데이터 베이스 #6
2022/05/30
학교의 졸업 프로젝트로 맡은 과제를 마무리 하면서 복습할 겸 적어봅니다.
해당 프로젝트에서 본인이 맡은 업무는 코인 크롤링과 데이터 베이스 설계 및 프론트 페이지와 연동이었다.
코인 크롤링은 이후 따로 다룰 예정이다.
데이터 베이스 선정
우선 NoSql기반의 MongoDB를 사용했다.
활용할 데이터는 각 코인의 날짜별 종가, 거래량, greed&fear 지수와 같은 이미 정해져서 수정 될 일이 없거나 전처리와 감정 분석을 통해서 매겨지는 점수이기 때문에 수정 및 삭제에 대해서 크게 신경 쓸 필요가 없었다. 보통 데이터를 저장하고 수정한다면 RDBMS에서 연쇄적으로 삭제하는 등의 cascade 부분을 생각하게 되는데, MongoDB는 해당 부분에서 조금 번거롭다? 고 할 수 있었는데, 아마 하게 된다면 find를 통해서 분류 후 삭제하거나 수정하는 방법이 되지 않을까 싶다. 아무튼, 해당 부분은 크게 중요하게 생각하지 않아서, 간단하면서 sub document와 같은 유용한 점들이 있어서 MongoDB를 택하게 되었다. 뿐만 아니라 데이터를 접근하고 가공하는 것에 있어 비교적 자유로울 것이라고 생각하였다.
MongoDB?
MongoDB를 사용하였다고 했는데, MongoDB가 무엇인가?
간단하게 데이터의 저장 형태가 DataBase > Collection > Documents 의 구조가 된다.
하나의 DB가 있고 아래 Collection이 있는데 Collection은 Document들의 집합이다. Document는 BSON형태로 Binary JSON이라고 한다. JSON형태로 사용했을 때의 단점들을 보완하여 사용할 수 있도록 만든 것이다. JSON의 구조는 그대로 가지고 있지만, 기계와 친한 binary 형태로 변경하여 저장했다는 것이 가장 큰 특징이다.
