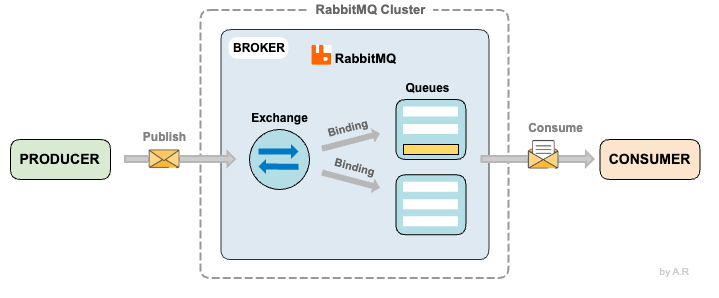
RabbitMQ와 AMQP
- AMQP (Advanced Message Queuing Protocol)을 사용한다.
- AMQP 는 메시지 브로커를 위한 프로토콜로, 메시지의 생성, 전송, 큐잉, 라우팅 등을 표준화하여 메시지가 상호 운용 될 수 있게 한다.
AMQP 주요 기념
- 메시지
- 큐
- 익스체인지
- 바인딩
- 익스체인지와 큐를 연결하는 설정. 바인딩을 통해 메시지가 어느 큐로 전달될지 정의
익스체인지 유형
- 메시지 브로커가 메시지를 교환기에서 큐로 라우팅하는 방식
- 다양한 방식으로 메시지를 라우팅할 수 있으며, 주로 메시지의 라우팅 키와 바인딩 키 또는 패턴을 기반으로 작동
- Direct Exchange (주 사용)
- 라우팅 키가 정확히 일치하는 큐로 메시지 전달
- Topic Exchange
- 라우팅 키의 패턴을 사용해 메시지를 라우팅. ex) *, # 사용
- Fanout Exchange
- 라우팅 키를 무시하고 교환기에 바인딩된 모든 큐로 메시지를 브로드캐스트
- Headers Exchange
- 라우팅 키 대신 메시지의 헤더를 기반으로 메시지 라우팅
RabbitMQ 실습
docker run -d --name rabbitmq -p5672:5672 -p 15672:15672 --restart=unless-stopped rabbitmq:management다음 docker 명령어를 통해 rabbitmq를 도커 환경에서 쉽게 띄울 수 있다.
다음 localhost:15672 로 접속하게 되면, 다음과 같은 웹 화면을 확인할 수 있는데 기본 id/password 는 guest/guest 이다.
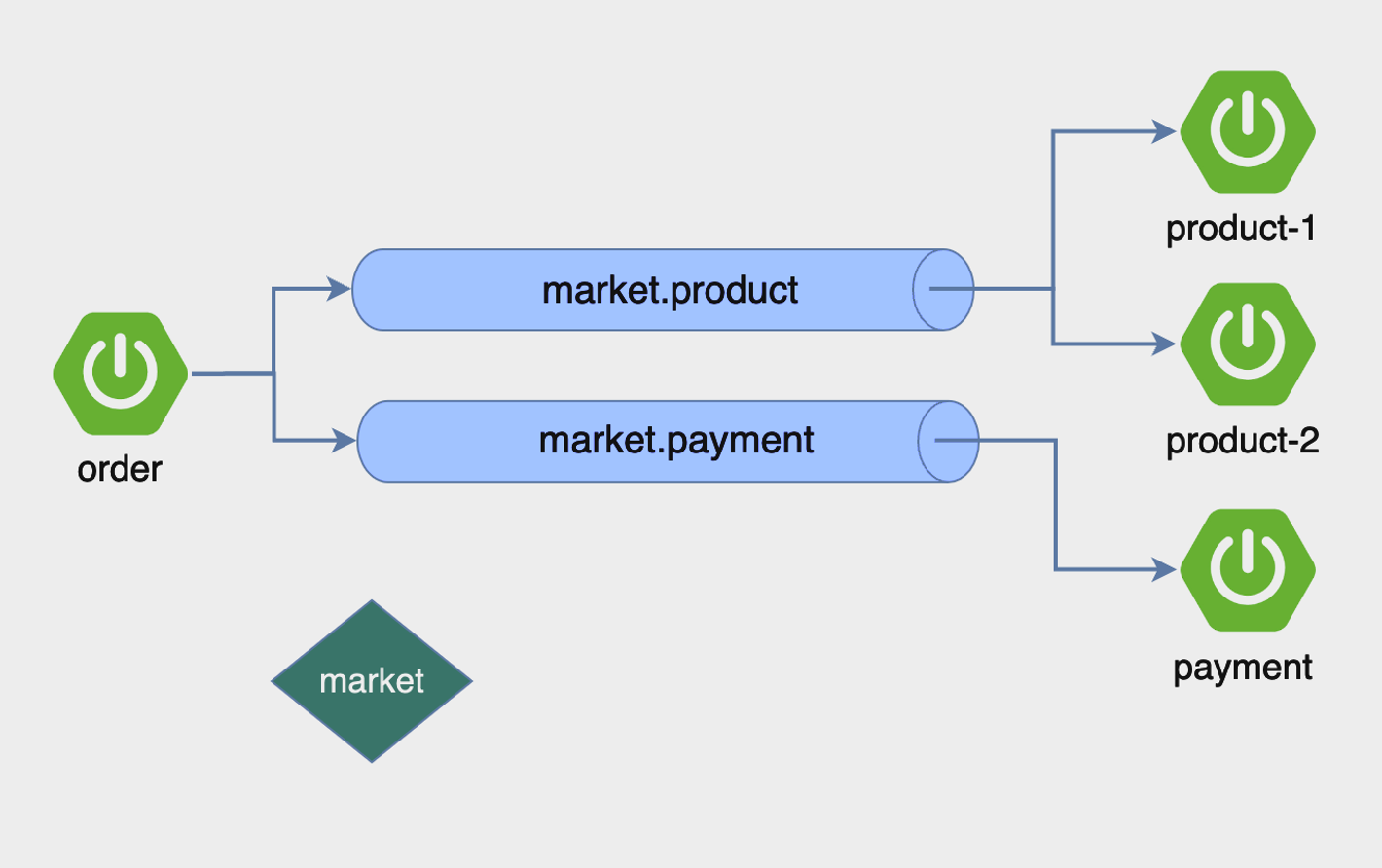
해당 그림에서 처럼 Order 서비스에서 익스체인지를 통해 각 큐로 메시지를 바인딩해주고, product,payment 서비스로 각 큐가 메시지를 전달하는 구조로 이루어져 있다.
주요한 점은 바인딩의 이름도 메시지 큐의 이름과 동일하게 설정해야 헷갈리지 않는다.
order.properties
spring.application.name=order
message.exchange=market
message.queue.product=market.product
message.queue.payment=market.payment
spring.rabbitmq.host=localhost
