
웹 크롤러
목적: 웹에 새로 올라오거나 갱신된 콘텐츠(웹 페이지, 이미지 or 비디오, PDF 파일 등)를 찾아내는 것
이용 방식
-
검색 엔진 인덱싱
크롤러의 가장 보편적인 용례이며, 웹 페이지를 모아 검색 엔진을 위한 로컬 인덱스 생성
웹 크롤러가 HTML 파일 정보를 모두 저장한 후에 이 정보에 대해 빠르게 접근할 수 있도록, 쉽게 말해 ‘정리’ 하는 과정
-
웹 아카이빙
나중에 사용할 목적으로 장기보관하기 위해 웹에서 정보를 모으는 절차
ex) 국립 도서관이 크롤러를 돌려 웹 사이트를 아카이빙
-
웹 마이닝
인터넷에서 유용한 지식을 도출해내는 것
ex) 유명 금융 기업 → 크롤러를 사용해 주주 총회 자료나 연차 보고서를 다운 받아, 기업의 사업 방향 탐색
-
웹 모니터링
인터넷에서 저작권이나 상표권이 침해되는 사례 모니터링
요구사항
- 용도: 검색 엔진 인덱싱
- 매달 수집해야 하는 페이지 수: 10억 개
- 수집한 웹 페이지 5년간 저장
- 중복된 콘텐츠 포함하는 웹페이지 무시
설계안
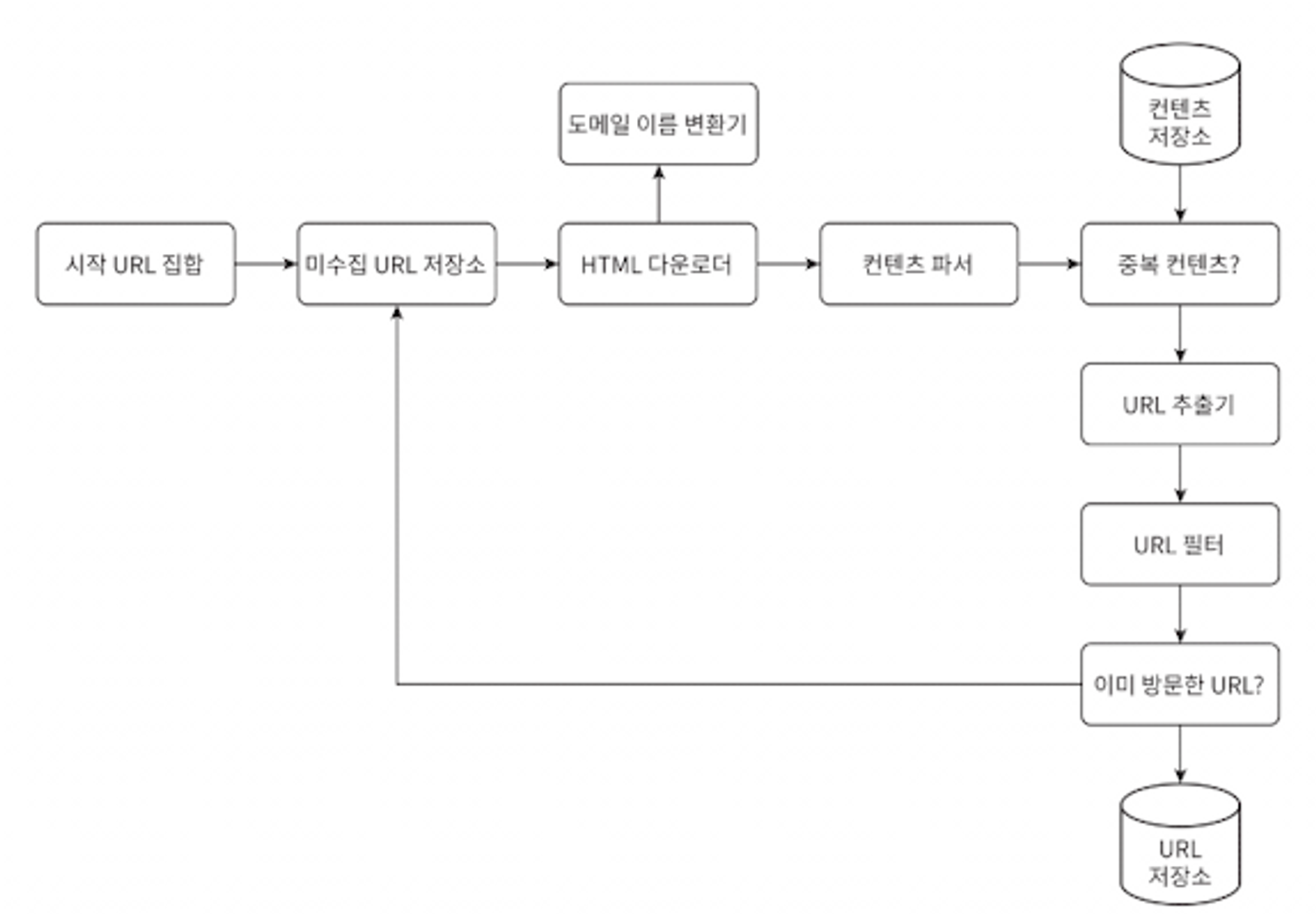
시작 URL 집합
크롤러가 가능한 많은 링크를 탐색할 수 있도록 하는 URL을 고르는 것이 바람직
미수집 URL 저장소
웹 크롤러는 다운로드할 URL과 다운로드된 URL, 이렇게 2가지로 나누어 관리
‘다운로드할 URL’ 을 저장 관리하는 컴포넌트가 바로 미수집 URL 저장소
HTML 다운로더
미수집 URL 저장소에 있는 URL의 웹 페이지를 다운로드하는 컴포넌트
도메인 이름 변환기
웹 페이지를 다운 받기 위해 URL 주소 → IP 주소로 변환하는 절차 필요
HTML 다운로더는 ‘도메인 이름 변환기’를 이용해 URL에 대응되는 IP주소 얻음
콘텐츠 파서
웹 페이지 다운로드 후, 파싱과 검증 절차 필요
크롤링 서버 안에 파서를 구현하면 크롤링 과정이 느려질 가능성이 있어, 독립된 컴포넌트로 구현
중복 콘텐츠?
중복된 콘텐츠 문제를 해결하기 위해 자료 구조를 도입해 데이터 중복을 줄이고, 데이터처리에 소요되는 시간을 줄인다.