BSON과 JSON의 차이 : https://velog.io/@chayezo/MongoDB-JSON-vs.-BSON
데이터의 저장 및 활용
MongoDB에다가 데이터를 저장하는 방법은 다양했다. 우선 언어를 사용하기 이전에 MongoDB와 친해지기 위해서 사용한 것이 MongoDB에서 제공하는 MonogoDB Compass를 사용하였다. 일반적인 프로그램처럼 사용해서 CSV파일이나 Json을 각 필드를 구분해서 저장하고 드래그 드랍하면 원하는 대로 데이터를 저장하게 된다.
- GUI 도구
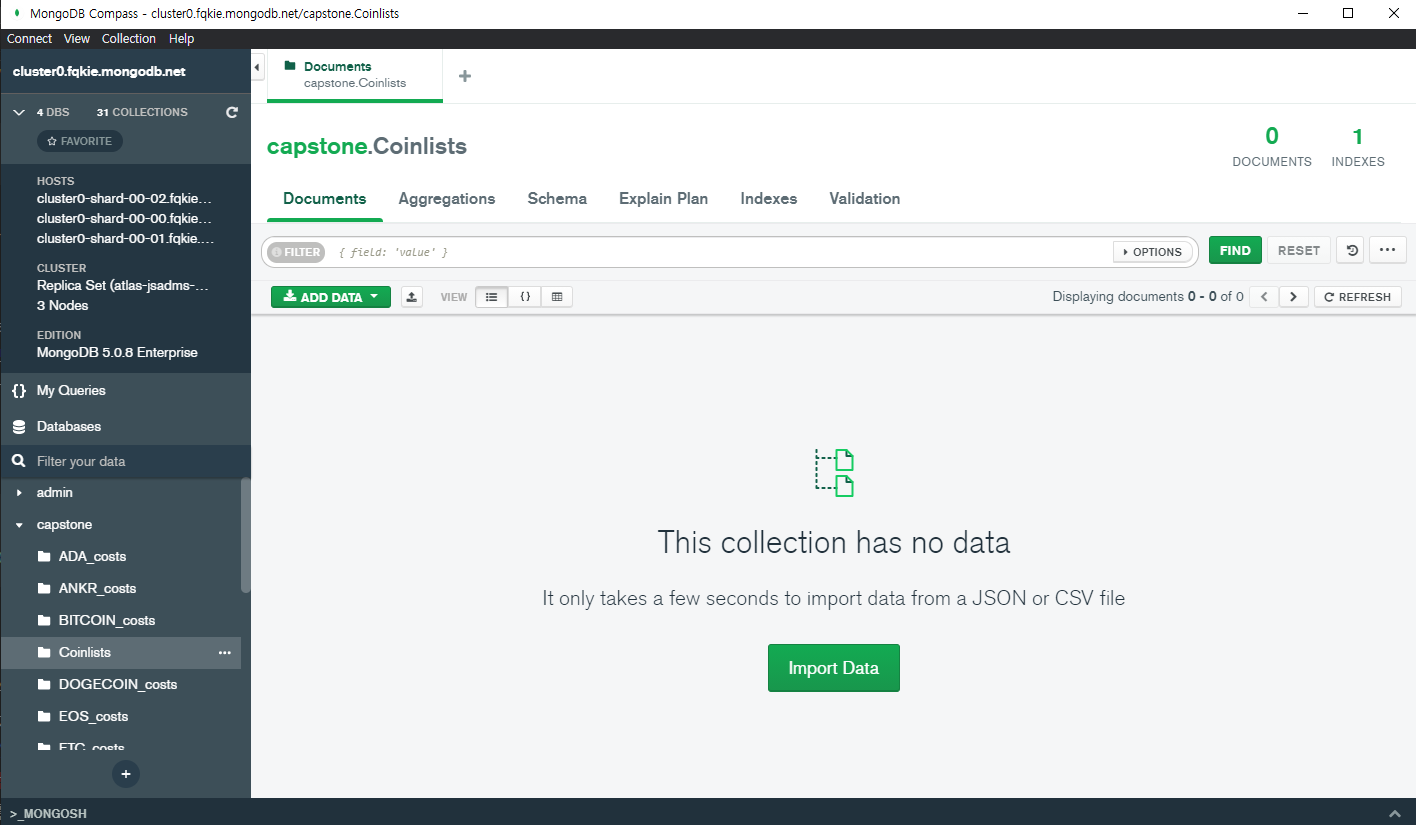
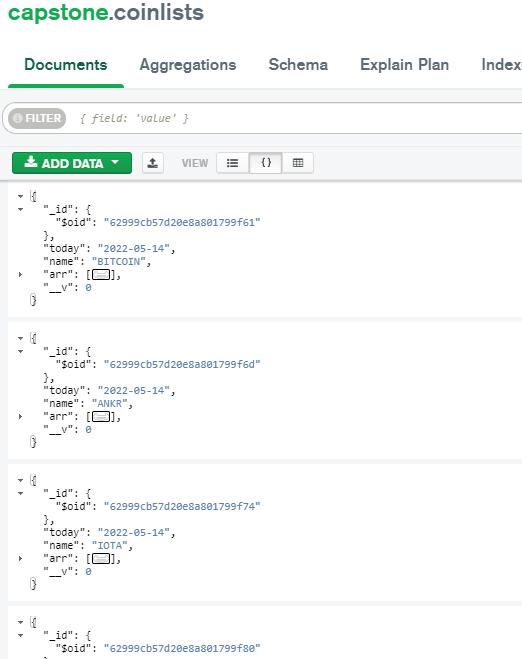
그 외의 방법으로는 Python환경에서 pymongo를 이용하는 방법과, javascript를 사용하는 환경에서 mongoose를 이용하는 것이었다. Python환경에서는 코인 데이터를 크롤링해서 넣어보는 테스트를 진행하였고, 이후 전처리 및 분석된 데이터를 저장하기 위해서 사용했다.
- pymongo(python)
데이터를 저장하기 위해서 csv파일 형식으로 저장되어있는 파일을 읽어서 해당 내용을 활용하기 적합한 자료형으로 구분하여 MonogDB에 저장하였다.
- mongoose(javascript)
주로 데이터를 불러와서 가공하는 것에 사용되었다. 저장을 위해서 사용한 것은 각 코인들에 대한 정보를 가져오고 하루 날짜를 기준으로 여러 코인에 대한 당일 데이터를 따로 저장하기 위해서 새로운 collection을 생성하고 저장해주는 것이었다. 스키마 형태는 아래와 같다.
