- CUDA의 Example code를 살펴본다.
1. deviceQuery
-
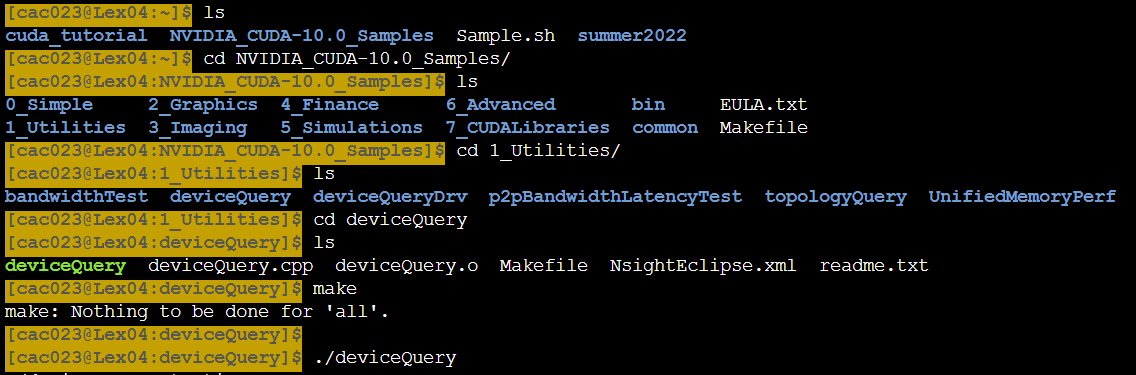
우리는 총 4개의 GPU를 가지고 있음.

-
0번 gpu를 살펴보면 gpu종류가 v100임.
-
capability 버전 넘버가 7.0인것도 체크하면 좋음. 버전에 따라서 성능과 할수있는 능력이 달라져서 그렇다. gpu개수가 많을 수록 더욱체크해야함.

-
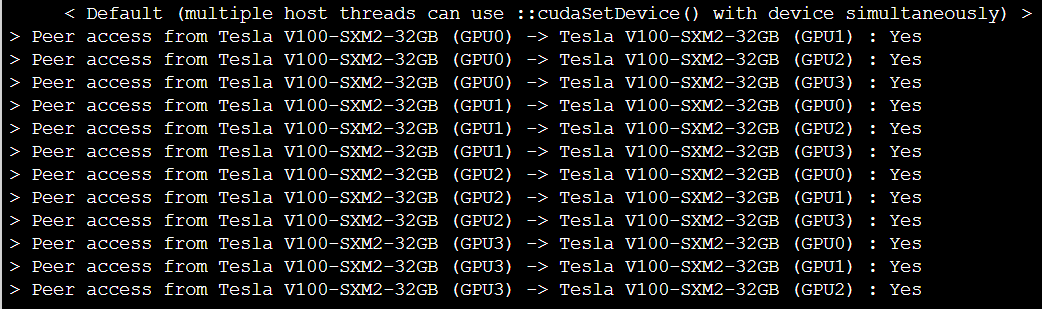
gpu간 통신가능한 gpu를 명시해줌.
-
ex) 0과 1번 gpu 통신가능
2. BandwidthTest
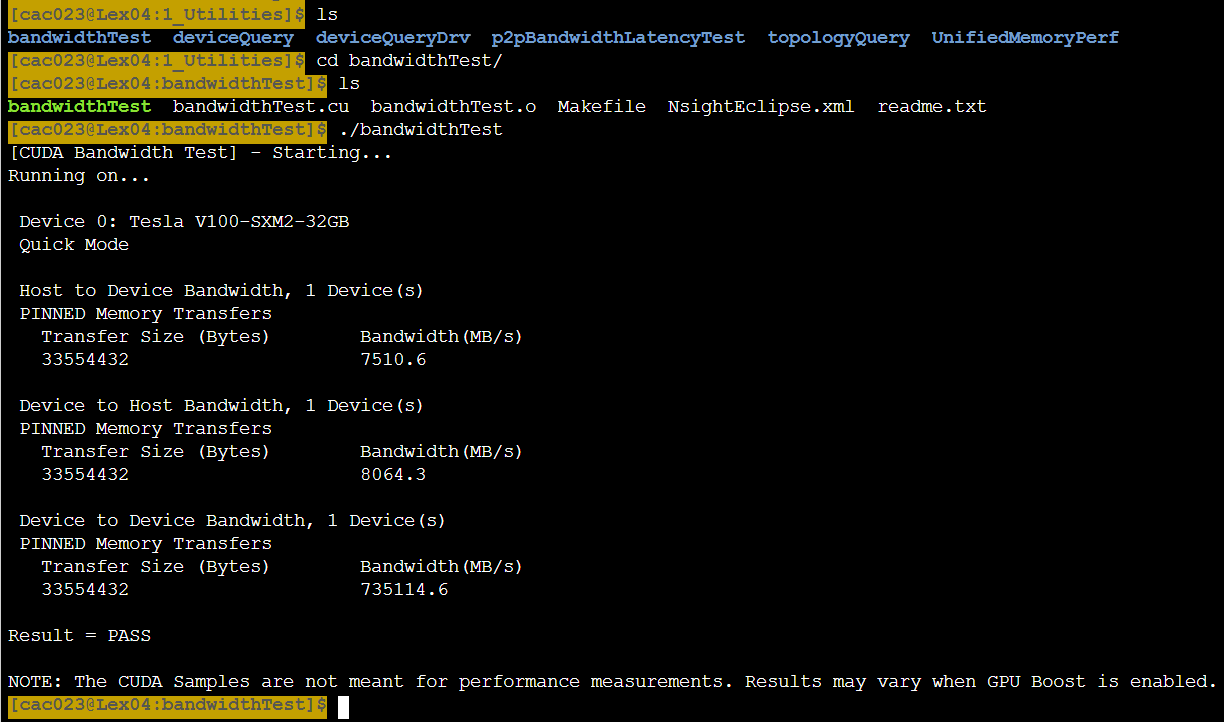
- host to device는 cpu->gpu를 의미한다.
