
1. Model
- 어떤 목적을가지고 진짜를 모방한 것.
- 결국, 좋은 모델이란 목적에 부합하는 모방이다.
- Data Modeling - 문제를 파악 후 추상화 과정을 거쳐 컴퓨터 환경으로 옮겨 담는 작업
2. Data Modeling의 순서
(1) 업무파악
의뢰자로 부터 요구사항을 파악하고 문서 작성
업무 파악의 핵심은 요구사항에 대해 상대방과 대화로 끝을 맺는게 아닌, 문서 or 간단한 UI 구현을 통해 서로의 생각을 일치시키는 과정이다.
(2) 개념적 데이터 모델링
요구사항을 분류 후 어떠한 개념들이 있으며, 각각의 개념들이 어떻게 상호작용하는지 파악한다. 이 과정에서 ER 다이어그램을 적용할 수 있다.
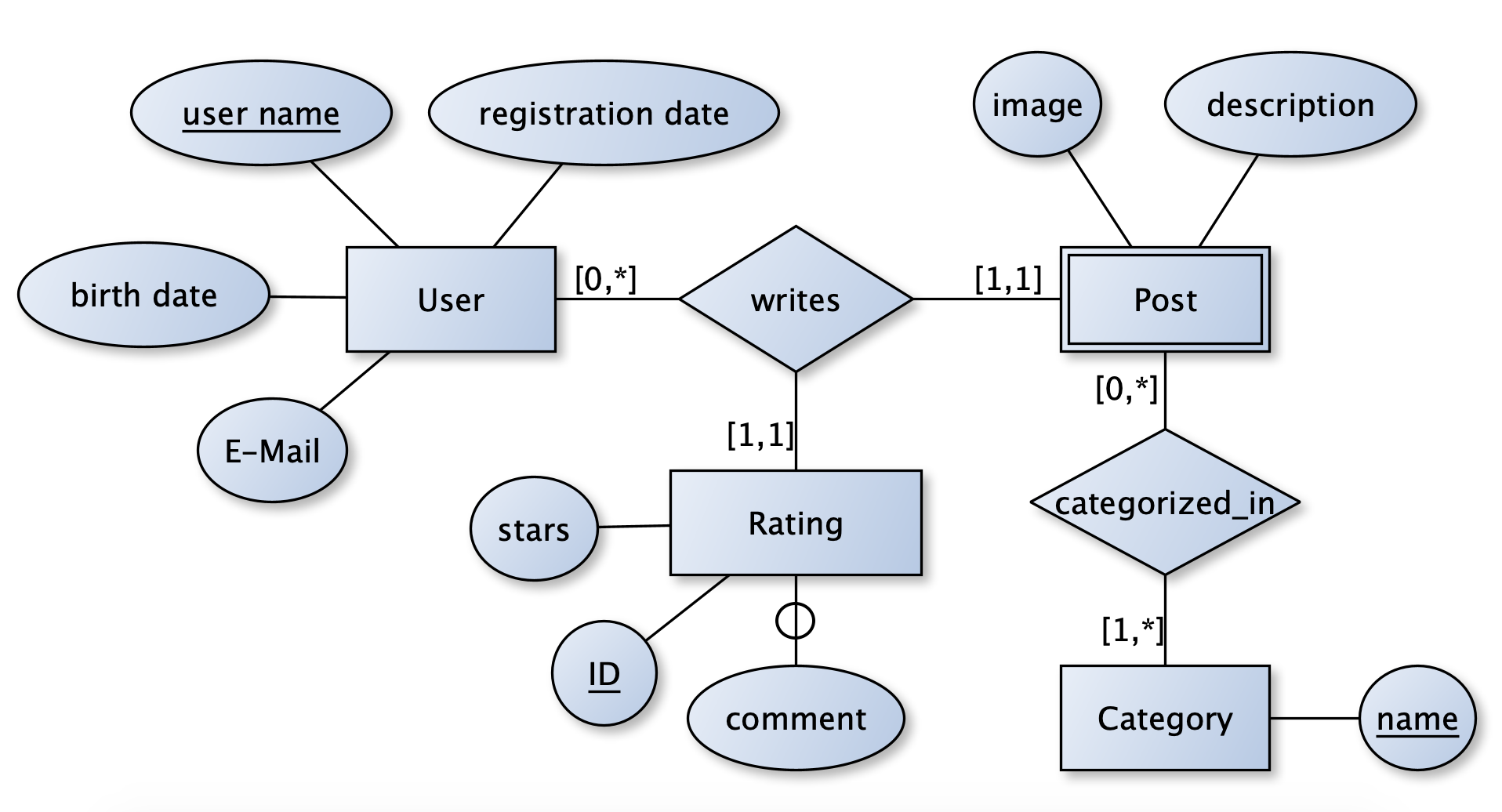
Entity Relationship Diagram
요구사항에 대해 추상화 후 그룹, 정보, 관계로 표현
Entity
- 공통된 정보를 바탕으로 그룹핑 ~ 그룹핑 과정이 없다면 거대 단일 테이플로 표현할 수 밖에 없고, 중복 문제 발생
- 그룹핑의 장점은 검색 시 원하는 그룹에서만 조회 가능
- 관계를 기반으로 그룹에 필요한 데이터 Join으로 조회 가능
- 이렇게 찾아낸 개념(그룹)을 Entity라 표현 ~ 추후 표의 Table
- 그룹에 속한 정보를 Attribute라 표현 ~ 추후 표의 colum
- 그룹관의 관계를 Realation라 표현 ~ 추후 PK, FK
- Table의 행은 Tuple
Attribute
- 각 Attribute의 대표자(Identifier)가 될 수 있는 key를 candidate key라 한다. ex)user_id, email(중복x) 등
- candidate key 중 PK를 정하고 나머지는 alternate key가 된다. ~ secondary index에 사용
