비시계열 데이터 준비
- 훈련셋(Training set)
: 일반적으로 전체 데이터의 60%를 사용하여 기계학습을 하는데 사용됨 - 검증셋 (Validation set)
- 개발셋이라고도 하며, 일반적으로 전체 데이터의 20%를 사용함- 훈련된 여러가지 모델들의 성능을 테스트 하는데 사용되며 모델 선택의 기준이 됨
- 테스트셋 (Testing set)
: 전체 데이터의 20%를 사용하며 최종 모델의 정확성을 확인하는 목적에 사용됨
과적합을 방지하기 위해서 training set에서 validation set을 분리한 후 training set을 사용해 검증한다.

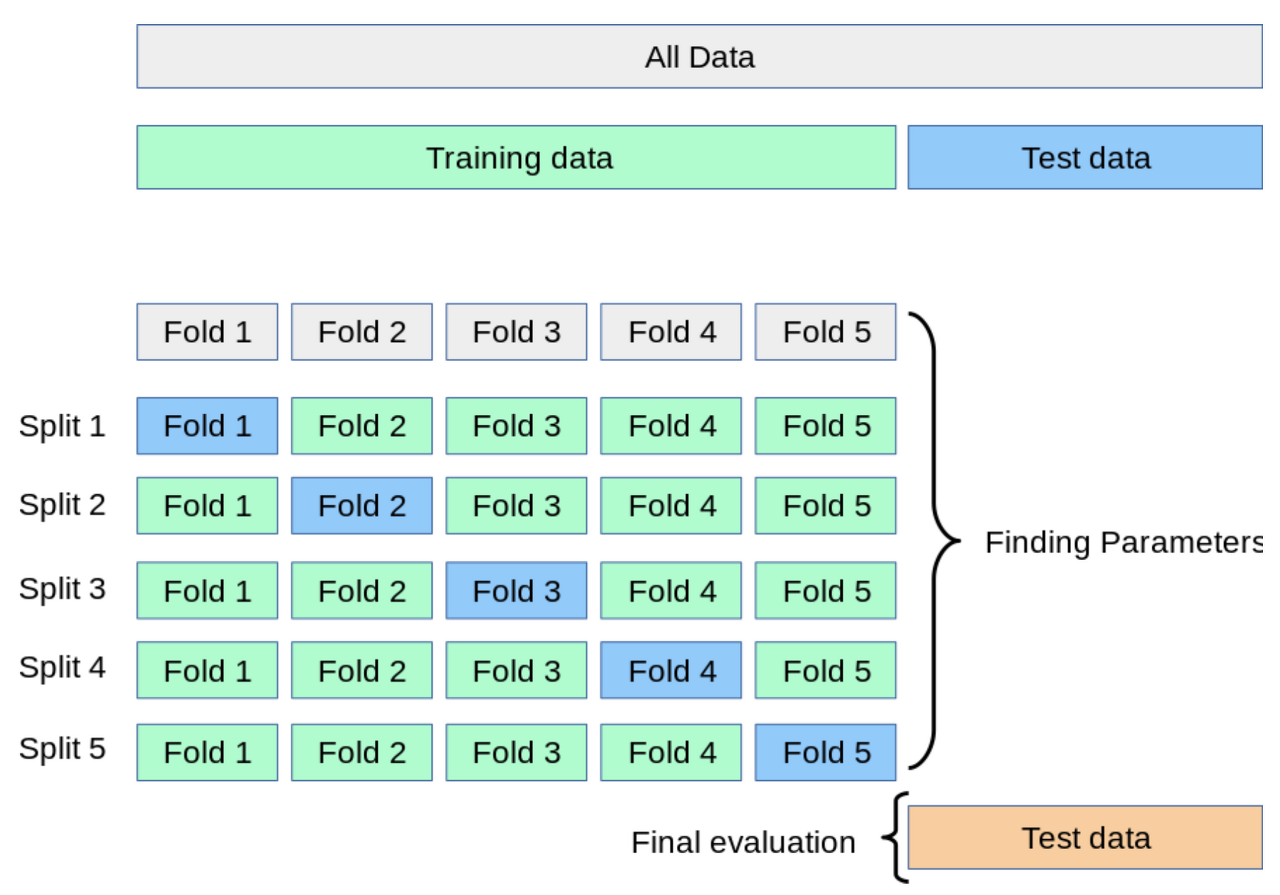
K-fold Cross Validation
- 가장 일반적으로 사용되는 교차 검증 방식
- 회귀 모델에서 사용되며, 데이터가 독립적이고 동일한 분포를 가진 경우에 사용.
교차검증 과정
1. 훈련셋을 복원없이 K개로 분리한 후, K-1는 하위훈련셋으로 나머지 1개는 검증셋으로 사용한다.
2. 검증셋과 하위훈련셋을 번갈아가면서 K번 반복하여 각 모델별로 K개의 성능 추정치를 계산한다.
3. K개의 성능 추정치 평균을 최종 모델 성능 기준으로 사용한다.
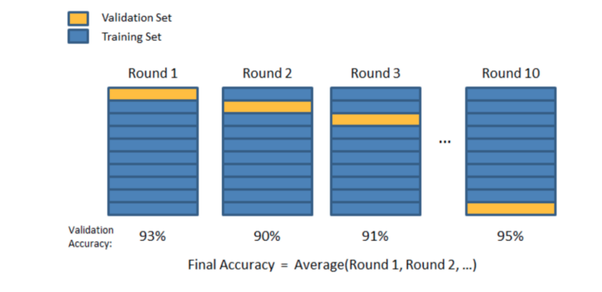
K-fold vs. Random-subsamples vs. Leave-one-out vs. Leave-p-out
- K-fold
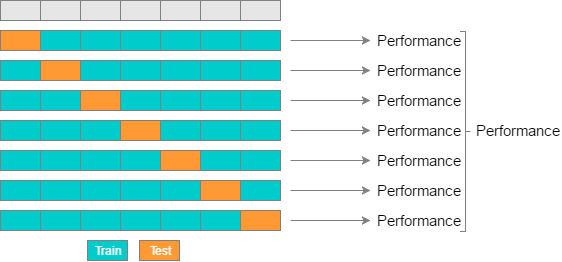
- Random-subsamples
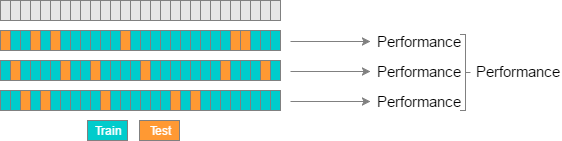
- Leave-one-out
- n개의 데이터에서 1개를 test set으로 정하고 나머지 n-1개의 데이터로 모델링을 하는 방법.
- 데이터 수 n이 크다면, n번의 모델링을 진행해야 하기 때문에 시간이 오래 걸린다.
- 작은 데이터 셋에서 좋은 결과를 얻는다.
- 회귀, 로지스틱, 분류모형 등에 다양하게 적용이 가능하다.

