Sequence to Sequence with Attention
LSTM Model의 한계
LSTM은 기존의 RNN의 Long Term Dependency 문제를 해결했다.
하지만 RNN 구조가 가지고 있는 근본적 한계의 문제로 Long Term Dependency에 문제에대해 완전히 자유로울 수 없었다.
왜냐하면, 엄청나게 긴 Time Step이 지나게 되면 그 만큼의 정보를 cell stage에 저장하여 활용할 수 있어야하는데, 제한된 output 차원에의해 그 만큼의 정보를 전부 담아내서 활용할수 없기 때문이다.
Sequence to Sequence
Sequence to Sequence가 활용되는 문제
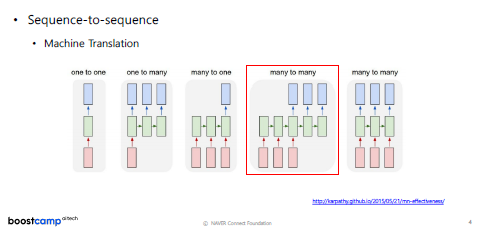
- Seq to Seq 모델은 Many to Many 에서 주로 사용된다.
Sequence to Sequence의 구조
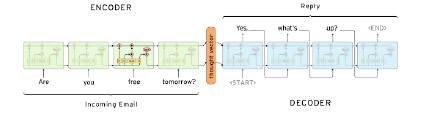
-
기존의 Seq to Seq 모델은 Encoder과 Decoder로 나눠져 있다.
-
Encoder는 각 Time Step의 input을 받아 학습하는 단계 이다.
-
Decoder는 Encoder에서 학습한 파라미터를 바탕으로 결과값을 생성하는 단계이다.
기본적으로 RNN 방식을 사용하기 때문에 Long Term Dependency 문제를 가지고 있다.
Sequence to Sequence with Attention
Sequence to Sequence with Attention의 구조
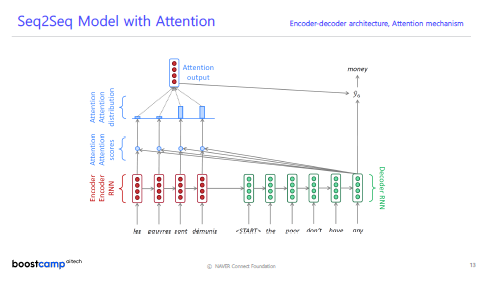
-
Attention Score
Attention Score는 Encoder의 각 Time Step의 Output vecter와 Decoder의 현재 Time Step의 Output vector를 내적하여 구한다. -
Attention Distribution
위에서 구한 Attention score vector를 SoftMax 활성함수를 거치게 하여 합 1이 되는 가중치 백터를 구한다. 이 벡터를 통해 어떤 Time Step의 input에 많은 정보를 가져와야 올바른 Output을 만들 수 있지 알게된다.
Attention Score Wight
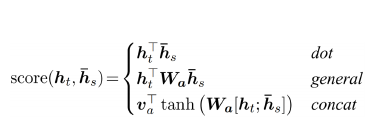
-
Attention Score를 어떻게 구할것인가?
주재걸 교수님은 Attention Score를 그냥 두백터의 Dot으로 구하는 것이 아닌 Wa라는 학습가능한 Parameter를 두 vector 사이의 선형변환에 사용 한다면 보다 적절한 Score를 구하는게 가능하다고 하셨다. 그 방법으로 제시한것이 바로 위의 3가지 이다.
-
왜 Wa를 넣는것이 더 적절한 Score를 구할 수 있는가?
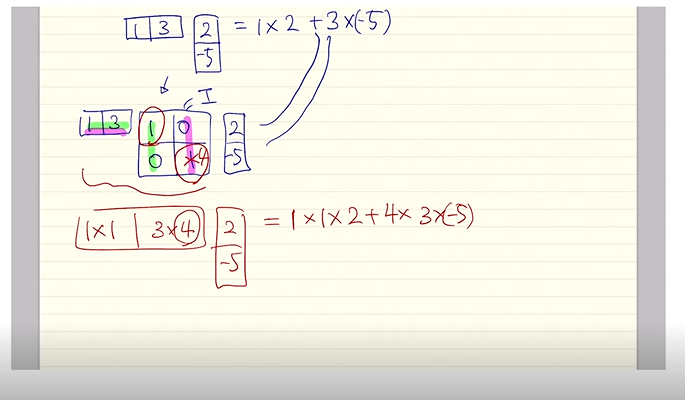
(이해가 쏙쏙되는 주재걸교수님의 필기 설명!!)
그 이유는 바로 그냥 Dot 연산을 진행하는 것 보다 W를 통한 선형변환을 통해 Dot을 수행하는것이 두 Vector의 원소 중 중요한 원소에 가중치를 주는 개념이 되어 조금더 정확한 Attention Score를 얻을 수 있게되기 때문이다.
결론! SoftMax 활성함수를 거친 Attention Score vector를 이용하여 현재 Time Step의 output을 만들 때, 학습에 사용된 문장의 어떤 Time Step에 집중할 것인지 판단하게 된다.