Relation
- 각 Table의 관계는 FK와 PK가 연결됨을 통해 관계 형성
(3) 논리적 데이터 모델링
요구사항에 따른 개념을 관계형 DB 표로 표현하는 단계
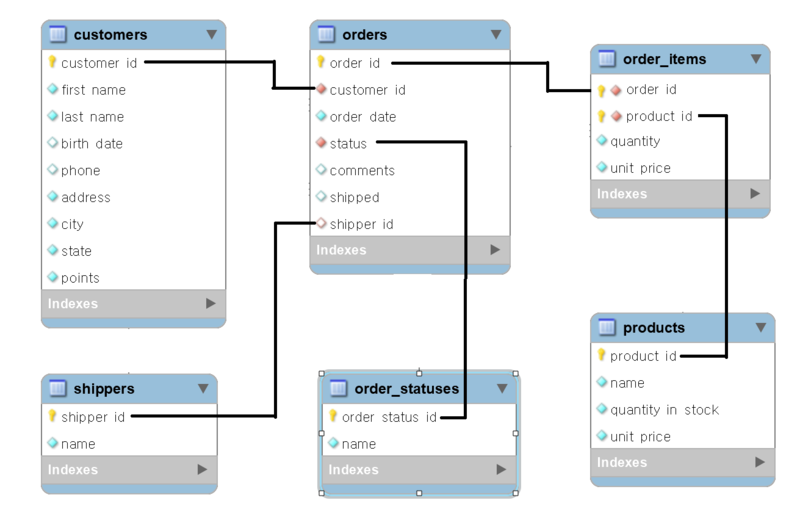
Mapping Rule
- ERD로 표현한 내용을 RDB에 맞는 형식으로 전환하는 방법론
- 1:1 관계에서는 자식 테이블의 PK = FK
- N:M 관계에서는 Mapping Table 필요
Nomalization
- Unnomalized Form ~ 테이블의 값들이 중복되거나, 열거된 경우
제 1 정규화
- 각각의 컬럼의 값이 하나 이상이면 정렬, 조회, 조인에서 문제 발생한다. 따라서 이를 해결하기 위해 컬럼의 값이 atomic 하도록 구성
제 2 정규화
- 부분 종속성 제거 ~ 테이블의 데이터에서 중복 발생 시 새로운 테이블 및 관계 형성
제 3 정규화
- 이행적 종속성 제거 ~ 테이블안의 컬럼들이 서로 의존적 관계인 경우 FK를 기반으로 테이블 분리
(4) 물리적 데이터 모델링
어떤 DB 제품을 사용할 것인지 선택하고, 그 DB에 최적화된 코드를 작성해서 실제 표를 만드는 것, 이때 산출물로 SQL 코드 구현
Denormalization
- 반정규화, 역정규화 ~ 표를 재구조화
- 대체로 정규화는 쓰기 성능 향상을 위해 읽기 성능을 낮춤
(1) 컬럼의 역정규화 - JOIN 줄이기
- JOIN해야 할 컬럼을 본 테이블에 삽입
(2) 컬럼의 역정규화 - 파생 컬럼 형성
- 연산 작업 (Ex) count)을 위한 컬럼 삽입
(2) 테이블의 역정규화
- 컬럼을 기준으로 테이블을 분리
- 행을 기준으로 테이블을 분리
index
- 읽기 성능 향상
cache
- application 영역에서 결과를 저장해 둠 ~ DB 부하 감소

Pay it forward