- Leave-p-out

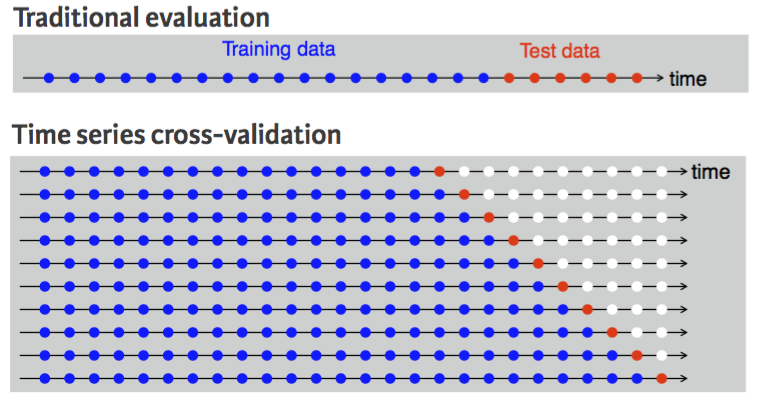
시계열 데이터 준비
- 시계열 데이터인 경우 랜덤성(set.seed)을 부여하면 안되고 시간축 유지가 핵심이다.
- 훈련셋 : 가장 오래된 데이터
- 검증셋 : 그 다음 최근 데이터
- 테스트셋 : 가장 최신의 데이터

시계열 데이터를 one/two step 교차 검증을 하는 이유
: 비시계열은 통합적인 퍼포먼스 산출이 가능하지만 시계열은 그렇지 못하다.
ex) tranditional evaluation 표를 보자, 만약 1,2월이 train set, 3월이 test set일 때, 3월 한달간 각각의 날짜마다의 performance는 달라질 수 밖에 없다. 즉, 가까운 미래는 예측력이 높지만 먼 미래는 예측력이 떨어질 수 밖에 없게 되는 것.
- 과거 정확성이 높더라도 미래의 정확성을 보장할 수 없기에, 미래 모든시기 검증을 추천한다.
One-step Ahead Cross-validation
: 1번째 시점을 test set으로 사용
Two-step Ahead Cross-validation
: 2번째 시점을 test set으로 사용

one-step을 일반적으로 사용하지만, one과 two step은 따로 모델을 만들어야 하고 각각 필요에 따라(단기,장기예측) 선택해여 진행해야 한다.