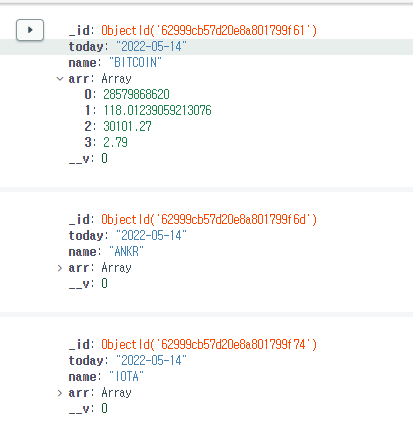

그리고 local에 데이터를 저장하는 방식 말고, mongodb에서 제공하는 mongodb atlas의 cluster를 사용해서, 클라우드 상에 데이터를 저장하도록 하여 원격 작업이 가능하다.
시각화(front와의 연동)
사실 가장 애먹었던 부분이었다. Front페이지만을 만들어보거나, 로컬 혹은 쿠키에 저장하고 가져오는 구현은 해보았지만 DB를 사용해서 해당 데이터를 불러오는 것에 대한 지식은 전무했기 때문이다.
우선 우리 팀에서 시각화를 위해 React를 사용하였다. 구글링을 통해서 대부분 MongoDB, Express, React, Nodejs 이렇게 MERN 스택이라고 불리는 것들이었다. 일단 하나씩 찾아보면서 해보았다. 수 많은 시행착오 끝에 express router를 이용해서 get을 통해 front에서 요청을 한다면 server로 와서 해당 데이터를 보내주는 방식으로 데이터에 접근을 할 수 있다는 것이다. 방식은 주소 옆에 /speed, /chart와 같이 특정한 키워드를 넣어서 구분해주는 것인데, 이를 나는 시각화 페이지에서 각 섹션마다 요구하는 데이터가 달라서 각 섹션에 별도의 키워드를 설정하여, server코드에서 필요한 데이터를 보내주도록 하였다.
-
섹션1,2 (speedometer, graph)
