BERT Model을 이용하여 나만의 Chatbot을 만들어보자
BERT Model 소개
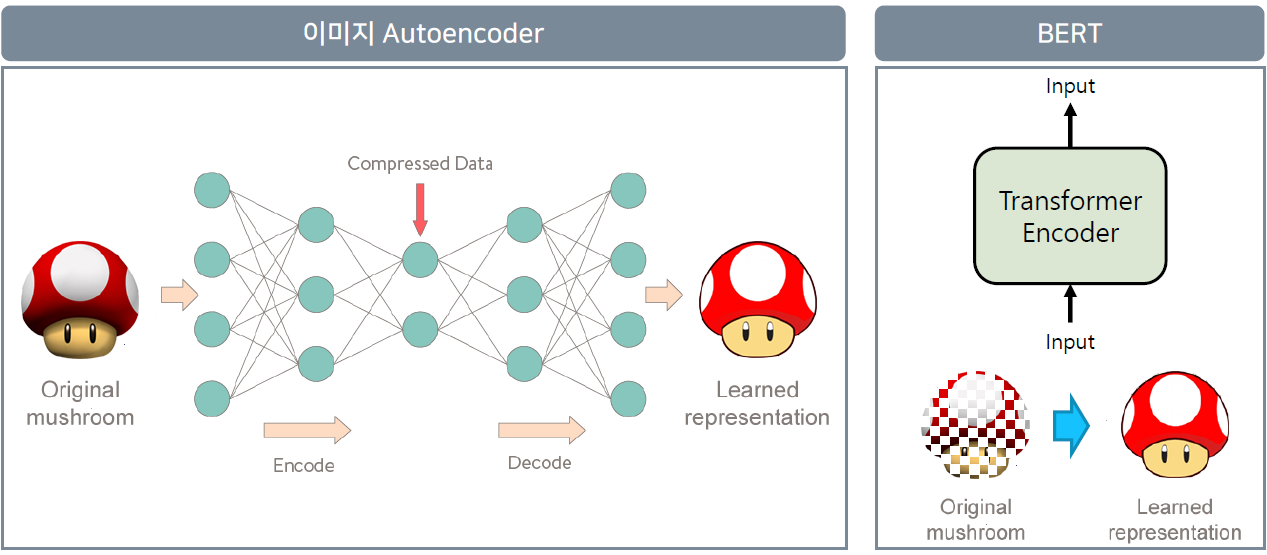
이미지를 만드는 Autoencoder와 BERT를 비교해보자. 이미지 Model은 Input으로 들어오는 Image가 주어졌을때, Encode와 Decode를 거쳐 Input이미지와 비슷한 새로운 이미지를 생성한다. 하지만 BERT는 들어오는 Input 이미지가 완전하지 않다. 들어오는 Image에 Mark를 씌워서 이 Mark된 부분을 예측하여 온전한 Image를 만들어 내는것이 Bert의 기본 개념이다.
GPT VS BERT
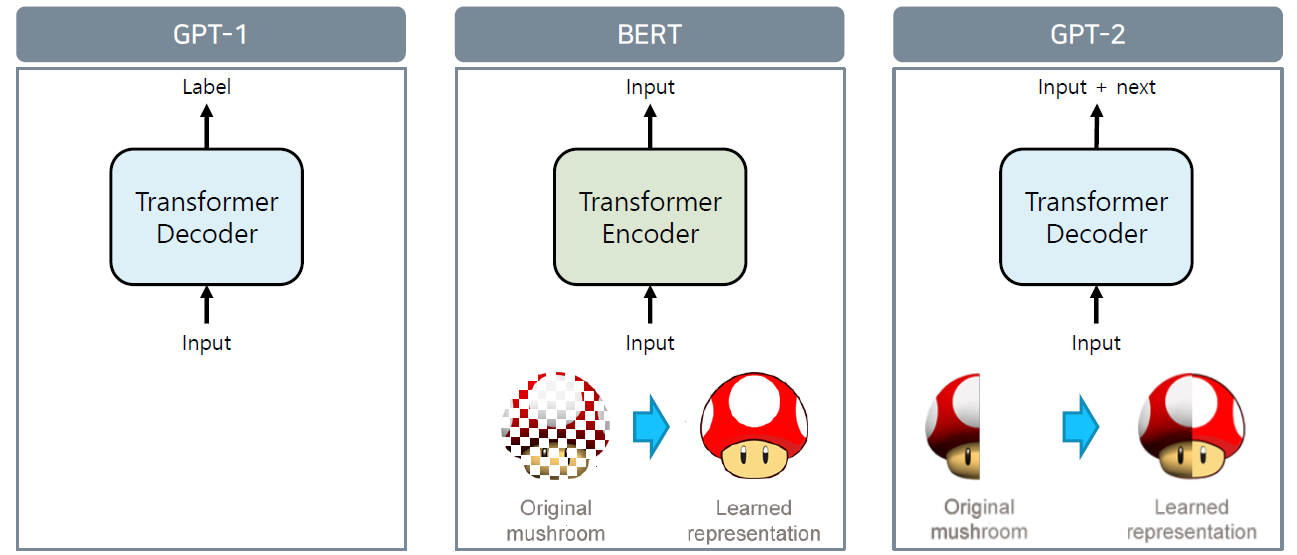
GPT와 BERT Model의 차이점은 간단하다. BERT는 앞서 설명한대로 Mark된 부분을 예측한다면, GPT는 Input을 반만 주고 나머지 반을 맞춰게하는 Model인 것이다.
BERT Model 구조

