
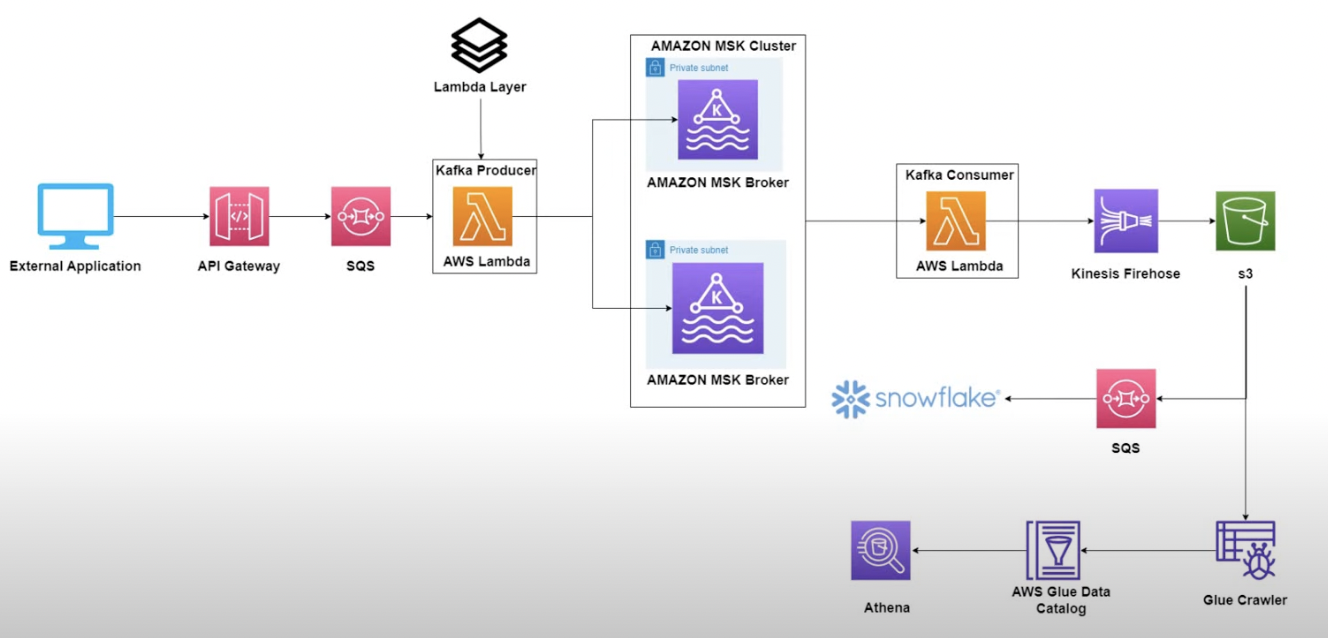
0. 실습 목표
1) Api GateWay를 통해 데이터를 전송
2) Api GateWay 통합 요청을 통해, SQS에 데이터 적재
3) Producer Lambda SQS 트리거 후, 데이터 MSK에 전달
4) Consumer Lambda MSK 트리거 후, kinesis FireHose에 데이터 전달
5) Kinesis FireHose에서 S3 lake로 데이터 적재
*MSK 생성 및 네트워크 구축은 이전 실습을 참고해주세요.
1. Producer Lambda 구축
1) Lambda Layer 생성
sudo apt-get update
sudo apt install python3-virtualenv
virtualenv kafka_yt
source kafka_yt/bin/activate
python3 --version
sudo apt install python3-pip
python3 -m pip install --upgrade pip
mkdir -p lambda_layers/python/lib/python3.8/site-packages
cd lambda_layers/python/lib/python3.8/site-packages
pip install kafka-python -t .
