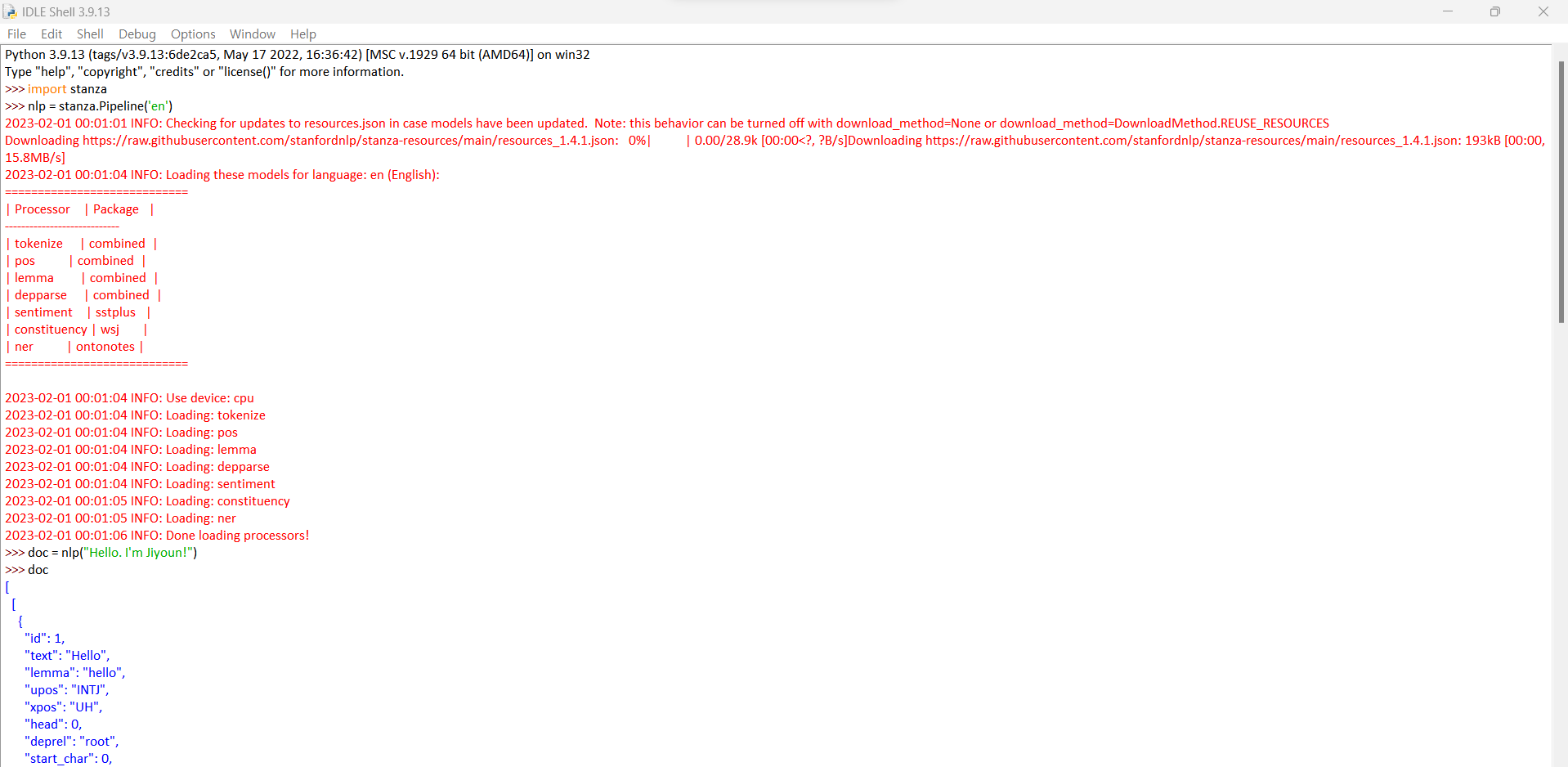
0. STANZA?
Stanza는 스탠포드(stanford) NLP 그룹에서 만든 자연어처리(NLP, Natural Language Processing) 라이브러리로 영어, 한국어를 비롯한 66개의 다국어의 분석을 가능하게 하는 툴입니다. 단어를 분리하는 tokenizer뿐만 아니라, 원형을 복원하는 lemmatization, 품사(POS, Part Of Speech) 태깅, 의존 구문 분석(dependency parsing), 개체명 인식(NER, Named Entity Recognition) 등의 기능을 제공합니다.