- device to host는 gpu에서 cpu를 보낼때!! 약 12GB/sec이다.
- device to device gpu->gpu. 자기 메모리에서 자기메모리로 copy하는 것이고 3가지 경우중 가장 빠르다는 것을 확인할 수 있다.
3. Hello world!
-
GPU 프로그래밍을 할때 GPU가 해야하는 일은 전부 function내부에 define해야한다.
-
nvcc hello.c
를하면 컴파일이 된다. a.out파일 생성됨. -
nvcc는 nvidia에서 제공되는 컴파일러인데 시스템에 있는 컴파일러를쓰는데 gpu에 해당되는 부분만 따로 컴파일하고 link할때 object파일을 합쳐준다. 즉, 컴파일은 시스템에 깔려있는 컴파일러 쓰긴한다.
-
cc hello.c를 해도 nvc hello.c와 같은 결과를 받는다.
-
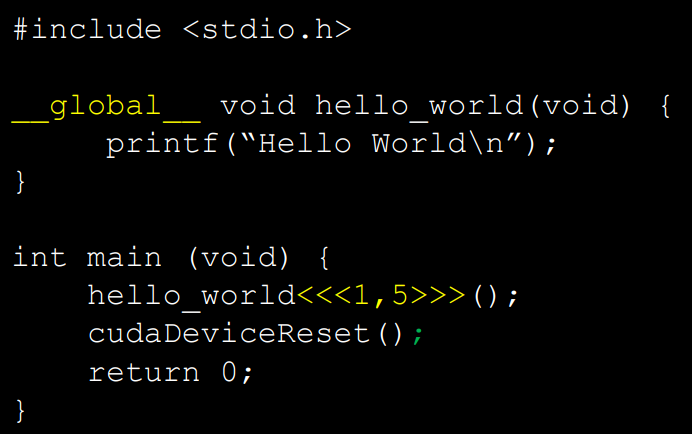
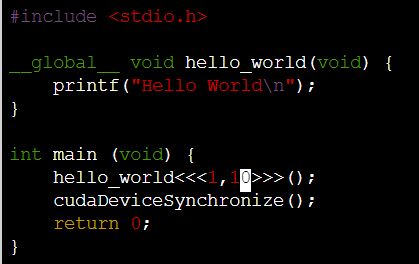
__global__ 은 이 함수가 gpu에서 돌아갈 것이라는 걸 알려준다.
-
<<<1,5>>> 는 execution configuration(GPU를 이용할때 필요. 후에 부가설명됨.)
-
<<<1, 10>>>으로 수정하면
-
hellow world가 10번 출력된다.
설명

- __device__와 __global__의 다른 점은 gpu에서 __device__를 호출할 수 있다는 점이다. __global__은 cpu에서만 호출되고 gpu에서 실행된다.
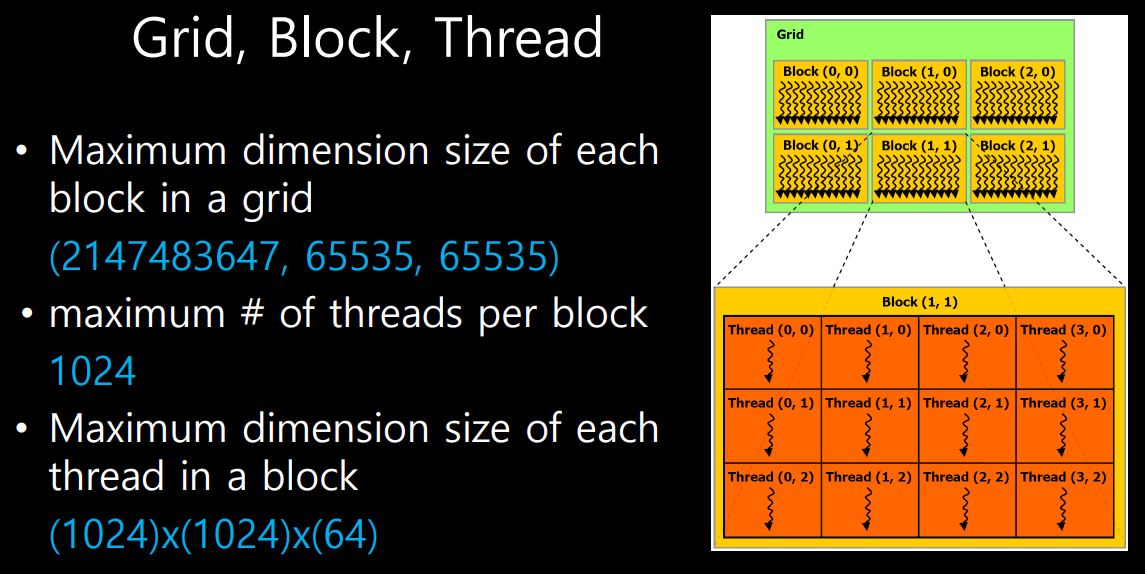
- gpu에서 일을 시킬 때, 어떻게 시킬 수 있냐 function이 kernel이라고 불리는데 grid가 열리고 그 안에 여러개의 block이 생김.
