
1) 기본 키를 변형하는 나쁜 SQL 문
(1) 현황분석

select * from 사원 where substring(사원번호, 1, 4) = 1100
and length(사원번호) = 5;- Type항목이 ALL로 테이블 풀 스캔 방식이며, 인덱스를 사용하지 않고 테이블에 바로 접근
- 사원번호가 PK임에도 SUBSTRING / LENGTH와 같이 가공하여 작성했으므로, 풀 스캔 수행됨
(2) 튜닝 수행

select * from 사원 where 사원번호 between 11000 and 11009;- 범위 검색을 수행하여 사원번호가 변형되지 않아 기본키나 인덱스 활용 가능
- key는 기본키 type은 range로 변경됨
2) 사용하지 않는 함수를 포함하는 나쁜 SQL 문
(1) 현황분석

select ifnull(성별, 'NO DATA') as 성별, COUNT(1) 건수
from 사원
group by ifnull(성별, 'NO DATA');- Type항목이 INDEX로 인덱스 풀 스캔 방식이며, Extra 항목이 Using temporary이므로 임시 테이블을 생성함
- 해당 성별 컬럼은 not null 명시되어 있으므로 ifnull 함수 처리 불필요
(2) 튜닝 수행

select 성별, count(1) as 건수 from 사원 group by 성별;- 불필요한 ifnull 함수 제거
- Extra 항목이 Using index이므로 임시 테이블 없이 인덱스만 사용하여 데이터 추출
3) 형변환으로 인덱스를 활용하지 못하는 나쁜 SQL 문
(1) 현황분석

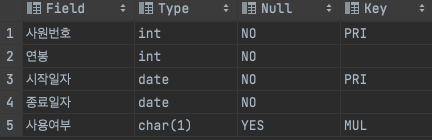
select count(1) from 급여 where 사용여부 = 1;- 인덱스 풀 스캔 / filtered 10.00이므로 MySQL 엔진으로 가져온 데이터 중 10% 추출
- 사용여부의 Type은 char(1)인데 숫자 유형으로 데이터에 접근하여 DBMS 내부의 묵시적 형변환 발생 -> 그 결과 사용여부 컬럼이 인덱스임에도 전체 데이터를 스캔하게 됨
(2) 튜닝 수행

select count(1) from 급여 where 사용여부 = '1';- 인덱스를 사용하여 데이터 접근
- filtered 100 달성
4) 열을 결합하여 사용하는 나쁜 SQL 문
(1) 현황분석

select * from 사원 where concat(성별, ' ', 성) = 'M Radwan';- 테이블 풀 스캔
(2) 튜닝 수행

select * from 사원 where 성별 = 'M' and 성 = 'Radwan';- 성별과 성은 index이 므로 조건문 동등 조건으로 인덱스 활용
5) 습관적으로 중복을 제거하는 나쁜 SQL 문
(1) 현황분석

select distinct 사원.사원번호, 사원.이름, 사원.성, 부서관리자.부서번호
from 사원
join 부서관리자
on 사원.사원번호 = 부서관리자.사원번호;- id 값이 둘 다 1로 동일하게 나타나므로 서로 조인임을 나타낸다.
- 부서관리자 테이블의 type 항목은 index로 인덱스 풀 스캔 수행
- 사원 테이블의 type 항목이 eq_ref이므로 사원번호라는 기본 키를 사용해 단 1건의 데이터를 조회
- DISTINCT를 수행하고자 별도의 임시 테이블(Extra : Using temporary) 생성
(2) 튜닝 수행

select 사원.사원번호, 사원.이름, 사원.성, 부서관리자.부서번호
from 사원
join 부서관리자
on 사원.사원번호 = 부서관리자.사원번호;- 사원 테이블의 기본키는 사원번호로 사원.사원번호에는 중복된 데이터가 없다. 따라서 DISTINCT라는 키워드를 불 필요
- Extra 항목의 Using temporary 삭제
DISTINCT 키워드는 나열된 열들을 정렬한 뒤 중복덴 데이터를 삭제한다. 따라서 DISTINT를 쿼리에 작성하는 것만으로도 정렬 작업이 포함됨을 인지해야 한다.
-> 임시테이블이 만들어지고 정렬과 중복 제거를 수행하게 됨
6) 다수 쿼리를 UNION 연산자로만 합치는 나쁜 SQL 문
(1) 현황분석

select 'M' as 성별, 사원번호
from 사원
where 성별 = 'M'
and 성 = 'Baba'
UNION
select 'F' as 성별, 사원번호
from 사원
where 성별 = 'F'
and 성 = 'Baba';- id 1, 2는 I성별성 인덱스를 사용 / 세 번째 행에서는 1,2행의 결과 통합 및 중복 제거
- extra : Using temporary 임시테이블 생성 (UNION 작업의 결과량이 많다면 메모리가 아닌 디스크에 임시파일을 생성하여 UNION 작업을 하게됨)
(2) 튜닝 수행

