
코호트 분석
- 코호트 : 소비자를 시간의 흐름과 사용하는 서비스의 단계 등으로 나누어 같은 성질의 집단으로 구분한 것
- 코호트 분석 : 동일한 기간동안 동일한 특성을 가진 사람들을 모아 분석하는 일종의 행동 분석 방법
- 코호트 차트 : 소비자의 전환율을 시간의 흐름 / 서비스 단계나 재사용 등 두가지 요인을 복합적으로 보여줄 수 있는 차트
1. 스파르타코딩클럽 현황
1) 8월 2주 차 개강반부터 새로 제작된 3주차 콘텐츠를 듣기 시작하였음
2. 가설 수립
8월 둘째 주 부터 변경된 3주 차 강의의 완주율이 현저히 떨어졌을 것이다
3. 데이터 확인 및 전처리
cohort = pd.read_csv("cohort_data.csv")
cohort.head()
- user_id : 수강생 고유 id
- created_at : 수강 등록 시점
- name : 수강생 이름
- progress_rate : 진도율
cohort.info()
- 날짜가 object형태로 되어 있어 날짜 형태인 Datetime 형태로 변환 필요
cohort['created_at'] = pd.to_datetime(cohort['created_at'])
cohort.info()
- 변경된 강의가 영향을 주었는지 확인하기 위해 변경 직전인 2주차와 변경 완료인 3주차 데이터의 완주율 비교
- 수강 시작 주 구하고 테이블의 열로 추가
.dt.isocalendar().week : 날짜를 주(week)로 변경
cohort['start_week']= cohort['created_at'].dt.isocalendar().week
cohort.tail()
- 진도율을 강의 주차로 변경
0주차 : 0 ~4 .11%
1주차 : 4.12% ~ 26.03%
2주차 : 26.04% ~ 41.10%
3주차 : 41.11% ~ 61.64%
4주차 : 61.65% ~ 80.82%
5주차 : 80.83% ~ 100%
progress_rate = list(cohort['progress_rate'])
bins = [0,4.11,26.03,41.10,61.64,80.82,100]
labels=[0,1,2,3,4,5]pd.cut : 범주화에 사용되는 함수
cuts = pd.cut(progress_rate,bins, right=True,include_lowest=True, labels=labels)
cuts
cohort['week'] = cuts
cohort.head()
group = cohort.groupby(['start_week','week'])
cohort_data = group['user_id'].apply(pd.Series.nunique)
cohort_data = pd.DataFrame(cohort_data)
cohort_data.head()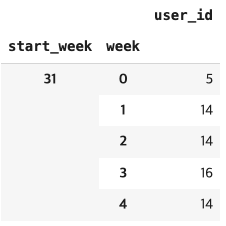
- 하지만 위의 결과는 각 주차에 있는 수강생 수, 우리가 원하는 데이터는 수강 주차별 완료한 총 인원
- 따라서 주차가 증가할수록 전단계의 값이 누적되어 더해져야 함
f=31 # 첫번째 주차