- block은 1,2,3 dim아무거나 가능.
- block안에 thread도 1,2,3 dim가능.
- multi dim.을 가지고 있으면 매칭(?)이 수월하게 된다고 함.
+제약조건은 한 grid당 maximum으로 만들수 있는 block수가 제한됨. 제한되는 숫자는 위의 이미지 참고
- c는 dim이 높아도 1dim으로 바꿔서 계산하기 때문에 제한이 있음.
- block 당 thread도 1024로 제한이 되기 때문에 하나가 2^10이면 다른 dim은 1로 define되야함.
- block내부에서만 shared memory를 사용할 수 있기때문에 제한이 반드시 필요하다!!!

- threadIdx.x 는 x방향으로 몇개가 있냐!!
- blockDim.x는 x방향으로 thread가 몇개있냐
- gridDim.x는 x방향으로의 block의 개수!!(grid내부에 block define이니까)
execution configuration
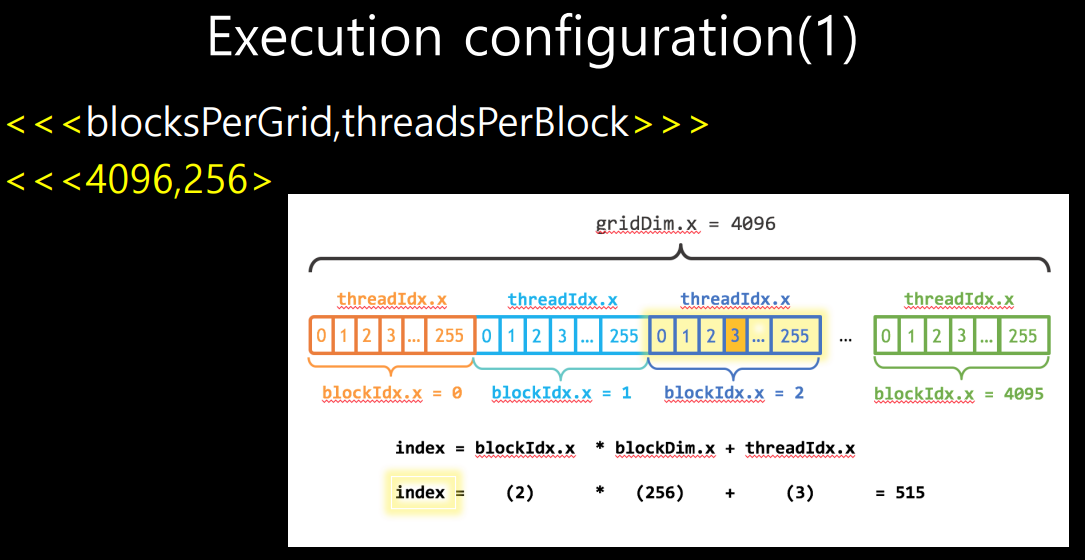
-
<<<grid당 block개수, block당 thread개수>>>
-
thread 총 개수는 두개 곱하면 됨.
-
index는 blockIdx와 blockDim, threadIdx를 조합해서 만들 수 있다.
-
여기서 blockDim은 한 block당 사이즈이고 여기서는 0~255까지 총 256
-
blockIdx는 2이니까 256*2에다가 threadIdx를 더하면 된다.
-
내가 필요로하는 array index가 이렇게 만들어진다.
-
MPI는 RANK등을 이용했는데 그와 유사하게 CUDA에서는 blockDim*blockIdx+threadIdx
- thread는 block당 1024개가 최대인데 thread를 최대로 쓰는게 좋은가 물으면? 문제에 따라서 다름. 왜냐하면 block당 배분된 하드웨어자원이 한정되어있고 그것을 thread들이 share하기 때문이다.
+따라서 프로그램에 따라 thread수를 조절해서 optimize해야할 필요는 있다.
