-
🥇 지호의 옵티마이저 요약본
-
✔ 옵티마이저란?
손실 함수 (Loss Function)의 결과를 최소로 해주는 모델의 파라미터 (가중치)를 찾는 알고리즘을 의미
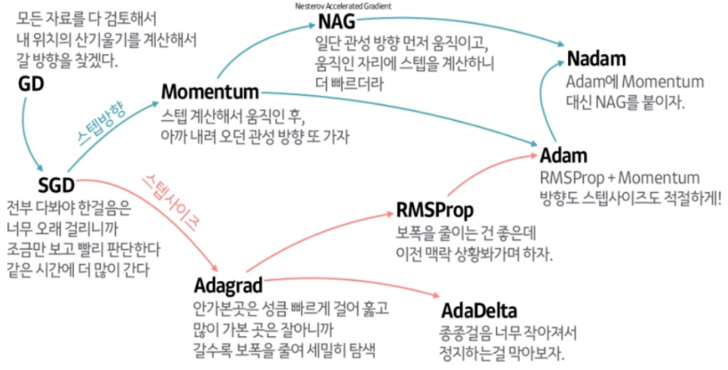
옵티마이저의 시작
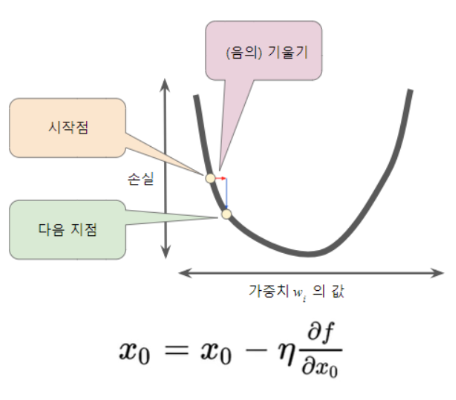
Gradient Descent
- Loss Function 의 값이 작아지는 방향으로 가중치를 업데이트 하며 Loss Function을 최소화하는 가중치를 찾아가는 방법
-
문제점
-
가중치를 업데이트 하기 위해선, 전체 데이터 셋을 이용하여 수십번의 가중치를 업데이트 해야한다.
예를 들어, 1000개의 데이터 셋이 존재하고, 뉴런들의 가중치가 200개가 존재한다. 모든 가중치를 "한 번" 변화시키기 위해서 1000 * 200 번의 계산이 필요하다.
너무 많은 메모리와 시간 사용 -
안정적으로 움직이는건 좋음. 그러나, 안정적으로 움직이기 때문에, Local Optima 문제가 발생할 가능성이 높음
-
-
해결방안 : Mini Batch 를 이용하여 일부를 샘플링하여 학습한다면?
-
SGD (Stochastic Gradient Descent)
-
구글링에서 나오는 미니 배치 경사 하강법 == SGD
-
일반적으로, 10 ~ 1000개의 데이터로 구성
-
각 배치를 포함하는 데이터가 무작위로 선택됨
-
예를 들어, 데이터가 1000개, batch size 를 100 10개의 mini batch가 나옴. 1 epoch 당 10번의 SGD 진행

-
SGD 장점
-
Gradient Descent에 비해 수렴 속도고 빠르다.
-
Shooting 이 일어나기 때문에, Local Optima에 빠질 위험이 적다.
-
-
SGD 단점
- Gradient Descent 와 마찬가지로 Global Minimum을 찾지 못 할 가능성이 있다.
- Shooting 이 심하게 일어나면, 최적해를 찾지 못할 가능성이 있다.
-
해결방안 : SGD 에서 Shooting 을 줄일 수 있다면?
-
-
Momentum
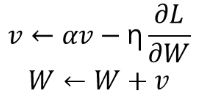
: 가속도 , : momentum term (보통, 0.9)
-
== SGD +
-
SGD가 중구난방으로 최적해를 찾아가는 것에 대하여 그 진동을 줄이고, 최적해에 연관된 방향으로 더 가속을 해주는 방법
-
가중치를 수정하기 전에, 기울기를 참고하여 더 그 방향으로 가려는 성질을 추가해줌.
-
이를 통해, Shooting (지그재그) 현상이 줄어들고, Gradient의 방향이 변경되어도, 이전 방향과 크기에 영향을 받아 다른 방향으로 가중치가 변경될 수 있음.
-
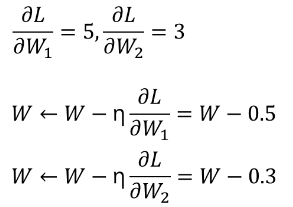
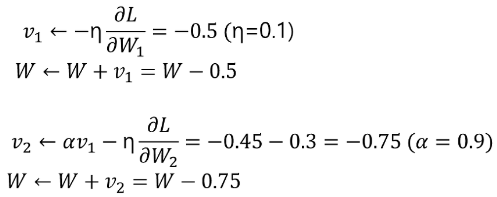 ( : 초기의 가속도는 존재하지 않으므로 = 0 )
( : 초기의 가속도는 존재하지 않으므로 = 0 )

