Dataset
-
현재 Ai 분야에서는 잘 설계된 Model 구조 보다 Data의 양과 질이 Model의 성능을 좌우한다.
-
PyTorch에서는 Model에 Data를 잘 넣어줄수 있도록 편리한 API를 제공한다.
DataLoad
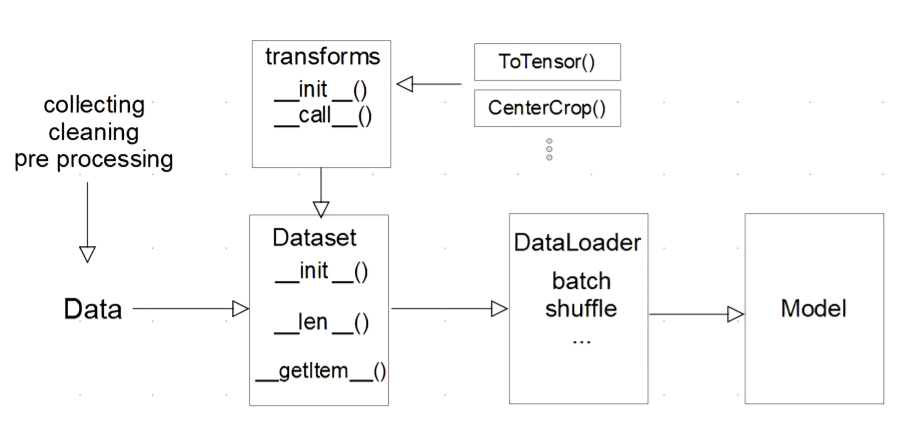
- 데이터 수집 및 전처리-> 정제된 Data-> init()각 데이터 정의, len() 데이터의 길이, getitem() idx에 해당하는 data를 반환 해줌(이때 data를 tensor로 변환해주는 단계를 거침)-> DataLoader 데이터를 가져오옴
DataSet의 정의
-
Data의 형태에 따라 init()단계에서 Data를 정의해줌
-
모든 Data를 init에서 모든 데이터를 가져올 필요는 없다.
DataLoader 의 정의
-
위에서 정의된 Dataset의 batch를 만들어주는 단계이다.
-
여러개의 Data를 한번에 묶어서 Model에 던져주는 역할을 함
-
이 때, data는 Tensor로 변한되어짐
-
DataLoader에는 여러가지 파라미터들이 있음 대표적으로 datch sizes는 각 batch에 들어갈 Data의 크기를 정해주는 것이고, shuffle은 Data를 섞어주는 것이다.
※ 특이하게 collate_fn이라는 파라미터가 있는데 일반적으로 text 데이터를 처리할 때 사용된다. batch로 짤려진 Text Data의 길이가 균일 하지 않을 때, 각 batch에 맞는 길이로 Data들을 Padding해주는 역할을 한다.

개발이 하고싶습니다.