예제
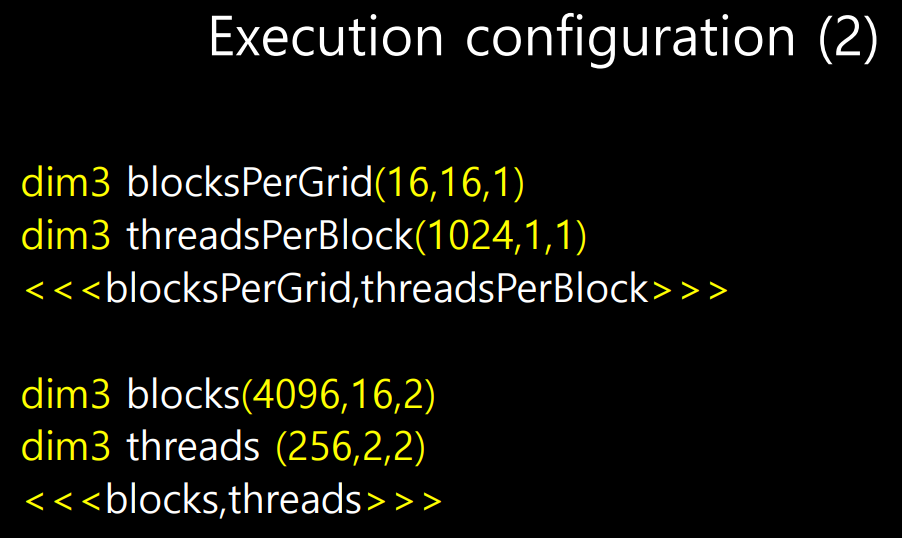

- 첫번째는 1d execution configuration, 2번째는 2d이다.
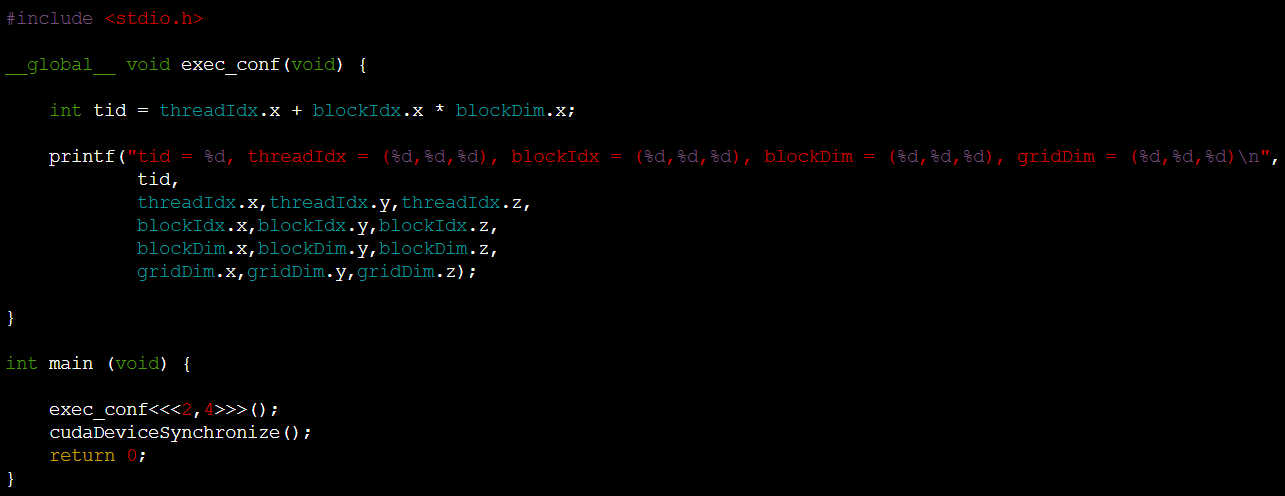
- <<<2,4>>>는 2개의 block과 4개의 thread를 만들라는 뜻이다.
- 따라서 총 2*4=8개의 thread가 생성된다.
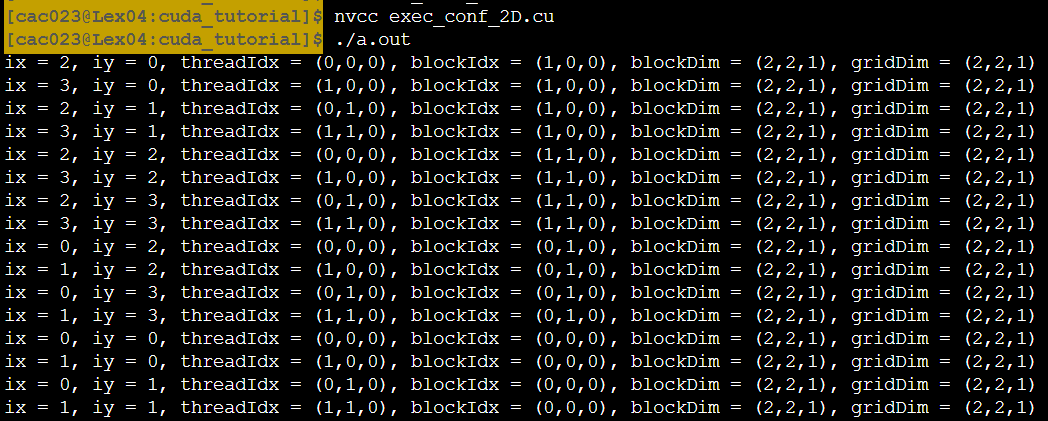
출력결과는 다음과 같다.