-
momentum 장점
-
Local Minima의 문제를 피할 수 있음.
-
더 빨리 최적해를 찾을 수 있음.
-
-
momentum 단점
-
Overshooting : 경사가 가파른 곳을 빠른 속도로 내려오다가, 관성을 이기지 못하고 최소 지점을 지나쳐 버리는 현상
-
이를 개선한 알고리즘 :
-
-
Nesterov momentum
- 현재의 속도 벡터와 현재 속도로 한 걸음 미리 가 본 위치의 Gradient Vector를 더하여 다음 위치를 정함
-
AdaGrad
-
Adaptive Gradient 의 줄임말
-
기존 Optimizer의 경우, learning rate 값에 따라서 학습이 잘 될 수도 잘 안 될 수도 있는 문제가 존재함
개별 매개 변수에 적응적으로 (adaptive) learning rate를 조정하면서 학습을 진행
-
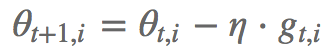 을 하면서, learning rate을 조절해가면서 다음 parameter 업데이트 값을 결정짓게 한다. 그래서 학습을 진행하면서 이미 학습이 많이 된 변수라면 최적점에 이미 가까이 갔을 것이라 판단, 학습이 아직 덜 된 드물게 등장한 변수라면 학습을 더 빨리 하게 함으로써 최적점으로 이끈다. 이렇게 되면 랜덤으로 들어오는 변수들에 대해서 효율적으로 학습을 시켜서 빨리 최적점을 찾도록 할 수 있게 된다
을 하면서, learning rate을 조절해가면서 다음 parameter 업데이트 값을 결정짓게 한다. 그래서 학습을 진행하면서 이미 학습이 많이 된 변수라면 최적점에 이미 가까이 갔을 것이라 판단, 학습이 아직 덜 된 드물게 등장한 변수라면 학습을 더 빨리 하게 함으로써 최적점으로 이끈다. 이렇게 되면 랜덤으로 들어오는 변수들에 대해서 효율적으로 학습을 시켜서 빨리 최적점을 찾도록 할 수 있게 된다
 : 과거 시점에서의 Gradient 제곱합
: 과거 시점에서의 Gradient 제곱합
: 1e-8 (Zero DivisionError 피하기 위함)
: 현재의 기울기
AdaGrad 는 과거 gradient 양을 토대로 학습을 진행하며, learning rate 를 조절해가면서 다음 가중치의 업데이트 값을 결정하게 된다.
따라서, 이미 학습이 많이 된 변수라면, 즉, 누적된 과거의 Gradient 양이 많다면, learning rate 값을 작아지도록 조절하여 최적해로 가도록 도와준다.
그러나, 가 계속 누적된다면 값이 커질수 밖에 없다. 그렇다면, 어느 순간 갱신량이 0이 되어 전혀 갱신이 되지 않고 결국 더 이상 학습을 진행할 수 없게 된다.
이를 해결하고자 RMSprop 가 개발되었다.
-
RMSprop
-
먼 과거의 기울기는 조금 반영하고, 최신의 기울기를 많이 반영하는 AdaGrad ( 지수이동평균을 이용한 AdaGrad)
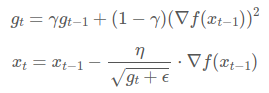 : 지수이동평균의 업데이트 계수 (일반적으로, 0.9 혹은 0.999)
: 지수이동평균의 업데이트 계수 (일반적으로, 0.9 혹은 0.999) -
지수이동평균 : 과거의 모든 기간을 대상으로 하여 최근의 데이터에 더 높은 가중치를 두는 일종의 가중이동평균법
-
RMSProp 장점
-
가 무한정 커지는 것을 방지하여, AdaGrad 보다 학습을 오래 할 수 있음
-
적절한 학습률을 조정하며 효율적인 학습 가능
-
-
-
Adam
- RMSProp +

단, Adam 에서는 과 가 처음에 0으로 초기화 되어있다. 즉, 학습 초반에는 와 가 0에 가깝게 bias (편향) 되어 있을 것이다.
따라서, 이를 unbiased (편항되어 있지 않은) 하게 만들어주는 과정을 거친다.
편향 : 추정량과 모수의 차이
추정량의 기댓값이 모수와 같아지는 것이 가장 바람직한 경우임.
unbiased estimator 의 조건 : E() =

- 참고 사항 ( unbiased estimator )
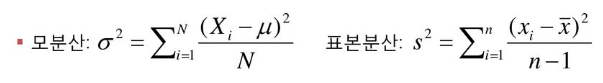
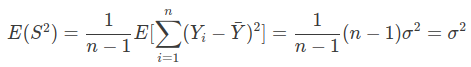
- 요약