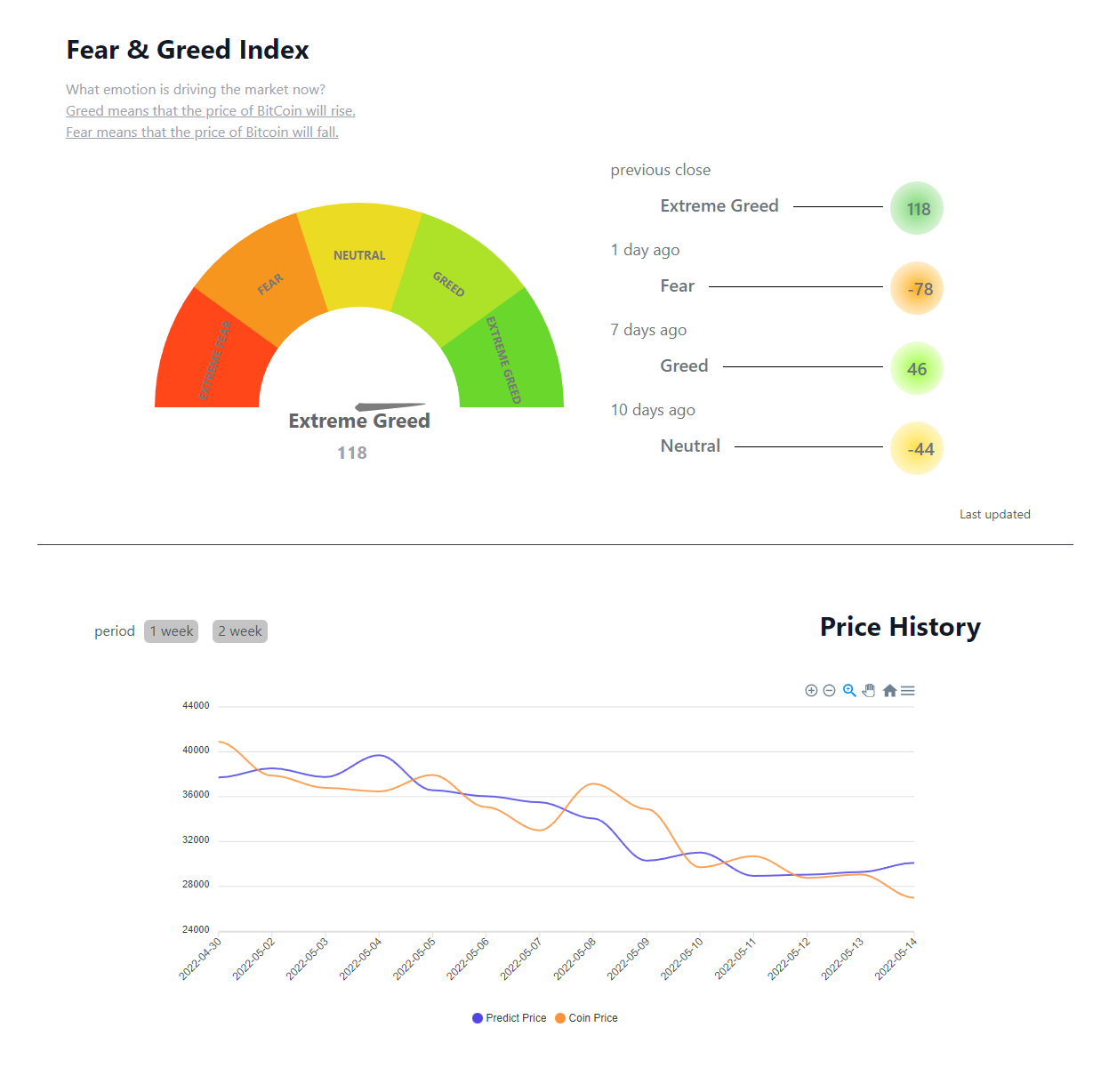 먼저 첫번째 섹션은 당일, 1일, 7일, 10일전의 gread&fear 수치를 요구한다. 해당하는 데이터의 값에 따라 배경 색상이 달라지거나 눈금이 달라진다. 여기서 중요한 것은 해당 일자를 기준으로 n일 전의 데이터 중 특정 데이터를 가져오도록 하는 것이다. app.get을 통해서 '/spd'라는 키워드로 호출을 하게 되면 내부에서 데이터를 추려서 전달한다.
먼저 첫번째 섹션은 당일, 1일, 7일, 10일전의 gread&fear 수치를 요구한다. 해당하는 데이터의 값에 따라 배경 색상이 달라지거나 눈금이 달라진다. 여기서 중요한 것은 해당 일자를 기준으로 n일 전의 데이터 중 특정 데이터를 가져오도록 하는 것이다. app.get을 통해서 '/spd'라는 키워드로 호출을 하게 되면 내부에서 데이터를 추려서 전달한다.app.get('/spd', (req, resp) => {...})두번째 섹션은 오늘을 기준으로 2주간의 종가와 예측 종가의 데이터를 필요로 한다. 첫번째와 달리 해당 기간동안의 데이터를 요구하기 때문에 다른 형태로 데이터를 전달해주어야 한다. 또한 예측값과 실제값 두가지의 데이터를 요구하기 때문에 해당 데이터들을 묶어서 보내주도록 했다. 같은 방식으로 '/chart'를 키워드로 호출을 하게 되면 데이터를 추려서 전달하도록 하게 하였다.