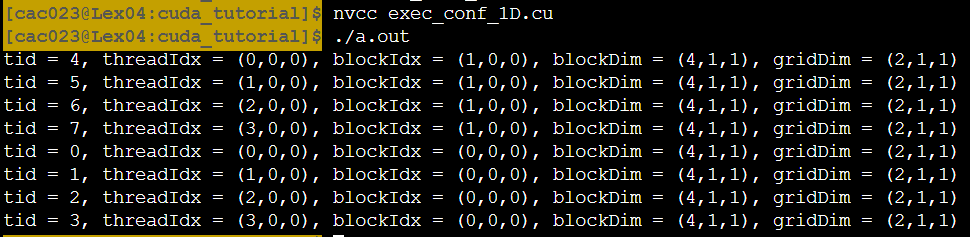
- blockDim은 block안에 thread가 몇개 있는가!(4,1,1)
- gridDim은 grid안에 block이 몇개 있는가를 나타낸다. (2,1,1)
2D인 경우를 살펴보면
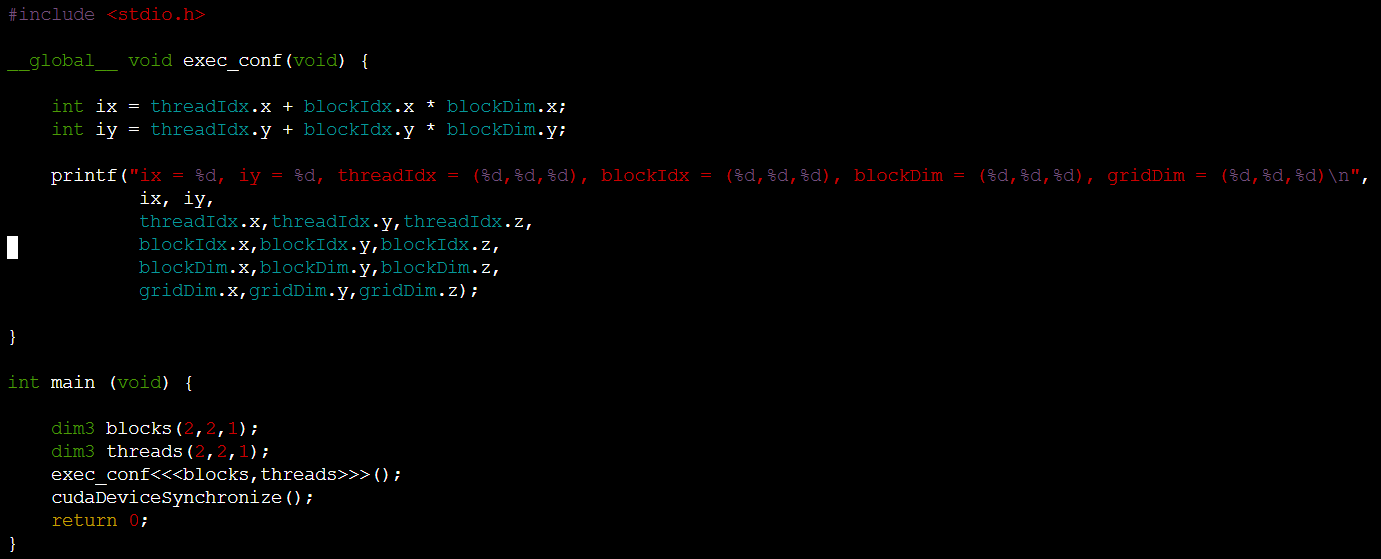
-
(2,2,1)은 2차원(x방향 2, y방향 2)
-
dim3 type을 사용해서 정의한다.
-
x방향 idx는 ix, y방향 idx는 iy로 정의.