이 포스팅 시리즈에서는 설치부터 시작하여 각 모듈 별 사용 방법 등에 대하여 기록해두고자 합니다. Windows 기준으로 설치를 진행합니다.
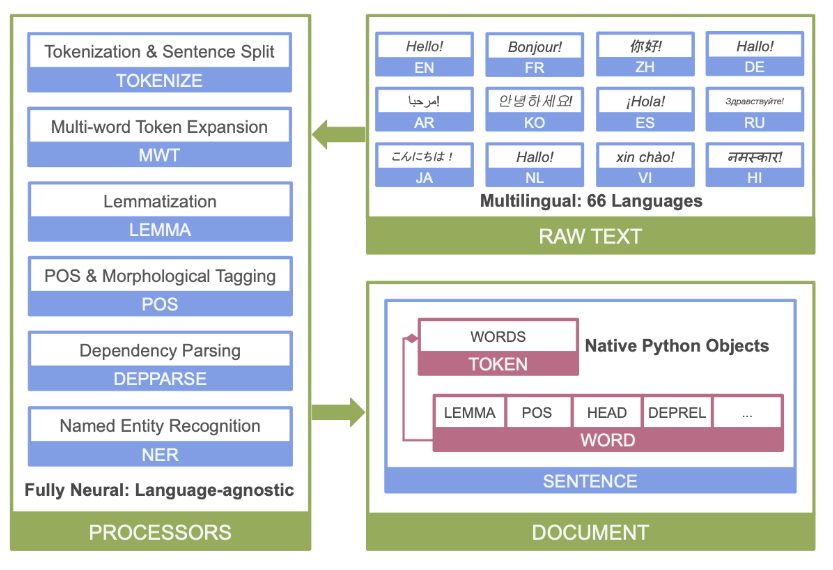
1. 설치하기
1-1. pip install stanza
아래와 같은 명령어를 cmd 창에 입력하여 stanza의 설치를 시작합니다.
pip install stanza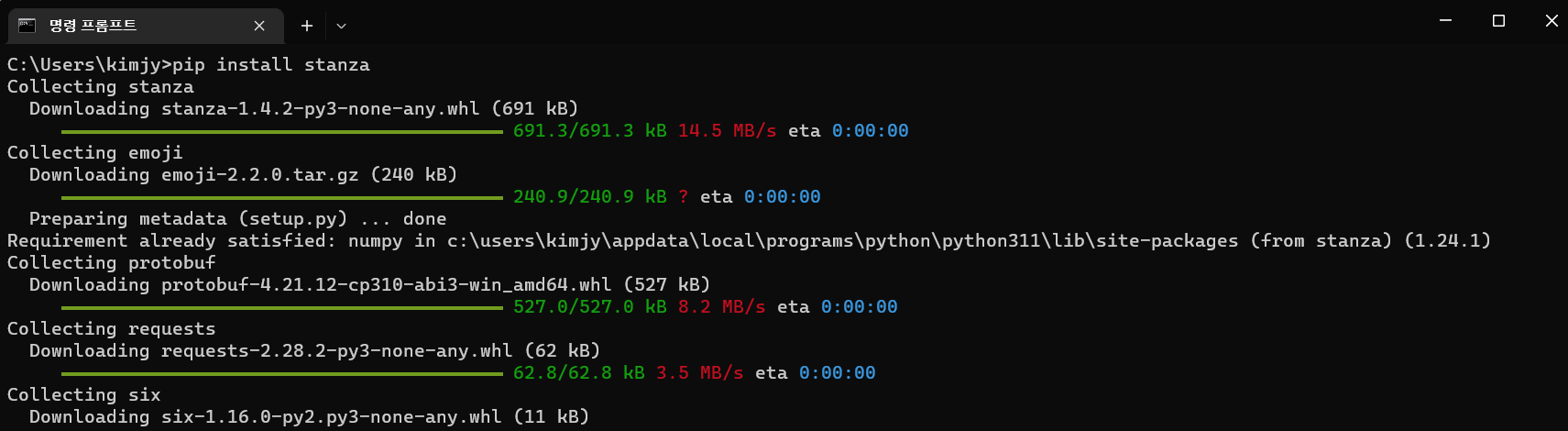
1-2. import 하여 패키지 설치 확인해보기
python Shell에서 설치된 패키지를 불러오는 아래의 명령어를 실행해봅니다.
import stanza
여기까지만 실행해보았을 때는 문제없이 패키지가 설치된 것 같지만...
