
분산 락이 필요한 이유
여러 프로세스가 동일한 자원에 접근할 때 동시성 이슈가 발생하기 때문입니다.
동시성 이슈
여러 프로세스가 공유하는 동일 자원을 동시에 접근하면서 경쟁 상황이 생기는 것을 동시성 이슈라고 합니다.
- 동일 자원
프로세스들이 접근하는 변수 혹은 메모리들 (자원)
=> 공동으로 이용되기 때문에 누가 언제 데이터를 읽고 쓰는가에 따라 그 결과값이 달라질 수 있습니다.
- 경쟁 상황 (race condition)
2개 이상의 프로세스가 동시에 같은 자원에 접근하여 read, write하는 상황
- 예시
동시성 이슈에 관련된 예시를 하나 들어보면,
서울에 사는 A와 청주에 사는 B가 동시에 하나의 통장에서 돈을 인출하려고 합니다.
계좌 잔액이라는 동일 자원이 있고 하나의 인출 행위에 대해서 갱신이 되기 전에 인출이 진행되면 잔액이 없어도 인출이 진행될 수 있게 됩니다.
이런 경우를 위해서 임계 구역에 락을 걸어 원자성을 보장해주어야 합니다.
- 임계 구역
둘 이상의 스레드가 접근해서는 안되는 공유 자원을 접근하는 코드의 일부를 말합니다. 임계 구역은 지정된 시간이 지난 후 종료되며 때문에 어떤 스레드(태스크 또는 프로세스)가 임계 구역에 들어가고자 한다면 지정된 시간만큼 대기해야 합니다.
분산 락
분산 락이란 경쟁 상황이 발생할때 혹은 하나의 공유자원에 접근할때 데이터에 결함이 발생하지 않도록 원자성을 보장하는 기법 입니다.
분산 락을 구현하기 위해서는 락에 대한 정보를 ‘어딘가’에 공통적으로 보관하고 있어야하며 분산 환경에서 여러 대의 서버들은 공통된 ‘어딘가’를 바라보며, 자신이 임계 영역에 접근할 수 있는지 확인해야 합니다.
여러 서버들이 임계 구역을 접근을 관리하는 공통의 작업자를 보면서 임계 구역에 접근할 수 있도록 락킹을 하기 위해 분산 락이 존재하게 됩니다.
redlock
redis에서 분산 락을 구현하기 위해 redlock 알고리즘을 제안하고 있습니다.
레디스로 분산락을 구현하게 되면
락의 대한 정보를 저장하는 공간 '어딘가'가 redis가 되는 것이고 여러 대의 서버는 redis를 바라보면서 임계 구역에 접근할 수 있는지를 확인하게 됩니다.
특히 레디스에서는 3가지 특성을 지켜야된다고 말해주고 있습니다.
- 상호배제: 오직 한 순간에 하나의 작업자만이 락을 획득할 수 있다.
- 데드락 방지: 락 이후 어떠한 문제로 인해 락을 풀지 못하고 종료된 경우라도 다른 작업자가 락을 획득할 수 있어야 한다.
- 내결함성: Redis 노드가 작동하는 한 모든 작업자는 락을 걸고 해제할 수 있어야 한다.
SET lock_name random_value NX PX 30000NX: 키가 존재하지 않을 때만 SET이 가능
PX: millsecond로 유효 시간 조정
위 명령어는 락이 존재하지 않는다면 키를 세팅하고 30000ms의 타임아웃 시간을 가지게 됩니다. 값은 random_value로 세팅되며 이 값은 모든 클라이언트와 모든 잠금 요청에서부터 유니크한 값이어야 합니다.
const randomValue = "요청 값";
const lock = redis.get("lock_name");
if (!lock) {
redis.set("lock_name", randomValue, 'NX', 30000);
} else {
if (lock[1] === randomValue) {
redis.del("lock_name");
} else {
return 0;
};
};클라이언트는 락을 획득할 수 있고, 락 유효시간보다 긴 시간(락이 해제되는 시간)동안 일부 작업을 수행하는것이 차단됩니다.
추가로 락 유효기간은 필요한 작업의 수행 시간보다 길게 설정하는 것이 중요하게 됩니다.
위에서 말했던 3가지 특성을 지켰는지 확인해보면 클라이언트마다의 요청 값으로 value를 비교해 락을 해제하기 때문에 상호배제 특성을 지키고 락의 유효기간으로 데드락 방지까지 완료하게 되고 또한 클라이언트들은 락을 획득하고 해제하는 법을 알고 있기때문에 모든 클라이언트가 락을 획득하고 해제할 수 있습니다.