cd /mnt/c/Users/USER/lambda_layers
sudo apt install zip
zip -r kafka_yt_demo.zip *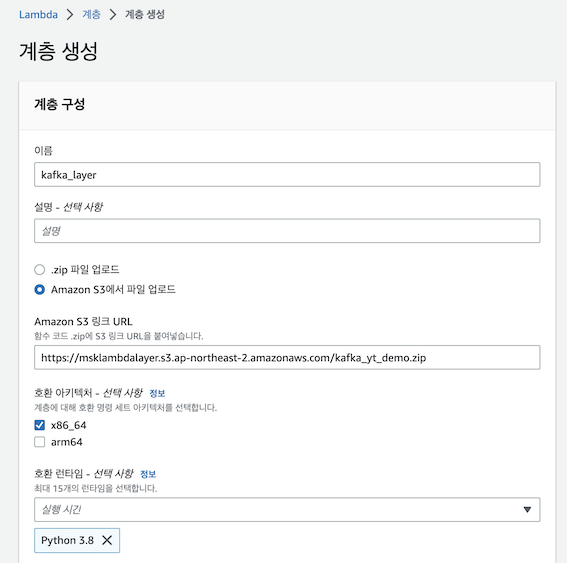
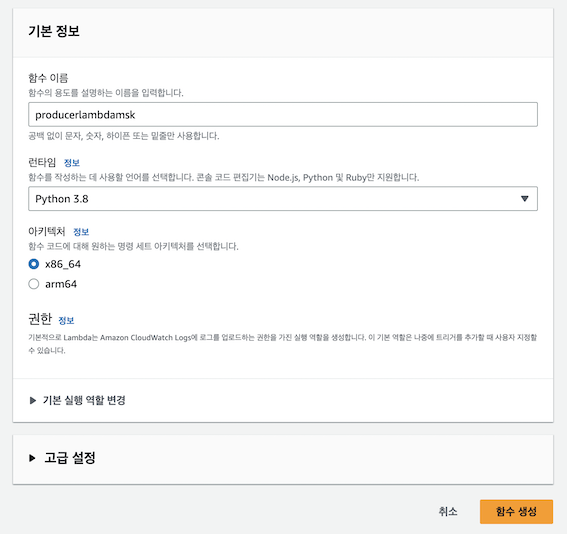
2) Producer Lambda 생성
- Producer Lambda생성 및 코드 deploy
from time import sleep
from json import dumps
from kafka import KafkaProducer
import json
// 토픽반영
topic_name='{Provide the topic name}'
// MSK 부트스랩서버 주소 반영
producer = KafkaProducer(bootstrap_servers=['{Put the broker URLs}'
,'{Put the broker URLs}'],value_serializer=lambda x: dumps(x).encode('utf-8'))
def lambda_handler(event, context):