-
block은 총 4개, thread도 block당 4개
-
총 16개의 idx가 만들어진다(즉, 총 16개의 thread)
GPU를 언제사용하는가
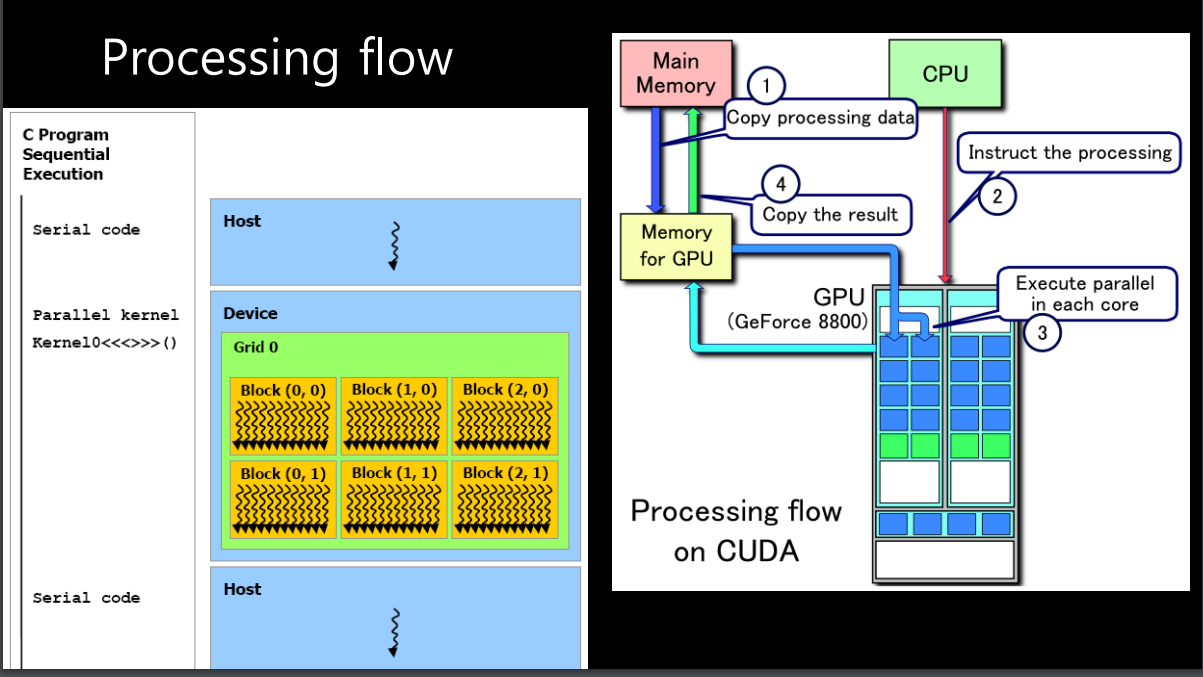
-
CPU에서 연산을 하다가 DEVICE를 호출하면 GPU로 연산을 하고 그 연산결과가 다시 CPU로 돌아온다.
-
따라서 GPU는 내 프로그램에서 계산이 많은 부분(ex. loop)에서 GPU를 사용한다.
-
CPU가 GPU부르기 전에 GPU에 필요한 메모리 copy해줌. GPU가 연산한 다음에 그걸 다시 CPU로 보내줌.
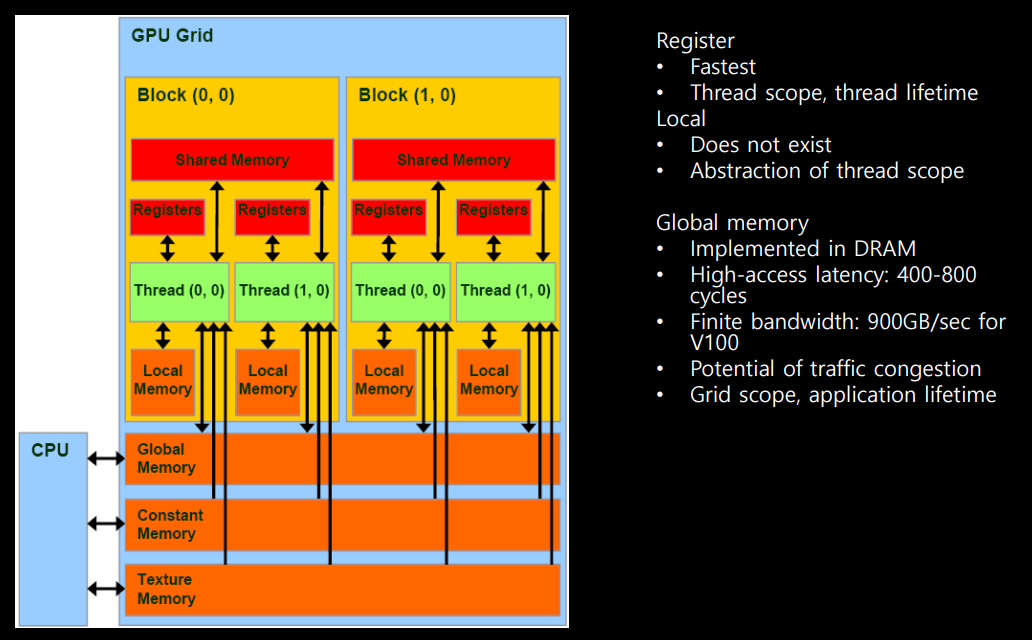
-
gpu function을 call하면 grid가 열리고 block내부에서 shared memory를 사용할 수 있고 register 존재. thread가 shared memory와 register를 사용한다.
-
우리는 global memory를 제일 많이 사용한다. cpu에서 gpu로 data를 보낼때 대부분 global memory를 사용. gpu가 global memory를 읽어서 연산수행.
-
constant memory를 어떤 특정값을 여러 thread가 access할때 생기는 문제를 해결하기위해 broadcast할 수 있는 memory를 말한다.
-
texture memory는 메모리의 locality를 이용해서 빠르게 연산할 수 ㅣ있게 도와주는 역할을 한다.
-
local memory는 abstract한 개념이다. 실존하는 메모리는 아님.
-
global memory에서 data읽어오려면 400-800 cycle이라는 latency가 있는 반면, shared memory는 1/20정도로 빠르다!! 그래서 자주 사용하는 값은 shared memory에 저장해놓고 읽어와야한다.
gpu memory allocation하는 방법

- cpu와 gpu는 memory는 별개임.