select 'M' as 성별, 사원번호
from 사원
where 성별 = 'M'
and 성 = 'Baba'
UNION ALL
select 'F' as 성별, 사원번호
from 사원
where 성별 = 'F'
and 성 = 'Baba';- 사원번호는 PRIMARY키로 중복 제거 작업이 필요하지 않으므로 UNION ALL로 변경
- 불필요한 기존 세번째 행 임시테이블 생성이 사라짐
7) 인덱스 고려 없이 열을 사용하는 나쁜 SQL 문
(1) 현황분석
select 성, 성별, count(1) as 카운트
from 사원
group by 성, 성별;- 사원 테이블의 I성별성 인덱스를 활용하고, 임시 테이블(Using temporary)을 생성하여 성과 성별을 그룹핑해 카운트 연산 수행
(2) 튜닝 수행

select 성, 성별, count(1) as 카운트
from 사원
group by 성별, 성;
- 성별_성 인덱스는 성별 열과 성 열 순으로 생성된 오브젝트, 즉 해당 인덱스는 성별 열 기준으로 정렬된 뒤 성 열 기준으로 정렬 됨.
- 인덱스 순서대로 그룹핑 시 별도의 임시 테이블을 생성하지 않고도 그룹핑 카운트 연산 수행 가능
8) 엉뚱한 인덱스를 사용하는 나쁜 SQL 문
(1) 현황분석

select 사원번호
from 사원
where 입사일자 like '1989%'
and 사원번호 > 100000;- 기본 키로 범위 스캔(type: range) 수행
- 스토리지 엔진으로부터 기본 키를 구성하는 사원번호 데이터를 가져온 뒤, MySQL 엔진에서 남은 필터 조건(like)으로 추출

select 사원번호
from 사원 use index(I_입사일자)
where 입사일자 like '1989%'
and 사원번호 > 100000;- 사원의 총 데이터는 30만 건 / 입사일자 1989년인 데이터는 28000건 / 사원번호가 100000이상인 경우는 21만 건으로, 사원번호 열로 구성된 기본 키로 스토리지 엔진에 접근하는것이 효율적인지 고민이 필요
- USE INDEX 힌트를 설정한 뒤 입사일자 인덱스로 테이블 스캔하지만, 인덱스 루스 스캔 방식(Extar: Using index for skip scan)에 의해 인덱스를 스킵하는 오버헤드 발생 가능
(2) 튜닝 수행

select 사원번호
from 사원
where 입사일자 >= '1989-01-01' and 입사일자 <'1990-01-01'
and 사원번호 > 100000;- 입사일자 열의 데이터 유형은 date 이므로 LIKE절보다 부등호 조건절이 우선하여 인덱스를 사용하므로 데이터 접근 범위 줄일 수 있다.
- 입사일자 인덱스를 활용하여 범위 스캔 수행
- 스토리지 엔진으로부터 입사일자 인덱스에 있는 데이터를 가져온 뒤 MySQL 엔진에서 사원번호에 대한 필터 조건으로 데이터 추출
9) 동등 조건으로 인덱스를 사용하는 나쁜 SQL 문
(1) 현황분석

select * from 사원출입기록 where 출입문 = 'B';- 출입문 인덱스를 사용하여 데이터 접근, 이때 출입문 B에 대한 명확한 상수화 조건으로 데이터 접근 범위를 줄였으므로 ref항목이 const로 출력됨
- 인덱스 스캔을 하지만 출입문 B의 데이터는 전체 66만 건중 30만건 차지, 즉 전체 데이터의 약 50%에 달하는 데이터 조회 시 인덱스 활용 고민 필요
(2) 튜닝 수행

select * from 사원출입기록 IGNORE INDEX(I_출입문)
where 출입문 = 'B';- 대량의 데이터를 인덱스 스캔 시 인덱스를 무시할 수 있도록 IGNORE INDEX라는 힌트 사용 가능
- 대량의 데이터에 대한 인덱스 접근 뒤 테이블에 랜덤 엑세스 하는 방식을 막고 테이블 풀 스캔 방식 수행
10) 범위 조건으로 인덱스를 사용하는 나쁜 SQL 문
(1) 현황분석

select 이름, 성
from 사원
where 입사일자 between str_to_date('1994-01-01', '%Y-%m-%d')
and str_to_date('2000-12-31', '%Y-%m-%d');- 사원 테이블 데이터는 총 30만건인데 결과값은 4만건으로, 인덱스 스캔으로 랜덤 엑세스 부하 발생
(2) 튜닝 수행
select 이름, 성
from 사원
where year(입사일자) between '1994'
and '2000';- 인덱스 없이 테이블에 직접 접근하며 한 번에 다수의 페이지에 접근하므로 더 효율적
참고 - SQL 튜닝 / 양바른 저

Pay it forward