for i in range(6): # 처음 수강 시작한 주의 범위가 {31,32,33,34,35,36}의 6개
for j in range(5, 0, -1):
cohort_data.at[(f,j-1), 'user_id'] = int(cohort_data.at[(f,j),'user_id']) + int(cohort_data.at[(f,j-1),'user_id'])
f=f+1
cohort_data.head()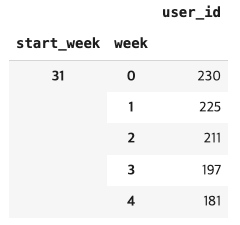
- 코호트 차트 그리기 위해 피벗 테이블로 변환
cohort_data = cohort_data.reset_index()
cohort_counts = cohort_data.pivot(index = 'start_week',columns = 'week',
values = 'user_id')
cohort_counts
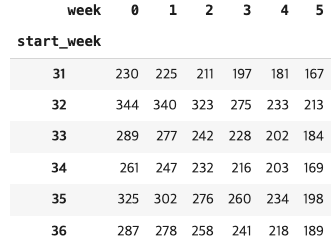
- 개강일별로 전체 인원이 모두 달라 고객의 수로 고객 수강 이탈을 판단하는건 쉽지 않음
- 고객의 행동이 얼만큼 변화가 있는지에 대한 부분을 비율로 나타내기(리텐션 테이블)
(리텐션 : 고객이 우리 제품이나 서비스를 지속적으로 소비하는 것)
retention = cohort_counts
cohort_sizes = cohort_counts.iloc[:,0]
# 최초 수강생의 수로 나눠 각 주당 수강생 수강율 표현
retention = cohort_counts.divide(cohort_sizes, axis=0)
retention.round(3)*100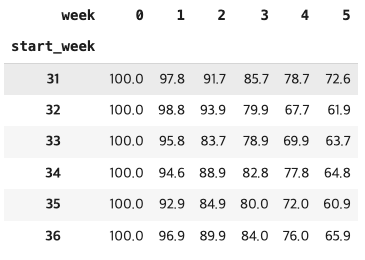
- 히트맵을 이용한 시각화 -> 두개의 카테고리 값에 대한 값 변화 한눈에 보기 쉬움
plt.figure(figsize=(10,8))
sns.heatmap(data=retention,
annot=True,
fmt='.0%',
vmin=0,
vmax=1,
cmap="BuGn")
plt.xlabel('주차', fontsize=14,labelpad=30)
plt.ylabel('개강일', fontsize=14,rotation=360,labelpad=30)
plt.yticks(rotation=360)
plt.show()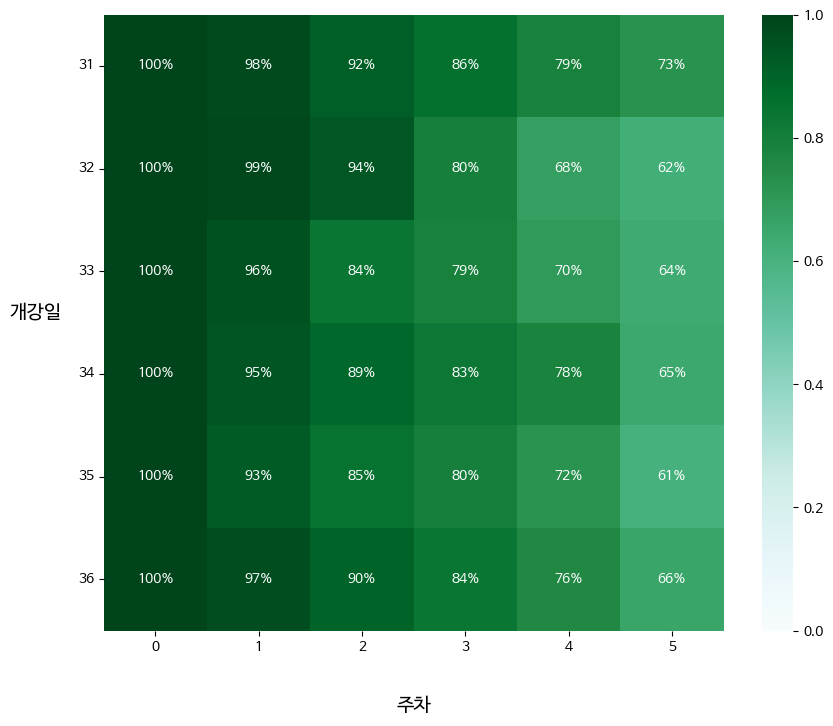
- 3주차 전환을 나타내는 4주차 컬럼에서만 떨어진 것이 아닌 전체적으로 떨어진 것 확인 가능
- 프로덕트의 개선이 아닌 다른 요인에 의해 완주율 떨어진 것으로 보임
- 직전 주차 기준으로 나눈 그래프 그리기
w=31
for i in range(6):
for j in range(5, 1, -1):
retention.at[(w,j)] = retention.at[(w,j)]/retention.at[(w,j-1)]
w=w+1
retention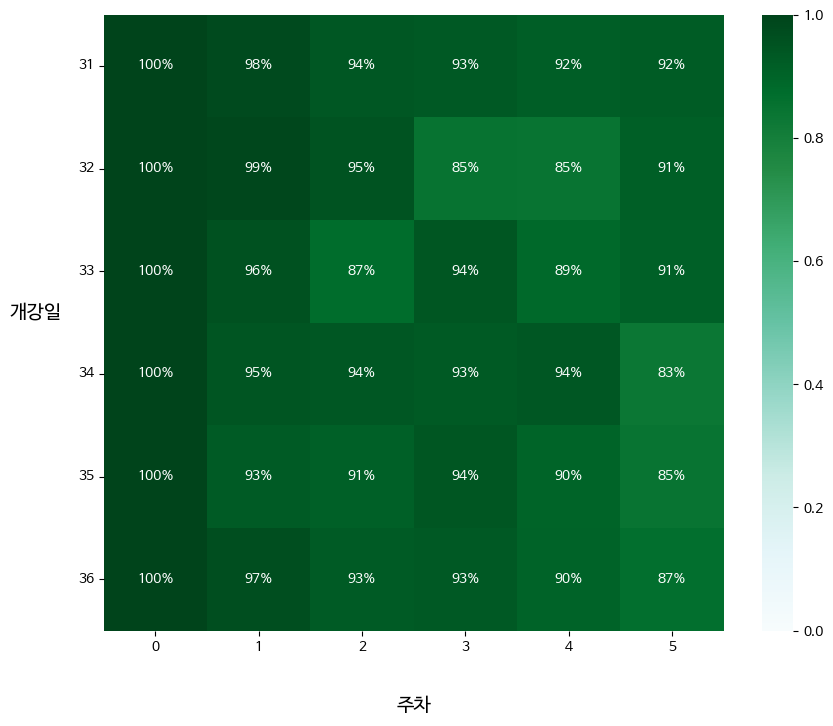
- 직전 주차 대비 수강생 변화를 볼 수 있어 더 해석이 쉬움.

1=850