- cudaMallocManaged는 unified memory를 위한 명령어다.
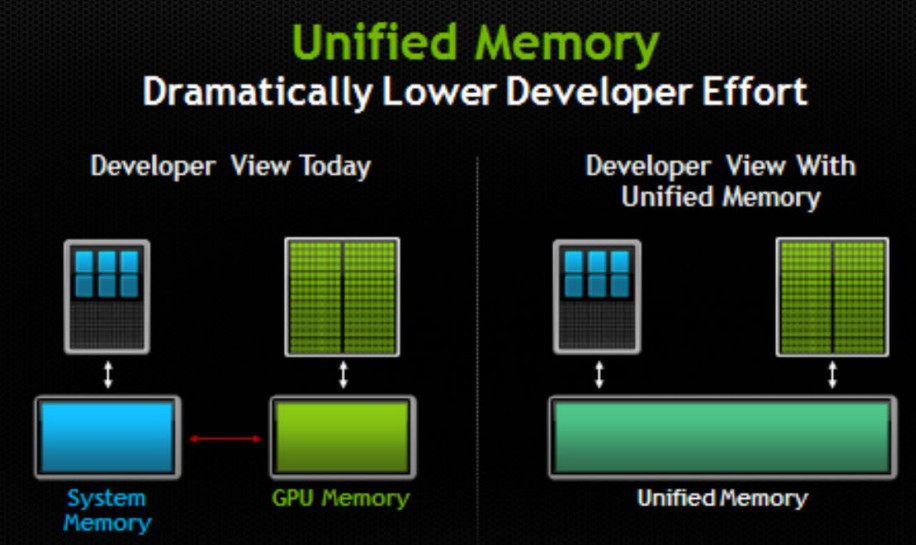
- gpu에 계산 시키려면 cpu에서 gpu로 데이터를 보내야함
- 그런데 unified memory라는 것이 있음. cpu와 gpu메모리가 합쳐져 있어서 cpu와 gpu가 같이 사용할 수 있다.
- unified memory를 사용하면 사용자가 직접 메모리 조작으로 데이터를 안보내도 되서 좋다.
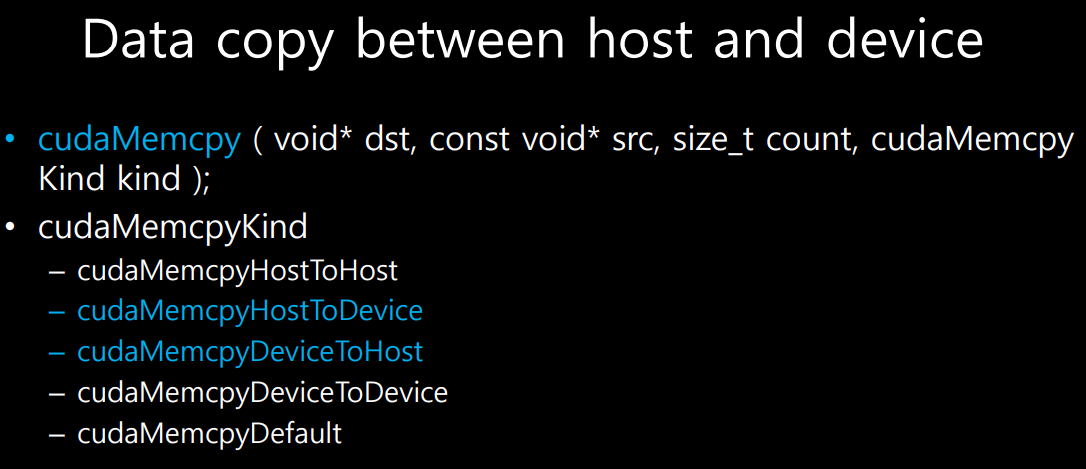
- cpu->gpu이면 src는 cpu데이터, dst는 gpu데이터
예제

+아래는 a+b계산해서 c를 만드는 프로그램이다. 이것을 cuda로 바꾸자
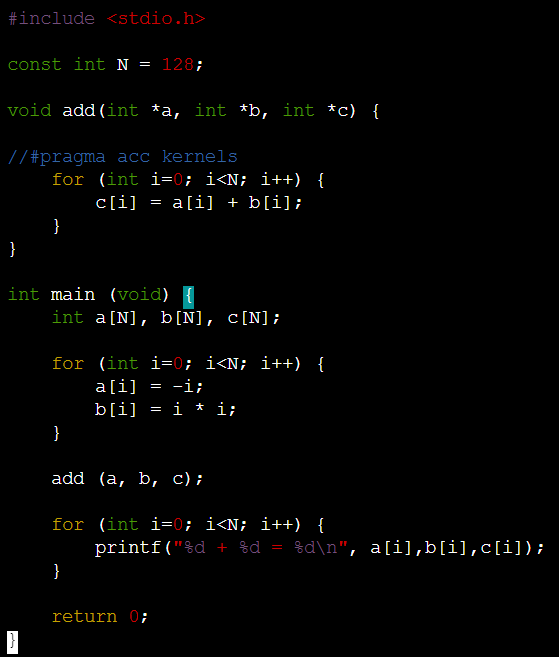
block단위
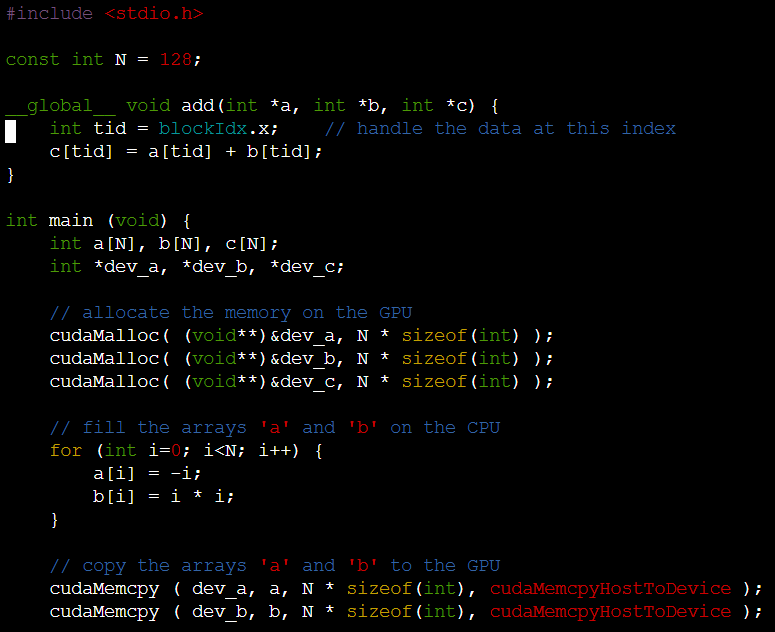
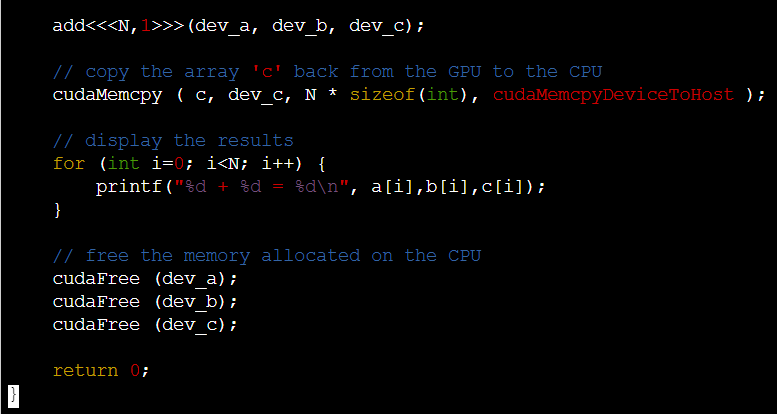
-
gpu function을 보면 loop가 없다는 것을 확인할 수 있다. tid라는 thread index를 통해 계산.
