Bag-of-Words
- 문장 혹은 문단이 주어졌을 때, 이를 unique한 단어 단위로 dict에 등록하여 저장 한 후, data를 dict의 encoding 된 번호로 vector화하여 사용하는 방법이다.
Bag-of-Words 예시

- 위와 같이 주어진 두개의 문장을 단어 단위로 나눈 후, dict에 단어 단위로 저장한다.

-
dict에 저장된 단어들을 one-hot encoding을 통해 하나의 vector 형태로 만들어준다
-
dict를 기반으로 만들어 진 각 vector들의 cosine similarity는 0 이고, (당연하다.) 유클리안 거리는 루트 2이다.

-
맨 앞에서 예시로 든 2개의 문장을 변환한 one-hot-encoding vector로 표현 했을 때, 위와 같은 vector로 나타낼 수 있다.
-
구해진 vector로 두개의 문장을 유사도를 구하거나(cosine similarity) 단어가 주어졌을 때, 해당 문장일 확률을 알 수 있다.
NaiveBayes Classifier
- 위에서 배운 bag-of-word 기법을 이용해 NaiveBayes Classifier에 만들어진 vector를 적용하여 문장이 어떤 분야에 속하는지에 대한 문제를 풀 수 있다.

-
위 사진에서 P(d/c)P(c)를 해석해 보자. c가 주어진 단어라 했을 때, d는 문장 혹은 문단 아니면 더 큰 Dataset이라고 생각할 수 있다.
-
w1~wn이 독립적일 때 위 식은 성립 할 수 있다. (위의 one-hot-encoding을 진행 할 때 이 부분은 이미 충족했다고 볼 수 있다.)
NaiveBayes Classifier 예시

- 위 처럼 2가지 Class로 분류된 문장이 있고, 어떤 문장이나 단어가 주어졌을 때 어떤 Class에 속하는지 맞추는 문제가 있다고 해보자.
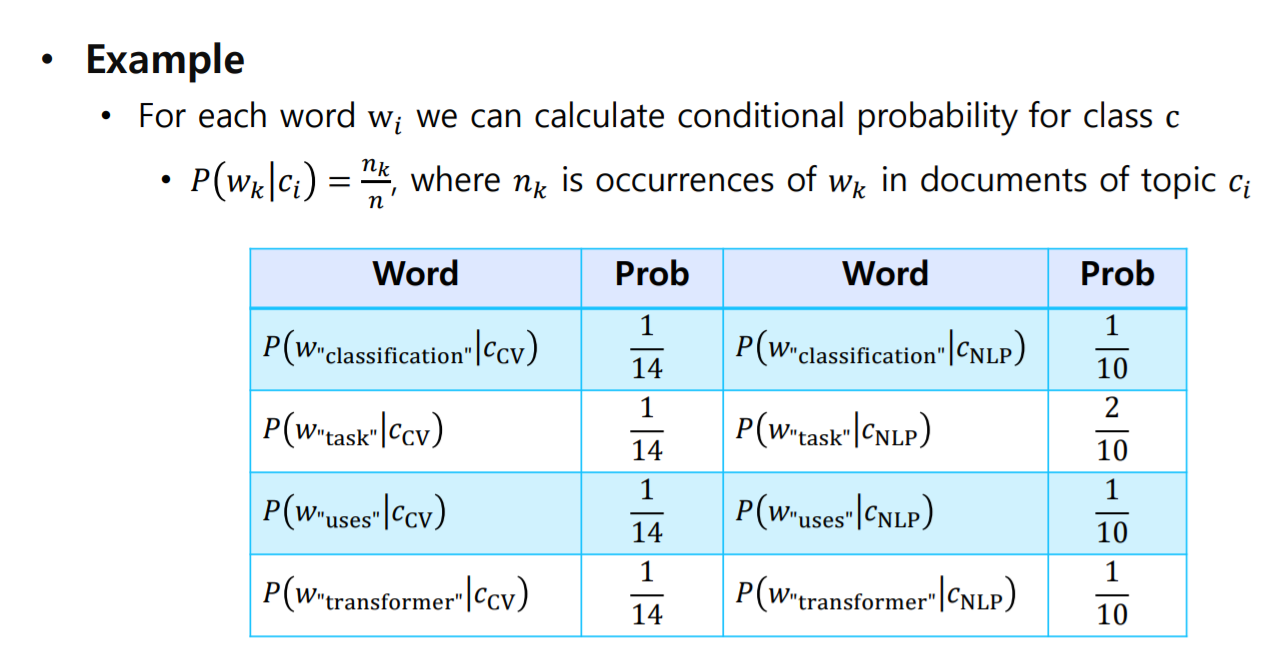
- 그 문제를 해결 하기 위해 주어진 문장에 bag-to-words 기법을 적용 한 후, 각 단어에 대한 조건부 확률을 구하면 다음과 같다.

-
이렇게 구해진 확률들을 위에서 배운 NaiveBayes Classifier 식에 적용 할 수 있다.
-
"Classification task uses transformer"라는 문장을 주고 어떤 분야에 해당하는 문장인지 맞추라고 했을 때, 베이지안 분류기에 의해서 위와 같은 식이 계산되고 이 문장은 cv보다 NLP의 확률이 높다고 판단 되기에 NLP로 분류된다.
-> 학교에서 선형대수를 배울 때, 인간은 3차원 밖에 인식을 못하는데 왜 그 보다 더 높은 차원의 유사도나 vector의 길이 등을 구하려고 할까 이해되지 않았는데, 이렇게 사용할 수 있었다는게 놀랍다.... 더 공부해야겠다.