웹 페이지의 해시 값 비교
콘텐츠 저장소
HTML 문서를 보관하는 시스템
대부분의 콘텐츠는 디스크에 저장, 인기 있는 콘텐츠만 메모리에 저장
URL 추출기
HTML 페이지를 파싱하여 링크들을 골라내는 역할
<body>
<li><a href="/wiki/Cong_Weixi" title="Cong Weixi">Cong Weixi</a></li>
<li><a href="/wiki/Kay_Hagan" title="Kay Hagan">Kay Hagan</a></li>
<li><a href="/wiki/Vladimir_Bukovsky" title="Vladimir Bukovsky">Vladimir Bukovsky</a></li>
<li><a href="/wiki/John_Conyers" title="John Conyers">John Conyers</a></li>
</body>위와 같은 HTML 코드에 있는 상대 경로는 `https://en.wikipedia.org` 를 붙여 절대 경로로 변환
URL 필터
특정한 콘텐츠 타입이나, 파일 확장자를 갖는 URL, 접속 시 오류가 발생하는 URL, 접근 제외 목록(deny list)에 포함된 URL 등을 크롤링 대상에서 배제하는 역할
이미 방문한 URL?
이미 방문한 적이 있는 URL인지 추적하면, 같은 URL을 여러 번 처리하는 일 방지 → 서버 부하 감소 및 시스템이 무한 루프에 빠지는 일 방지
사용되는 자료구조로는 블룸 필터 or 해시 테이블
URL 저장소
이미 방문한 URL을 보관하는 저장소
상세 설계
DFS vs BFS
웹은 유항 그래프 형태이다. 페이지는 노드이고, 하이퍼링크가 엣지이다.
그래프 탐색 방법은 DFS와 BFS가 있는데, DFS (Depth-First Search) 는 좋은 선택이 아닐 수도 있다. (깊이 자체가 가늠하기 어렵기 때문)
따라서 보통 BFS를 사용해 탐색할 URL을 집어넣고, 다른 한쪽으로는 꺼내는 FIFO 큐를 사용
하지만 이 구현 방법에는 2가지 문제점이 있다.