app.get('/chart', (req, resp) => {...}) -
섹션3 (rank)
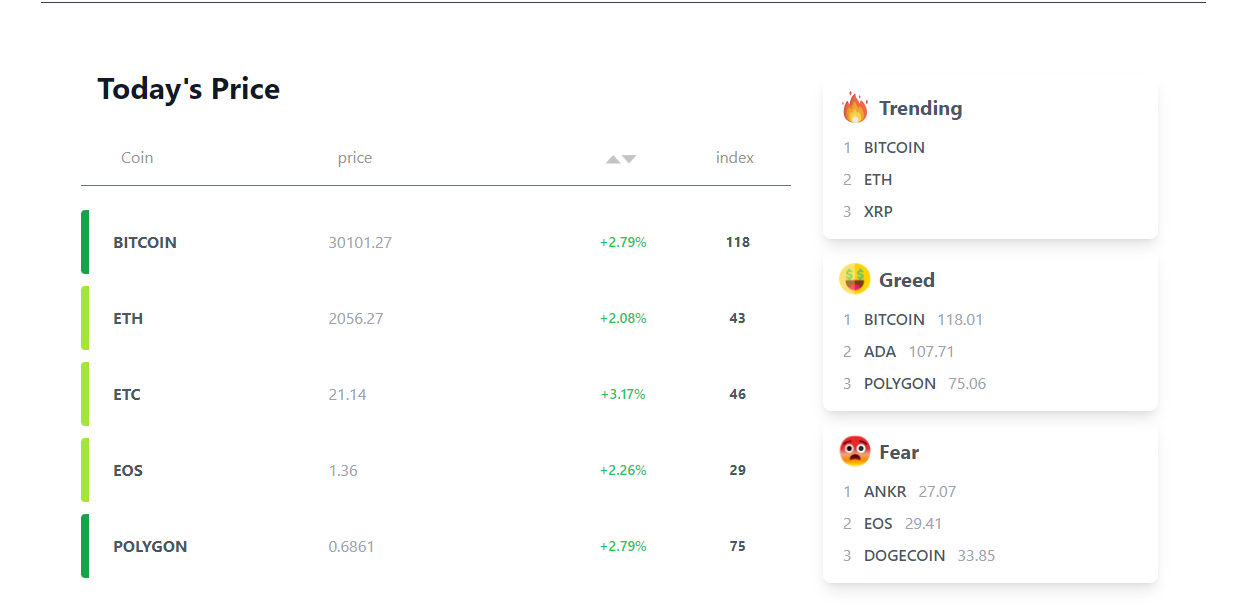 세번째 섹션은 여러가지 종목들의 오늘 날짜를 기준으로 순위를 보여준다. 여러가지 기준이 있고 여기에 해당하는 데이터들을 활용하여 나타낸다. 여기서는 단순히 데이터를 추려서 가져오는 것이 아니라, server코드에서 데이터를 한번 가져오고 거기서 새롭게 collection을 만들어서 저장 후 해당하는 데이터들을 보내주는 방식으로 했다. 그렇게 해서 날짜를 기준으로 각 종목별로 가지는 값들을 배열로 만들어서 전달해주었다.
세번째 섹션은 여러가지 종목들의 오늘 날짜를 기준으로 순위를 보여준다. 여러가지 기준이 있고 여기에 해당하는 데이터들을 활용하여 나타낸다. 여기서는 단순히 데이터를 추려서 가져오는 것이 아니라, server코드에서 데이터를 한번 가져오고 거기서 새롭게 collection을 만들어서 저장 후 해당하는 데이터들을 보내주는 방식으로 했다. 그렇게 해서 날짜를 기준으로 각 종목별로 가지는 값들을 배열로 만들어서 전달해주었다.
마찬가지로 '/rank'라는 키워드로 호출하면 데이터를 전달하도록 했다.app.get('/rank', (req, resp) => {...})
문제들
우선 데이터 자체를 저장하고 불러오는 것에는 무리가 없었고, 원하는 기준에 맞게 데이터를 가공하는 것 또한 기본 자료형들로 충분히 활용 가능하고, 간단했다. 문제는 front와 연결하는 문제, 어떻게 값을 전달하는지에 대한 문제, front페이지에서 렌더링을 하는 순서와 타이밍에 대한 문제였다.
1. front와 연동하여 데이터를 전달하는 방법
-> 이 부분은 express router를 이용해서 해결할 수 있었다. 처음 router에 대한 개념이 부족해서 헤맸지만, 직접 하나씩 해보면서 이해를 할 수 있었다. 물론 localhost:3000,3001의 호스트와 서버를 지정하는 것에서는 오랜시간 헤맸지만, 5000으로 할당함으로써 해결했다.
2.front페이지 렌더링 순서
-> 렌더링 순서에 관한 문제는 각 페이지 별로 useEffect를 사용해서 fetch를 호출하는 방식으로 했는데 여기서 비동기로 인한 문제와 값으로 전달받은 데이터를 인덱스로 2차원 배열이상의 값을 참조하질 못하여, 화면에 데이터를 보여주지 못하는 문제가 생겼다.
1. useLayoutEffect를 사용
2. 각 컴포넌트에 데이터를 전달하고 해당 컴포넌트를 구성하는 코드에서 새로운 배열에 전달해주고 해당 값을 사용하도록 했다.
이 과정을 거치고 나서 해당 문제가 해결되었다.