print(event)
for i in event['Records']:
sqs_message =json.loads((i['body']))
print(sqs_message)
producer.send(topic_name, value=sqs_message)
producer.flush()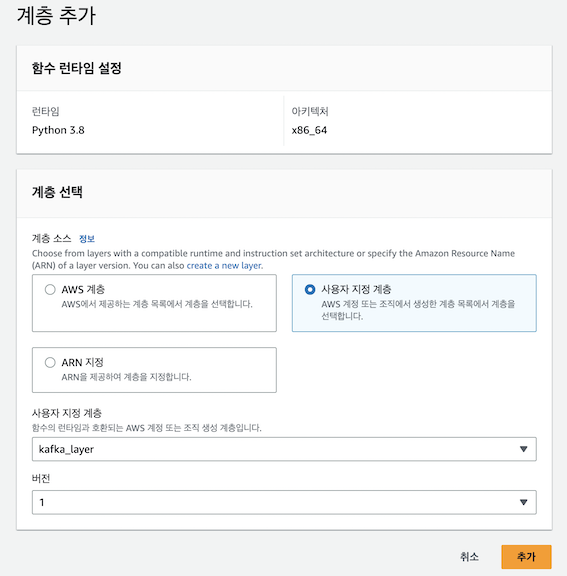
- 위에서 생성한 Lambda Layer 연결
3) Producer Lambda 권한 및 VPC 수정
- VPC, SQS, MSK 정책 연결
- 타임 아웃 2~3분으로 구성
- MSK와 같은 VPC, 서브넷, 보안그룹 적용
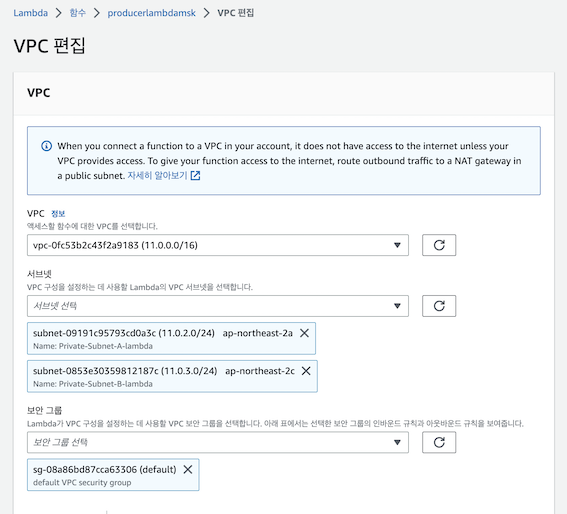
2. AWS SQS 구축
- (중요) Producer Lambda의 타임아웃을 2~3분으로 설정했으므로 SQS 의 visibility timeout은 이보다 길게 설정해야지 람다가 처리중일때 다시 queue에 나타나지 않습니다.
3. AWS API GateWay 구축 및 SQS 통합대상 설정
1) Http Api GateWay 생성
2) 역할 생성