단일 인스턴스라서 get과 set 두 연산이 원자성을 띄지 않아도 가능하지만 여러 인스턴스가 있을 경우에는 "락이 존재한다"와 "락이 존재하지 않는지 확인한다"가 아토믹하게 이루어져야합니다.
그럼 여러 인스턴스일 경우에는 어떻게 이루어질까요?
레디스 공홈에서는 이렇게 설명하고 있습니다.(https://redis.io/docs/manual/patterns/distributed-locks/)
-
현재의 시간을 구합니다 (단위: ms).
-
같은 키와 랜덤한 값을 통해 모든 인스턴스를 순차적으로 방문합니다. 2단계에서 모든 인스턴스에 락을 설정할 때 클라이언트는 총 락 타임아웃보다 살짝 작은 타임아웃 시간을 사용합니다. 예를 들어 타임아웃이 10초라면 시간 초과 범위는 5-50ms 정도로 설정합니다. 이것을 통해 다운된 인스턴스 때문에 발생할 수 있는 지연시간을 줄일 수 있습니다. (만약 다운된 인스턴스가 있으면 최대한 빠르게 다음으로 넘어가야 되기 때문)
-
클라이언트는 락을 획득하기 위해 (현재 시간 - 1단계에서 구했던 현재 시간)을 계산하여 경과한 시간을 구합니다. 클라이언트가 대부분의 인스턴스(본 예제는 5개의 인스턴스를 사용하기 때문에 3개의 인스턴스)에서 락을 획득할 수 있고, 락을 획득하는데 경과된 총 시간이 락 유효시간보다 짧은 경우 락을 획득한 것으로 간주하게 됩니다.
락 획득 조건: 락 유효시간 < 여러 인스턴스에서 lock 획득하는데 걸린 총 시간 -
락을 획득했다면 유효 시간은 3단계에서 계산된 초기 유효 시간에서 경과된 시간을 뺀 것으로 간주합니다.
-
만약 클라이언트가 락을 획득하는데 실패했다면(예를 들어, 인스턴스 개수/2+1 개의 인스턴스를 잠글 수 없거나 유효 시간이 음수라면) 인스턴스에 락이 걸려있지 않은 상황에서도 락이 있다고 생각하고 모든 인스턴스를 대상으로 락 해제를 시도하게 됩니다.
길게 썻지만
결론만 말하자면 잠금 유효기간과 타임아웃 시간을 정해둔 후 과반수의 인스턴스 잠금을 획득하면 잠금을 얻은 것으로 간주하는 알고리즘입니다.
동시성 이슈 재현
동시성 이슈가 발생하는 상황을 만들어 처리해보겠습니다.
여러 클라이언트가 커피를 주문하고 주문 count를 +1씩 해주는 코드를 간단하게 구현해보았습니다.
환경
- 서버: 인스턴스 2대
- 인스턴스 2대 둘 다 같은 redis, mysql 연결
order.entity.ts
@Entity('order')
export class Order {
@PrimaryGeneratedColumn({})
id: string;
@Column({
length: 36,
comment: '주문할 상품',
})
productName: string;
@Column({
comment: '주문할 수 있는 최대 개수',
})
countLimit: number;
@Column({
comment: '주문한 개수',
})
count: number;
}orders.service.ts
@Injectable()
export class OrdersService {
constructor(
@Inject(ORDERS_REPOSITORY)
private readonly ordersRepository: OrdersRepository,
) {}
async includedCountById(id: string) {
const order = await this.ordersRepository.getById(id);
if (order.count + 1 > order.countLimit) {
throw new Error();
}
return await this.ordersRepository.updateById(id, {
count: order.count + 1,
});
}
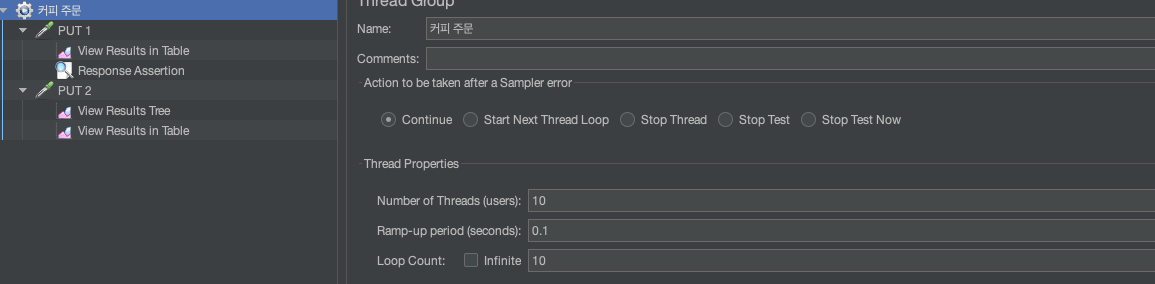
}Jmeter를 이용해 포트가 다른 두 서버를 띄워 확인해보았습니다.