spring.rabbitmq.port=5672
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest이처럼 order 입장에서는 메시지를 publish 하기 때문에 exchange의 이름과 각 큐의 이름을 알고 있어야 한다.
OrderApplicationQueueConfig
@Configuration
public class OrderApplicationQueueConfig {
@Value("${message.exchange}")
private String exchange;
@Value("${message.queue.product}")
private String queueProduct;
@Value("${message.queue.payment}")
private String queuePayment;
@Bean
public TopicExchange exchange() {
return new TopicExchange(exchange); // 해당 이름의 exchange 가 생성됨.
}
@Bean
public Queue queueProduct() {
return new Queue(queueProduct); // 해당 이름의 Queue 가 생성 됨.
}
@Bean
public Queue queuePayment() {
return new Queue(queuePayment);
}
@Bean
public Binding bindingProduct() {
return BindingBuilder
.bind(queueProduct()) // 바인딩할 큐
.to(exchange()) // exchange
.with(queueProduct); // 라우팅 이름 (큐의 이름과 일치)
}
@Bean
public Binding bindingPayment() {
return BindingBuilder.bind(queuePayment()).to(exchange()).with(queuePayment);
}
}
Exchane, Queue, Binding 을 생성하는 작업을 해줘야 한다.
OrderService
public void createOrder(String orderId) {
rabbitTemplate.convertAndSend(productQueue, orderId);
rabbitTemplate.convertAndSend(paymentQueue, orderId);
}이런식으로 rabbitTemplate을 통해서 메시지를 전송할 수 있다.