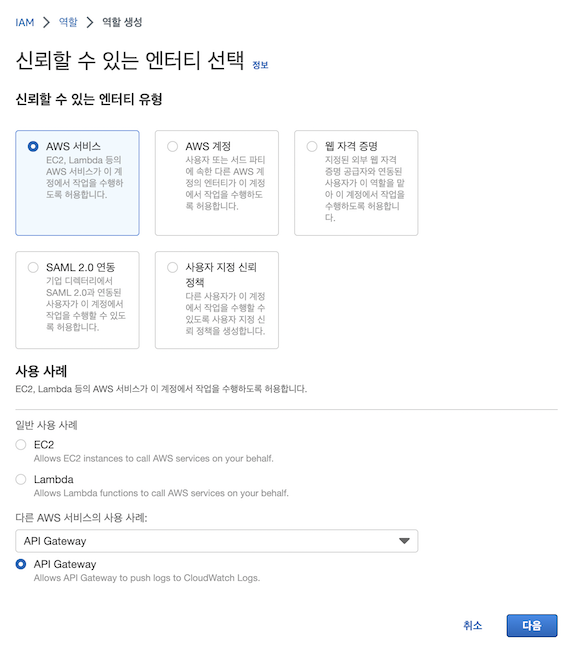
- 생성한 역할에 SQS 정책 연결

3) Route 생성
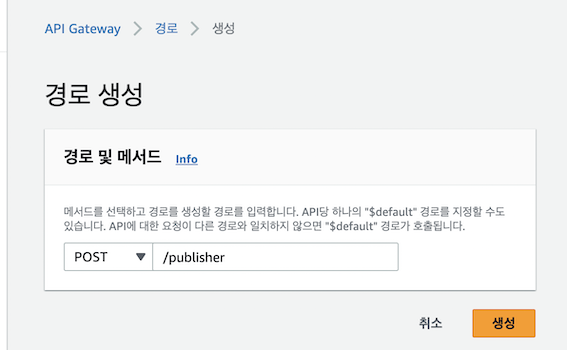
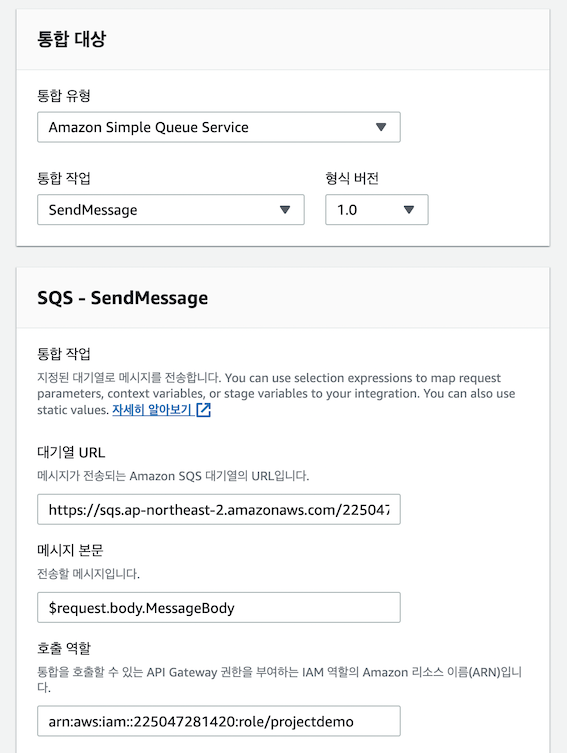
4) 통합 대상 설정
- 생성한 SQS 및 위 역할을 연결
- 리전은 ap-northeast-2로 설정
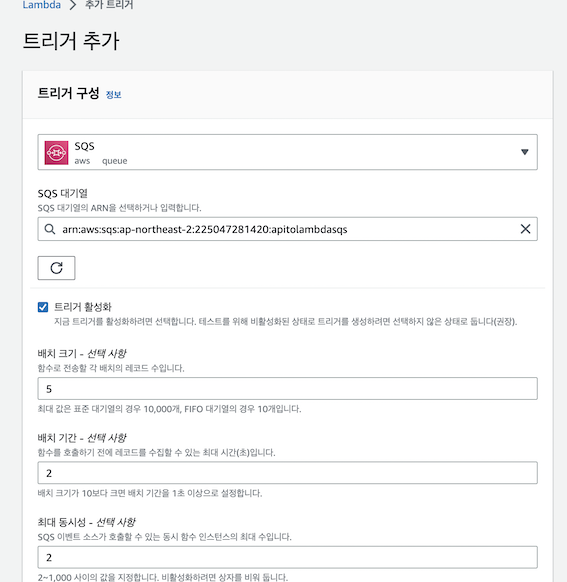
5) Producer Lambda SQS 트리거 설정
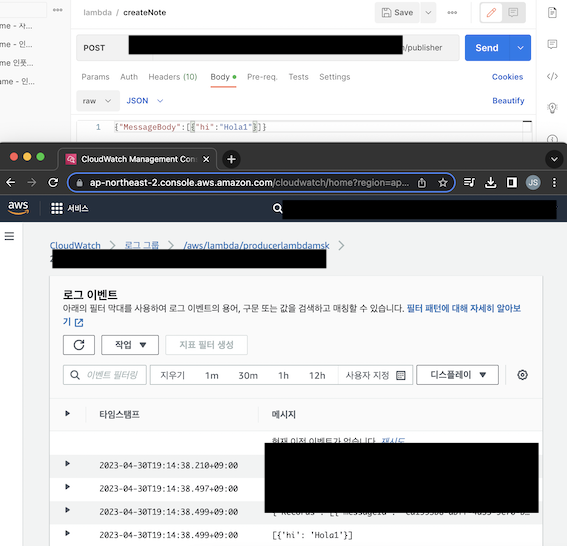
6) Producer Lambda 테스트
4. AWS Kinesis FireHose 및 S3 Lake 구축
<Kinesis FireHose 사용 이유>
로그 데이터를 처리하는 Lambda 함수가 있다고 가정해 봅시다. 이 함수는 파일을 생성하고 S3에 직접 업로드하는 방법으로 구현될 수 있습니다. 그러나, 로그 데이터가 대량으로 생성되는 경우 이 함수는 자주 호출되며 S3에 불필요한 I/O 작업이 발생할 수 있습니다.