- Number of Threads : 쓰레드 개수
- Ramp-up period : 쓰레드 개수를 만드는데 소요되는 시간
- Loop Count : infinite | n 으로 값을 설정할 수 있으며 설정된 값에 따라 Number of Threads X Ramp-up period 만큼 요청을 다시 보내게 됩니다.
총 10명의 유저가 0.1초만에 10번 반복해서 요청을 보내는 것으로 설정했습니다.
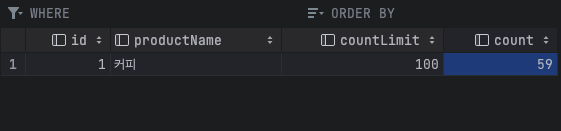
결과는 동시성 이슈가 발생했습니다.
동시성 이슈 제어를 위해 저는 npm에서 가장 많이 사용하는 redlock을 사용해 보았습니다.
async includedCountById(id: string) {
const redis = new Client({
host: 'host1',
});
const redis2 = new Client({
host: 'host2',
});
const redis3 = new Client({
host: 'host3',
});
const redlock = new Redlock([redis, redis2, redis3], {
retryCount: 10, // 에러 전까지 재시도 최대 횟수
retryDelay: 200, // 각 시도간의 간격
retryJitter: 200, // 재시도 시 더해지는 최대 시간
automaticExtensionThreshold: 500, // 잠금 연장 전 남아야되는 최소 시간
});
const lock = await redlock.acquire(['server'], 5000); // lock의 키 값과 유효 시간
try {
const order = await this.ordersRepository.getById(id);
if (order.count + 1 > order.countLimit) {
throw new Error();
}
return await this.ordersRepository.updateById(id, {
count: order.count + 1,
});
} catch (err) {
throw err;
} finally {
if (lock) {
await lock.release();
}
}
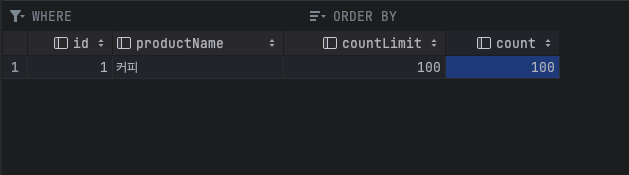
}그리고 처리한 것을 보면 count가 알맞게 들어온 것을 알 수 있습니다.
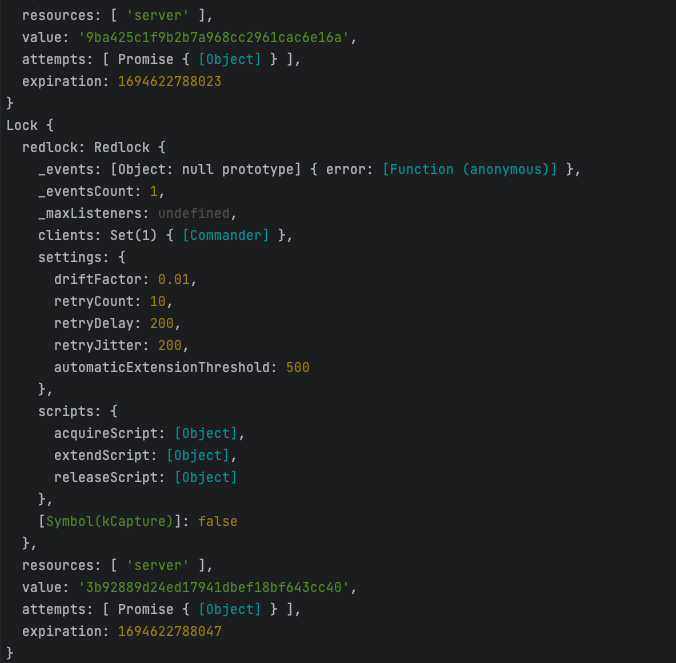
추가로 lock을 획득했을 때를 보면 value가 계속 달라지는 것을 볼 수 있고 시도와 유효 시간이 어떻게 되는지 나와있는 것을 볼 수 있습니다.
참고 문서
https://redis.io/docs/manual/patterns/distributed-locks
번역 정리 블로그
동시성 이슈
redlock npm
Jmeter 사용법
노드 예시