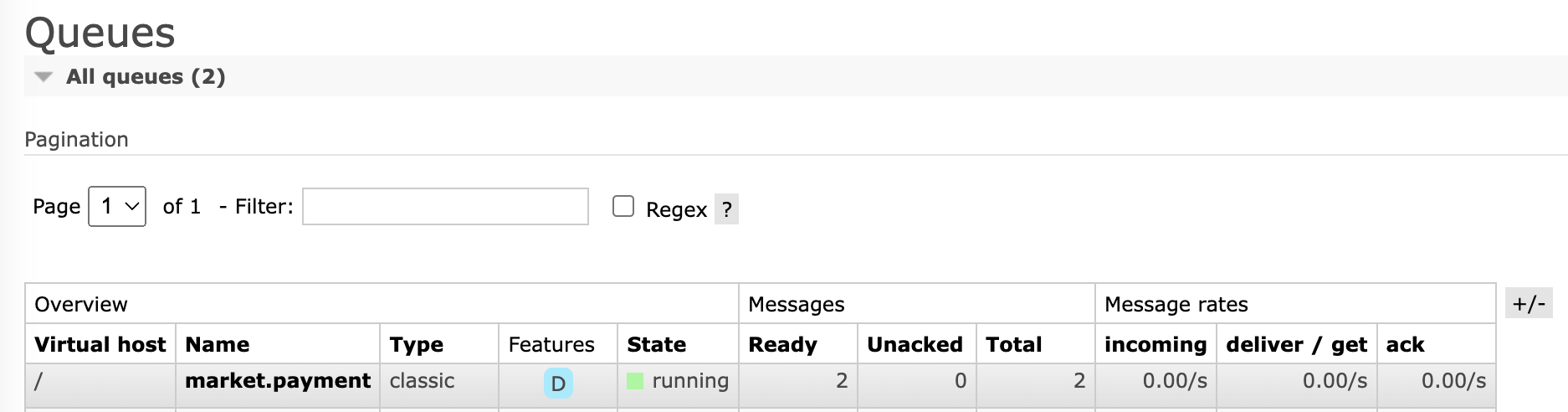
그러면 웹 페이지를 통해 확인할 수 있다.
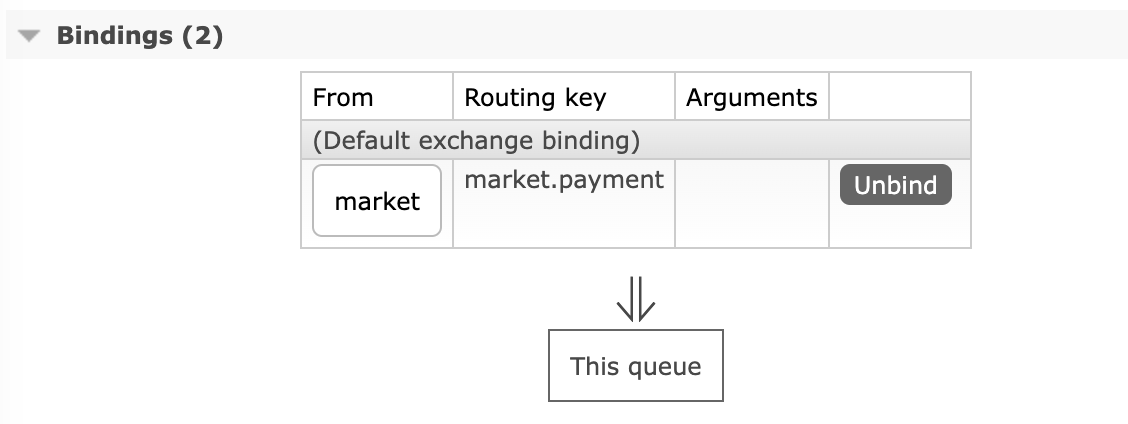
바인딩에 대한 정보나,
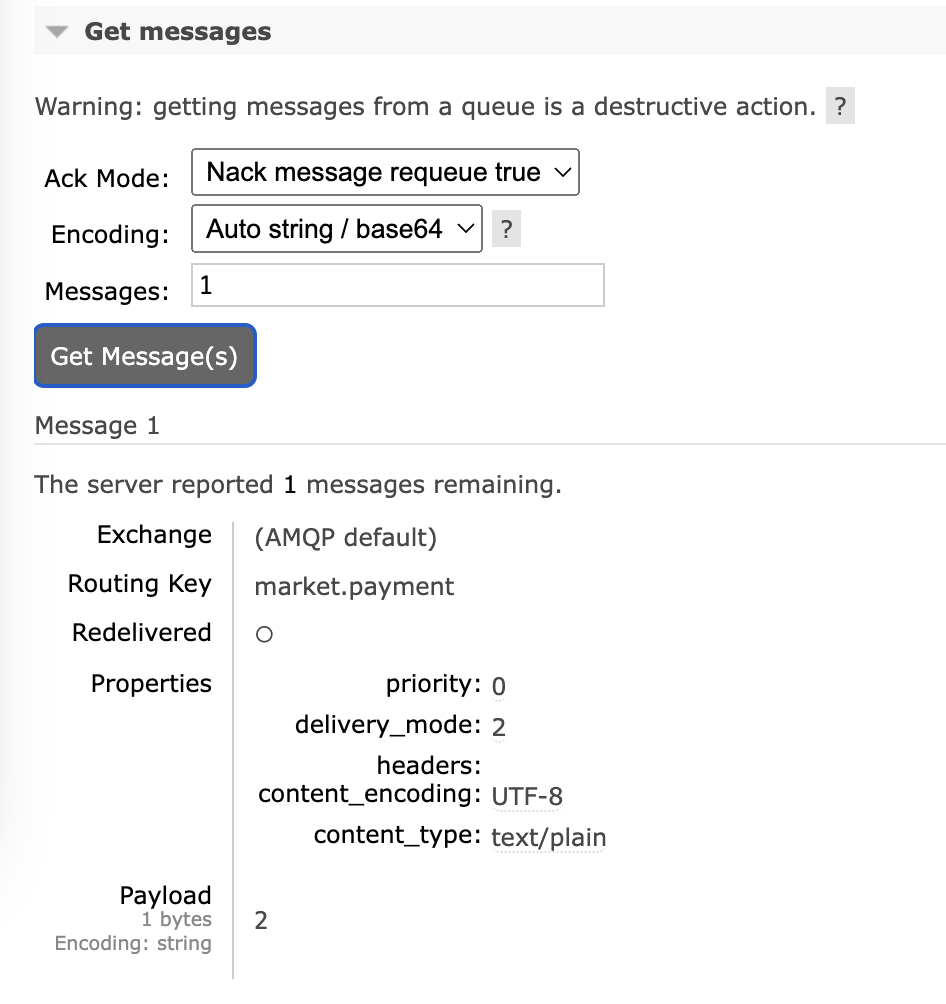
받은 메시지의 대한 정보도 확인할 수 있다.
또한, Delete, Purge 등 다양한 강력한 동작을 지원한다.
RR 테스트
ProductEndpoint
@Slf4j
@Component
public class ProductEndpoint {
@Value("${spring.application.name}")
private String appName;
@RabbitListener(queues = "${message.queue.product}")
public void receiveMessage(String orderId) {
log.info("receive orderId:{}, appName : {}", orderId, appName);
}
}@RabbitListener 를 통해 해당 큐 이름과 동일한 큐에 적재된 메시지들을 전달받을 수 있다.

테스트를 위해 ProductApplication을 2개로 소비를 테스트해보면


이런식으로 자동으로 RR 방식으로 메시지의 전달을 분산시켜주는 것을 확인할 수 있다.
그렇기에 만약 각 서버가 로드밸런싱을 통해 여러개의 서버로 이루어지더라도 기존 RabbitMQ는 자동으로 로드밸런싱된 각 서버로 RR 방식으로 메시지를 전송한다는 것을 확인할 수 있다.

또한 Overview 탭에서 MQ가 메시지나 소켓을 처리할 수 있을지 상태를 확인할 수 있다.
Kafka
분산 스트리밍 플랫폼으로, 주로 실시간 데잍 피드의 빅 데이터 처리르 목적으로 사용한다.
메시지 큐와유사하지만, 대용량 데이터 스트림을 저장하고 실시간으로 분석하거나 처리하는 데 중점을 둠.