- 한 페이지에서 나오는 링크의 상당수는 같은 서버로 요청
- 한 페이지에서 추출한 모든 링크를 만약 병렬 처리하게 된다면, 해당 사이트의 서버는 수많은 요청으로 과부하 발생 가능 → 예의 없는 크롤러
- 표준적 BFS 알고리즘은 URL 간 우선수위 존재 X
- 모든 웹 페이지가 같은 품질, 중요성을 갖지 않기 때문에 페이지 순위, 사용자 트래픽 양, 업데이트 빈도 등 여러 가지 기준에 따라 우선수위 구별 필요
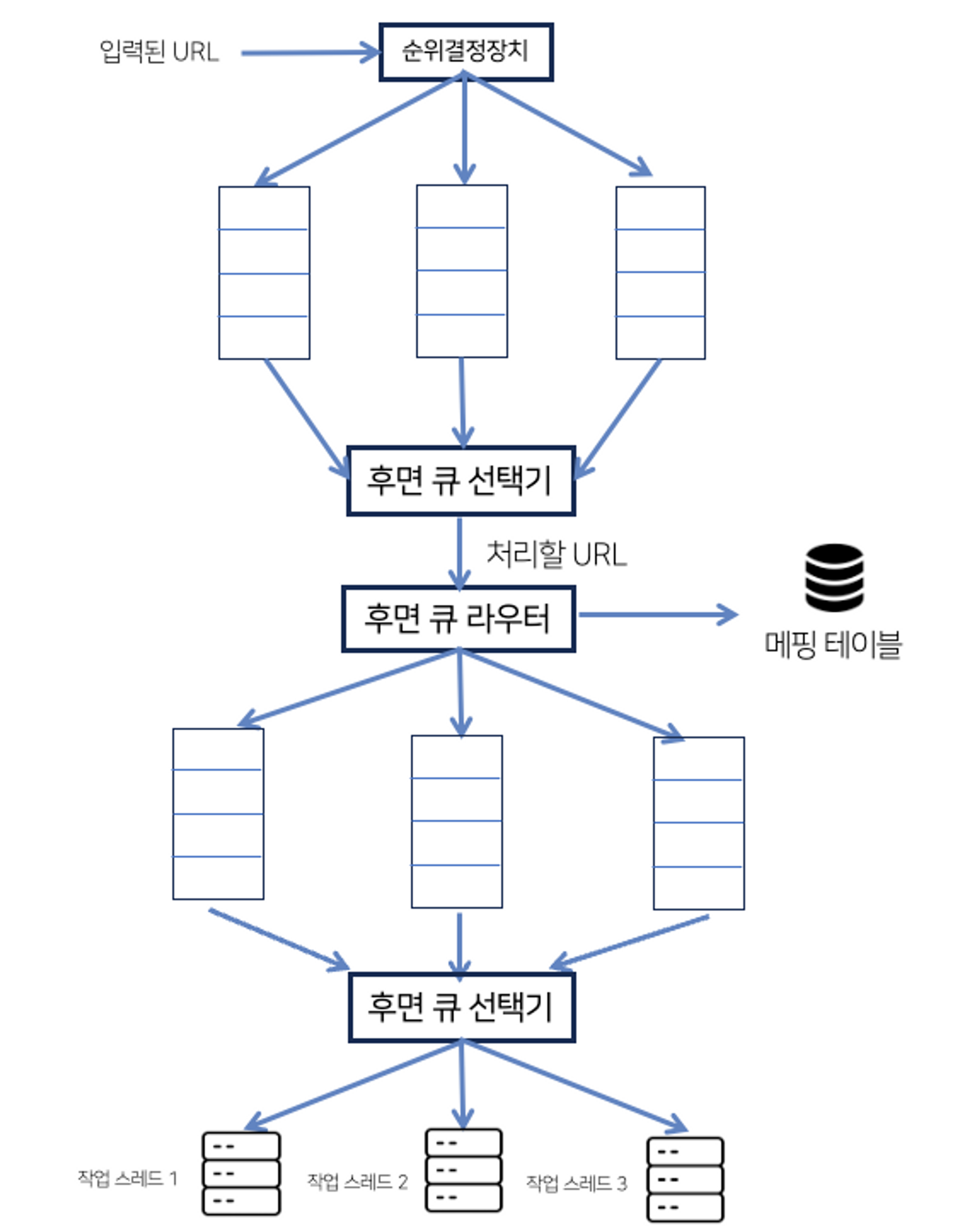
미수집 URL 저장소
미수집 URL 저장소만 잘 구현한다면, 예의 없는 크롤러에서 벗어날 수 있다.