1-3. 언어별 모델 다운로드
stanza는 각 언어별로 다국어 모델을 다운로드 받아야 합니다. 다운로드를 위해서는 아래와 같은 스크립트 라인을 작성해주면 됩니다. 로컬에서 이용하는 경우에는 다운로드는 1회만 실행하면 됩니다. 괄호 안에는 다운로드 받고자 하는 언어의 코드를 입력하면 됩니다. 저는 일단 영어('en') 모델을 다운로드 받아보겠습니다. 참고로 한국어 모델의 경우에는 'ko'을 괄호안에 넣으면 됩니다.
stanza.download('en')1-4. 소소한 팁
왜인지는 모르겠지만, idle에서 모델을 다운로드 받으려고 하니 이렇게 오류(?)처럼 보이면서 다운로드 시간이 굉장히 오래 걸리는 현상이 발생했습니다.
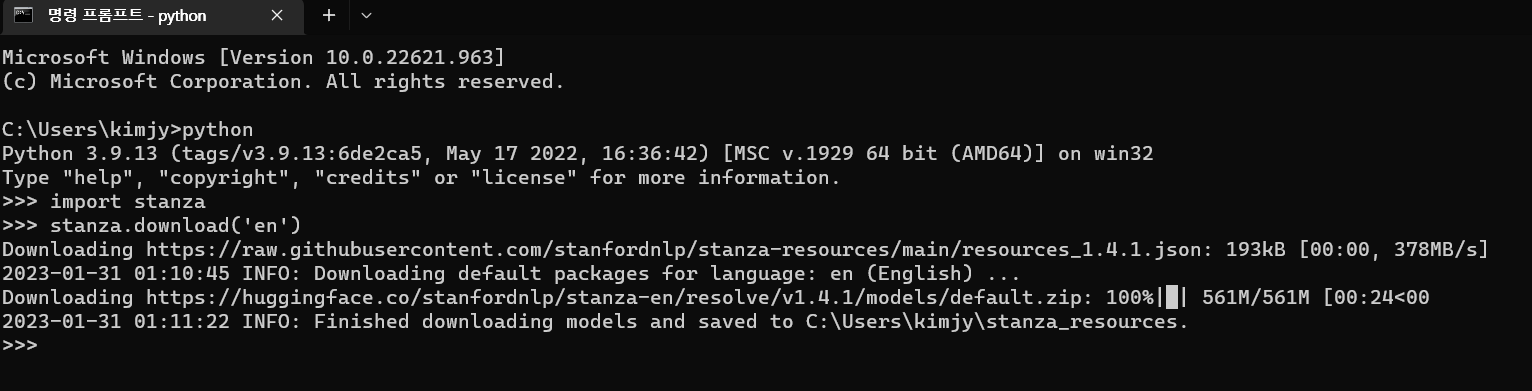
혹시나 해서 cmd창에서 파이썬을 켜고 모델을 다운로드 받으니 훨씬 빠르게 다운로드가 진행됩니다!
2. 오류 해결하기
저는 처음 설치하는 과정에서 이런 오류가 발생했습니다.
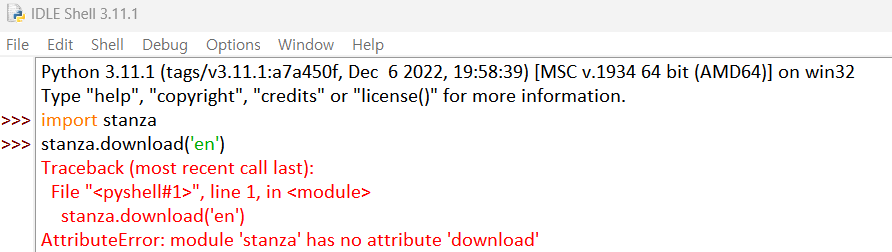
2-1. AttributeError: module 'stanza' has no attribute 'download' 검색을 해보니..
FAQ에 이미 동일한 오류에 대한 설명이 나와있습니다. Python 3.x 버전이 아닌 Python 2.x 버전을 사용하는 사람들에게 보통 발생하는 오류라고 합니다. 그치만 저는 3.11 버전을 사용하고 있는데...

2-2. Stanza에서 지원하는 파이썬 버전을 보니.. python 3.11 버전에서는 실행되지 않는 것이 어쩌면 당연했네요 ^_ㅜ

2-3. 파이썬 3.6, 3.7, 3.8, 3.9 버전 중 하나로 다운그레이드를 합니다. 방법은 여기를 참고해주세요.
3-3. 다시 1-1로 돌아가 설치하기를 진행합니다.
3-4. 설치가 완료되어 모델을 로딩하고, 로딩된 모델을 이용해서 영어 문장을 잘 분석하는 것을 확인할 수 있었습니다!