BERT Model 구조는 Transformer layer 12개가 쌓여 있는 구조이다. Input layer 에는 2개의 문장이 연결된 형태인 input이 들어온다. 문장의 형태는 문장의 시작을 알리는 [CLS] Token이 부착되고 문장을 연결해주는 [SEP] token이 부착된다.
BERT Model의 Input 구조
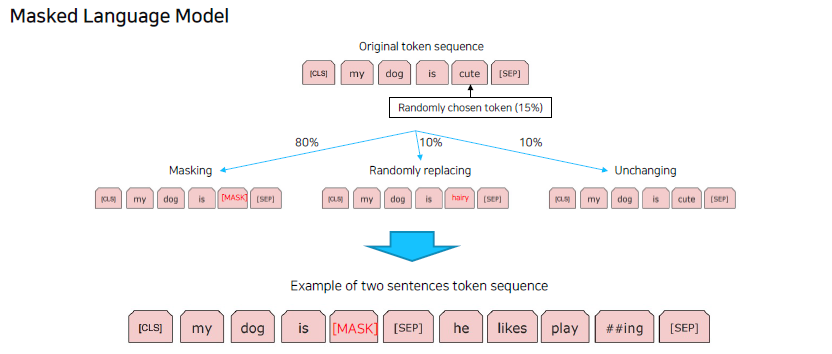
BERT의 input 구조는 2개의 문장이 이어진 형태로 들어오게 된다. 이 2개의 문장은 서로 연결되는 문장일 수 도 있고 무작위로 선택된 문장일 수 도 있다. 2개의 문장은 [SEP] Token으로 연결되고, Wordpice로 나눠진 문장의 단어들 중에 무작위적으로 [MASK] token이 부착되어 BERT model의 input으로 주워진다.
Pretrained BERT Load
구글에서 공개한 140개 언어를 지원하는 BERT base Multilingual 버전의 Pretrained Model을 가져와 Chat을 만들어보자.

Transformer에서 제공해주는 미리학습된 모델을 4개 줄의 명령어로 간단하게 Prertrianed Model과 Tokenizer를 불러올 수 있다.
chatbot 만들기
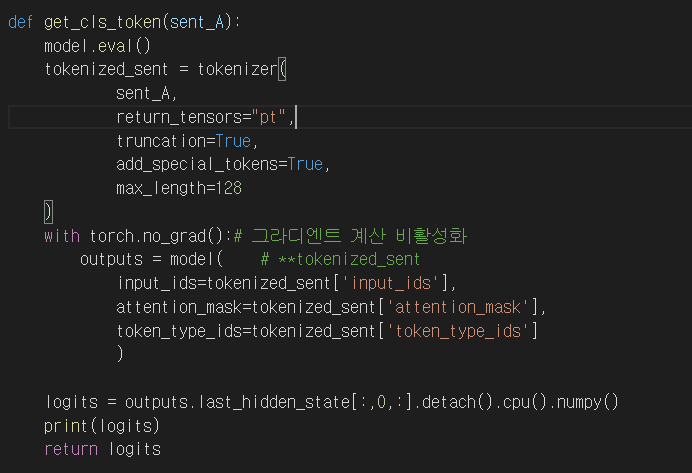
Sent_A를 파라미터로 받아서 위에서 설정한 Tokenizer를 사용하여 잘라주면 'input_ids','attention_mask','token_type_ids' colum으로 나눠진 dataset이 된다. 이것을 model 에 넣어주면 768개의 확률값들이 나온다.

이제 우리가 사용할 질문과 대답을 리스트 형태로 저장해서 chatbot에 들어갈 dataset을 만들어준다.

만들어진 dataset에 대한 확률값을 구하기위해 위에서 정의한 함수에 input으로 질문과 답변들을 넣는다.
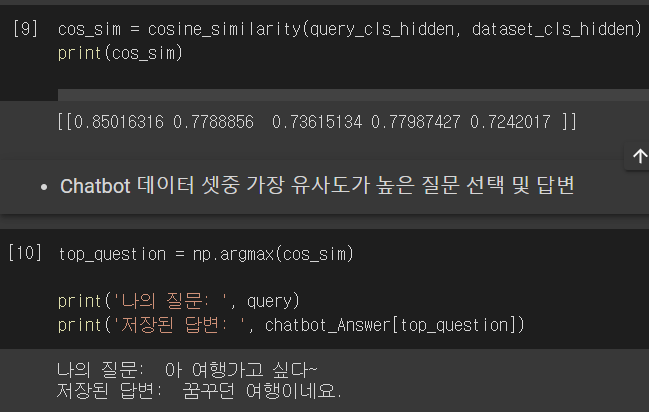
이렇게 구한 확률값에 대한 코사인유사도를 구해 질문과 가장 연관있는 답변을 선택하여 출력하는 간단한 chatbot을 만들어 볼 수 있다.

9번에서
query_cls_hidden이 정의되지 않았다는데 코드에도 query에 대한 건 없는데 이럴땐 어떻게 해야하나요