-
memcpy에서 host to Device인지 device to host인지 방향 표기가 된다.
-
마지막으로 사용한 memory free해야함.
-
<<<N,1>>>과 <<<1,N>>> 차이는 N개의 block내부에 1개의 thread, 1개의 block내부에 N개의 thread
thread & block의 결합
thread는 block안에 최대 1024개의 thread가 가능하다
그렇다면 1024*256 size의 matrix는 어떻게 연산할까?
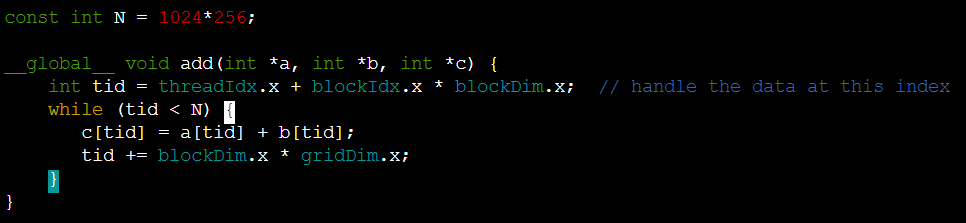
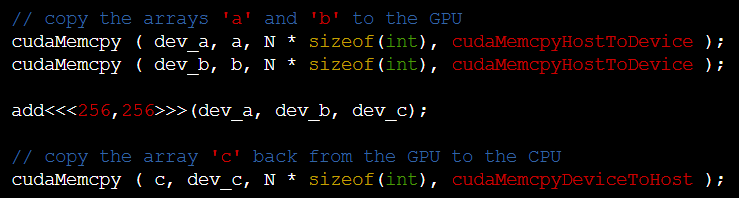
- 여기서 <<<256, 256>>> 으로 block*thread가 있음.
그런데 matrix는 1024*256이라서 *4만큼 모자란다. - 따라서 gpu function에서 tid<N일때 while loop를 돌면서 tid를 blockDim.x*gridDim.x만큼 더해주면 총 4번씩 while loop를 돌면 gpu 연산을 종료할 수 있다.
- 256*256씩 tid가 점프하기 때문이다!!!