예의
무례한 일: 수집 대상 서버로 짧은 시간 안에 너무 많은 요청을 보내는 것
예의 바른 크롤러를 만드는 데 있어서 지켜야 할 한 가지 원칙
: 동일 웹 사이트에 대해서는 한 번에 한 페이지만 요청
- 큐 라우터(queue router): 같은 호스트에 속한 URL은 언제나 같은 큐로 가도록 보장
| 호스트 | 큐 |
|---|---|
| wikipedia.com | b1 |
| apple.com | b2 |
- 매핑 테이블: 호스트 이름과 큐 사이의 관계 보관 테이블
- FIFO 큐: 같은 호스트에 속한 URL은 언제나 같은 큐에 보관
- 큐 선택기: 큐에서 URL을 꺼내, 해당 URL을 다운로드하도록 지정된 작업 스레드에 전달
- 작업 스레드: 전달된 URL을 다운로드
신선도
신선도
웹 페이지는 수시로 추가, 삭제 변경
→ 이미 다운로드한 페이지여도 주기적으로 재수집 필요
아래 두 가지 전략 사용
- 웹 페이지의 변경 이력 활용
- 우선순위 활용 → 중요한 페이지 더 자주 재수집
HTML 다운로더
Robots.txt
웹사이트가 크롤러와 소통하는 표준적 방법
이 파일에는 크롤러가 수집해도 되는 페이지 목록이 들어 있다.
이 파일은 주기적으로 다운받아 캐시에 보관
성능 최적화
- 분산 크롤링
- 크롤링 작업을 여러 서버에 분산
- 각 서버는 여러 스레드를 돌려 다운로드 작ㅇ버 처리.
- 도메인 이름 변환 결과 캐시
도메인 이름 변환기는 크롤러 성능의 병목 지점 중 하나
DNS 요청 처리 시간은 보통 10ms ~ 200ms 소요
- 크롤러 스레드 가운데 어느 하나 이 작업 중이라면, 다른 스레드의 DNS 요청은 전부 block
- DNS 조회 결과로 얻어진 도메인 이름과 IP 주소 사이의 관계를 캐시에 보관 → cron job으로 주기적으로 갱신하도록
- 지역성
- 크롤링 작업 수행 서버 지역별로 분산
- 크롤링 서버와 대상 서버가 지역적으로 가깝다면, 다운로드 시간 절약
- 짧은 타임아웃
- 응답이 아예 오지 않을 경우를 대비해 최대 얼마나 기다릴지 시간을 정해놓기
안정성
- 안정 해시: 다운로더 서버들에 부하를 분산할 때 적용 기술
- 크롤러 상태 및 수집 데이터 저장: 장애 발생 후에도 쉽게 복구할 수 있도록 크롤링 상태와 수집된 데이터 지속적 저장장치에 기록
- 예외 처리
- 데이터 검증
문제 콘텐츠 감지 및 회피
- 중복 콘텐츠
- 해시나 체크섬을 사용해 중복 콘텐츠 감지
- 거미 덫 크롤러를 무한 루프에 빠뜨리도록 설계한 웹 페이지
- 사람이 수작업으로 덫을 확인 후, 덫이 있는 사이트를 크롤러 대상에서 제외 or URL 필터 목록에 설정
- 데이터 노이즈
- 가치가 아예 없는 콘텐츠는 제외해둘 것
추가로 고려해볼 사항
- 서버 측 렌더링
- 원치 않는 페이지 필터링
- 데이터베이스 다중화 및 샤딩
- 수평적 규모 확장성
- 가용성, 일관성, 안정성
- 데이터 분석 솔루션