대신에, Kinesis Firehose를 사용하여 로그 데이터를 전송하고 일괄 처리 할 수 있습니다. Lambda 함수에서 생성된 로그 데이터는 Kinesis Firehose로 전송되고, Kinesis Firehose는 일정한 시간이나 파일 크기에 도달하면 S3로 배송합니다. 이렇게하면 Lambda 함수에서 S3에 직접 액세스하지 않고도 대량의 데이터를 처리하고 S3 요금을 줄일 수 있습니다.
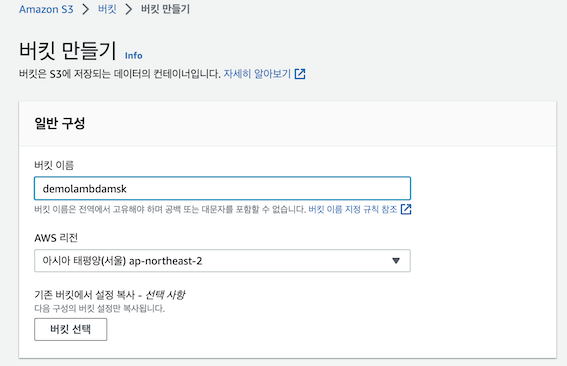
1) S3 버킷 생성
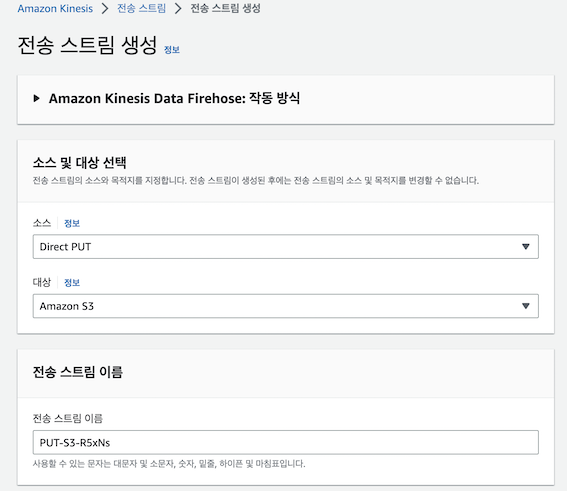
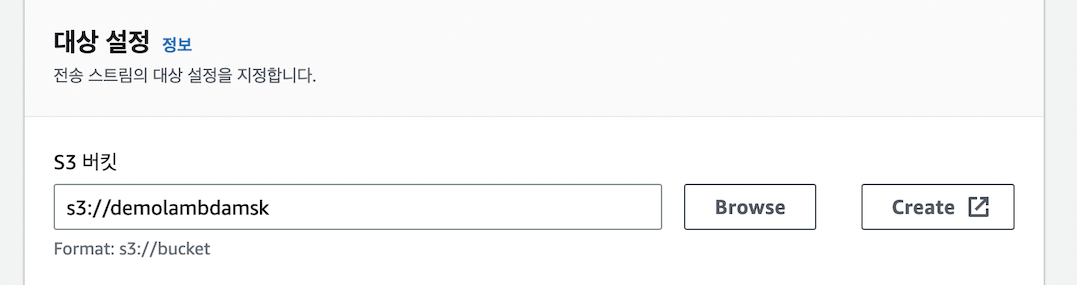
2) Kinesis FireHose 생성 및 S3 lake 적용

4. Consumer Lambda 생성
1) Lambda 생성 및 코드 Deploy
import base64
import boto3
import json
client = boto3.client('firehose')
def lambda_handler(event, context):
print(event)
for partition_key in event['records']:
partition_value=event['records'][partition_key]
for record_value in partition_value:
actual_message=json.loads((base64.b64decode(record_value['value'])).decode('utf-8'))
print(actual_message)
newImage = (json.dumps(actual_message)+'\n').encode('utf-8')
print(newImage)
// 위 생성한 FireHose Name 적용
response = client.put_record(
DeliveryStreamName='{Kinesis Delivery Stream Name}',
Record={
'Data': newImage
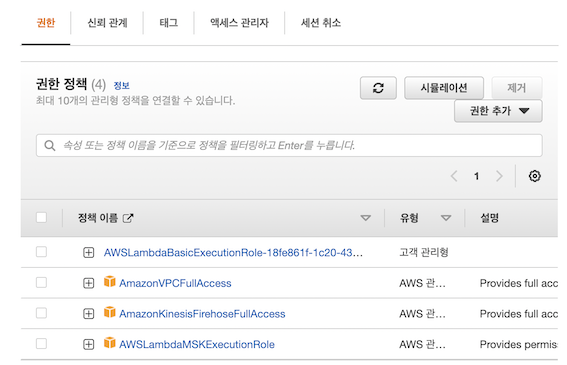
})2) 정책 연결
- MSK, Kinesis FireHose, VPC 정책 연결
3) MSK 트리거 적용
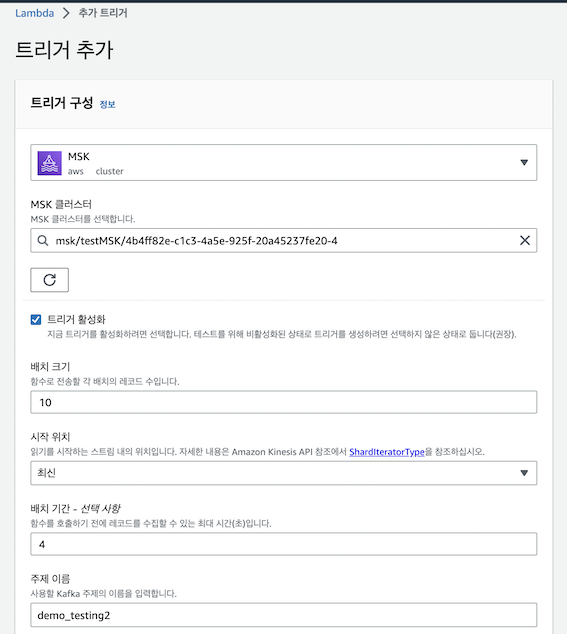
- Msk의 private Subnet이 Natgateway와 연결돼 있으므로 Consumer Lambda는 따로 vpc를 수정하지 않아도 됨
(생략)
- 지난 실습에서 Private Subnet 내 인스턴스를 통해 Topic을 생성했으므로 생략
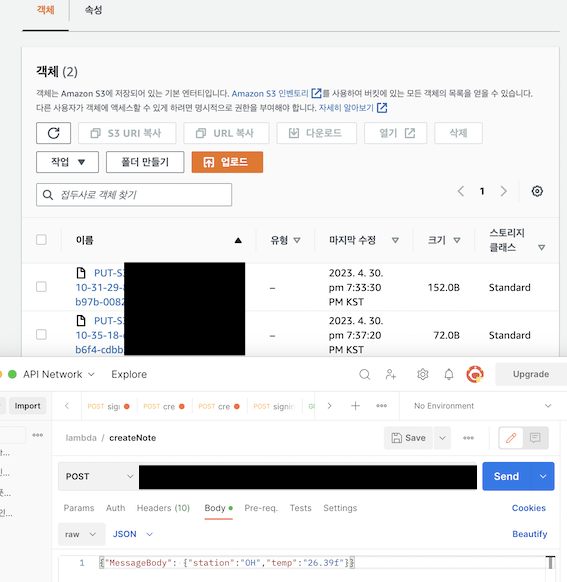
5. S3 Lake 적재 테스트
- Api GateWay Url로 데이터 전송 시, S3 lake 적재 확인

Pay it forward