역할
- 실시간 데이터 처리 : 대용량 데이터를 실시간으로 처리하고 분석
- 데이터 통합 : 다양한 소스에서 데이터를 수집하고 이를 통합하여 분석
- 내결함성 : 데이터 손실 없이 안정적으로 데이터를 저장하고 전송
장점
- 신뢰성
- 데이터 복제 및 확인 매커니즘 제공 - 유연성
- 여러 소비자가 동시에 데이터를 구독하거나, 다양한 프로토콜을 지원 - 확장성
- 분산 시스템, 수평 확장 - 성능
- 높은 처리량, 저지연 - 관리 및 모니터링
- 관리 도구, 플러그인 시스템
단점
- 설정 및 운영 복잡성
- 성능 문제
- 운영 비용
- 러닝 커브
기본 구성 요소
- 메시지
- 로그 데이터나, 이벤트 데이터 메시지가 될 수 있다. 메시지는 key, value, timestamp, 그리고 여러 메타데이터로 구성된다. - 프로듀서
- 메시지를 생성하고, 특정 토픽에 메시지를 보낸다. - 토픽
- 메시지를 저장하는 장소이다. 여러 파티션으로 나눠질 수 있으며, 파티션은 메시지를 순서대로 저장한다. 파티션으로 병렬 처리가 가능하다. - 파티션
- 파티션은 토픽을 물리적으로 나눈 단위로, 각 파티션은 독립적으로 메시지를 저장/관리- 각 파티션은 메시지를 순서대로 저장하며, 파티션 내 메시지는 고유한 offset으로 식별
- 파티션을 통해 데이터를 병렬로 처리할 수 있으며, 클러스터 내의 여러 브로커에 분산 저장 가능
- 키
- 메시지를 특정 파티션에 할당하는 데 사용되는 값- 동일한 키를 가진 메시지는 항상 동일한 파티션에 저장
- 컨슈머
- 토픽에서 가져와 처리하는 역할- 특정 컨슈머 그룹에 속하며, 같은 그룹에 속한 컨슈머들은 토픽의 파티션을 분산 처리 한다.
- 기본적으로 Sticky Partitioning을 사용하낟. 이는 특정 컨슈머가 특정 파티션에 붙어서 계속해서 처리하는 방식으로, 데이터 지역성을 높여 캐시 히트율을 증가시키고 전반적인 처리 성능 향상
- 브로커
- Kafka 클러스터의 각 서버를 의미, 메시지를 저장/전송 역할- 하나의 Kafka 클러스터는 여러 브로커로 구설될 수 있으며, 각 브로커는 하나 이상의 토픽 파티션을 관리
- 주키퍼
- Kafka 클러스터를 관리하고 조정하는 데 사용되는 분산 코디네이션 서비스- 브로커의 메타데이터를 저장하고, 브로커 간의 상호작용을 조정
Kafka와 RabbitMQ 차이점
설계 철악
- MQ : 전통적인 메시지 브로커로, 메시지의 안정적 전달과 큐잉에 중점
- kafka : 분산 스트리밍 플랫폼으로, 대규모 실시간 데이터 스트림의 저장과 분석에 중점
메시지 모델
- MQ : 큐를 중심으로 메시지를 전달. 메시지는 큐에 저장되고, 큐에서 하나 이상의 컨슈머에게 전달
- kafka : 토픽을 중심으로 메시지를 저장. 메시지는 토픽의 파티션에 저장되고, 컨슈머는 이 파티션에서 메시지를 읽음
메시지 지속성
- MQ : 메시지를 메모리나 디스크에 저장. 일반적으로 단기 저장을 목표
- kafka : 메시지를 디스크에 저장하며, 장기 저장을 목표로 함. 데이터 로그는 설정된 기간 동안 보존
사용
- MQ : 작업 큐, 요청/응답 패턴, 비동기 작업 처리 등 전통적인 메시지 큐 사용 사례에 적합
- Kafka : 실시간 데이터 스트리밍, 로그 수집 및 분석, 이벤트 소싱 등 대규모 데이터 스트림 처리에 적합.
(번외) 선착순 티켓 발급 시스템 구조
쉽게 생각해봤을 때 RabbitMQ의 하나의 큐에 모든 요청을 받아서 순서를 보장하거나, 싱글 스레드 기반의 Redis의 list를 Queue처럼 사용해서 순서를 보장해줄 수 있을 것 같다.
근데, 큐에서 순서를 보장했다 하더라도 서버가 여러 대 떠있는 상황이라면 각 서버에서 처리하는 속도가 다르기 때문에 최종적으로는 순서 보장이 안될 수도 있다.
그에 따라 낙관적 lock, 비관적 lock, 분산 lock 같은 lock개념을 적용할 수 있을 것 같다.
https://tecoble.techcourse.co.kr/post/2023-08-16-concurrency-managing/
다음 블로그에서 자세하게 설명하고 있다.
좌석 선택을 예시로 들었을 때 좌석을 선택하고 넘어가는 과정에서 예약 설정을 하고, 결제가 완료된 후 확정상태로 변경되는 방법이 있을 수 있고,
좌석을 중복해서 선택할 수 있으며, 결제가 완료되는 시점에 좌석 확정 상태가 되는 방법이 있다.
다음 게시글에 Kafka 실습에 대한 내용을 다루도록 하겠다.
