신경망
신경망을 그림으로 나타내면 다음과 같다.
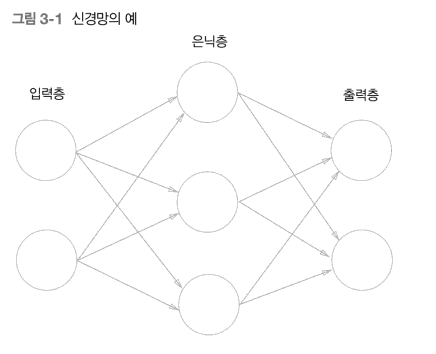
가장 왼쪽 줄을 입력층, 중간 줄을 은닉층, 맨 오른쪽 줄을 출력층이라고 한다.
활성화 함수
입력신호의 총합을 출력 신호로 변환하는 함수를 말한다. 그리고 이 활성화 함수는 임계값을 계기로 출력이 바뀌는데 이런 함수를 계단 함수라고 부른다. 퍼셉트론은 활성화 함수로 쓸 수 있는 여러 후보 중에서 계단 함수를 채용한다.
시그모이드 함수
시그모이드 함수를 나타낸 식은 다음과 같다.
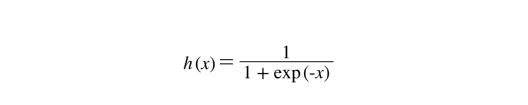
exp(-x)는 e^-x를 뜻한다. 신경망에서는 활성화 함수로 시그모이드 함수를 이용하여 신호를 변환하고, 그 변환된 신호를 다음 뉴런에 전달한다.
계단함수 구현하기
def step_fuction(x):
if x> 0:
return 1
else:
return 0계단함수 그래프로 나타내기
import numpy as np
import matplotlib.pylab as plt
def step_fuction(x):
return np.array(x>0, dtype=int)
x = np.arange(-5.0,5.0,0.1)
y = step_fuction(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1) # y축 범위 지정
plt.show()이것을 실행시키면 아래와 같은 그래프를 얻게 된다.
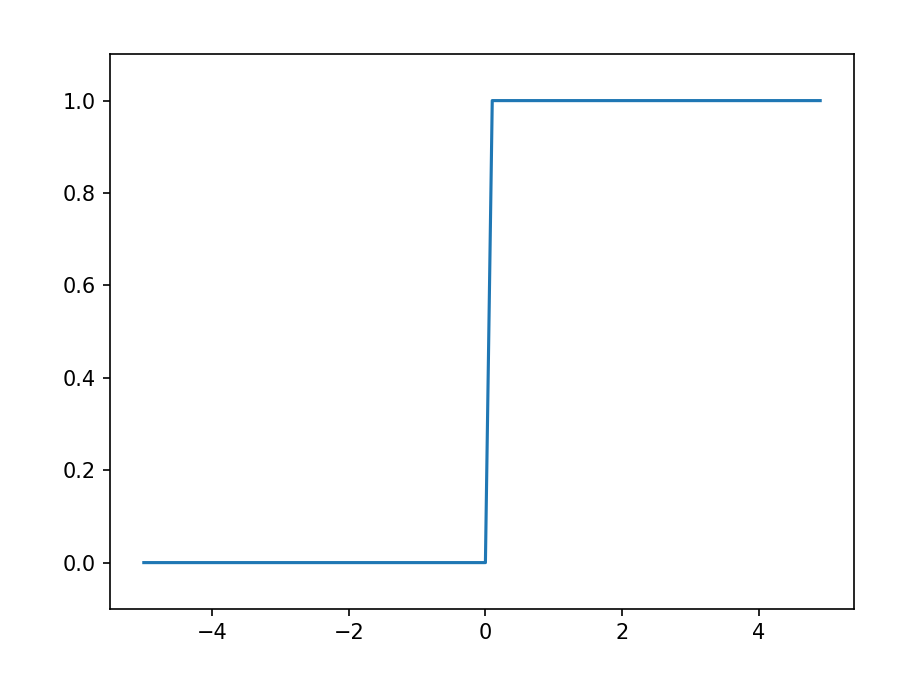
계단함수는 0을 경계로 출력이 0에서 1로 바뀌게 되는 것을 확인할 수 있다.
시그모이드 함수 구현
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.array([-1.0,1.0,2.0])
print(sigmoid(x))시그모이드 함수 그리기
import numpy as np
import matplotlib.pylab as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.arange(-5.0,5.0,0.1)
y = sigmoid(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.show()이 코드를 실행시키면 다음과 같은 그래프를 얻게 된다.
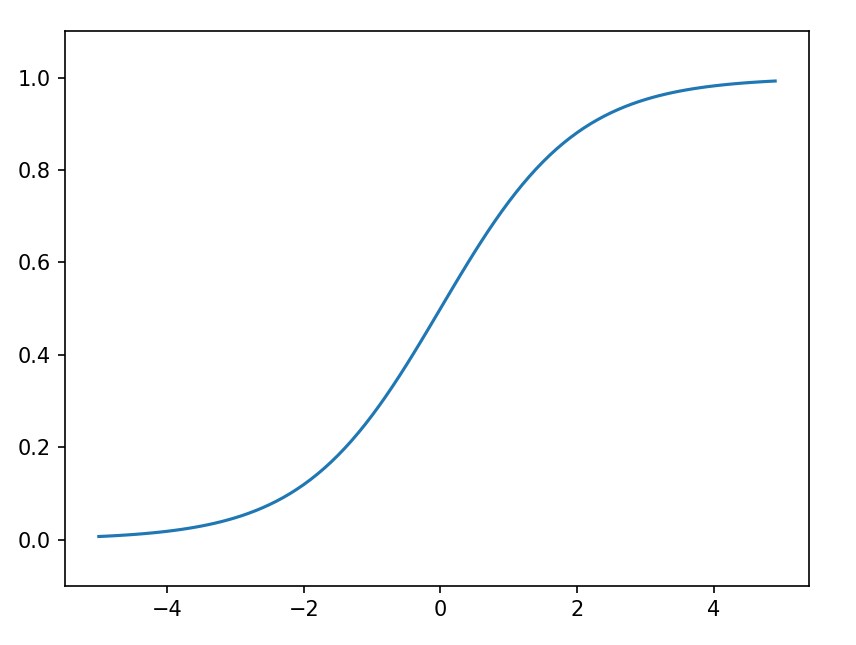
계단함수와 비슷해보이지만 매끈하다는 부분에서 차이가 있는데 바로 이 부분이 신경망 학습에서 중요한 역할을 하게 된다. 그렇기 때문에 시그모이드 함수는 신경망 분야에서 오래전부터 애용해왔지만 최근에는 ReLU 함수를 주로 이용한다.
ReLU 함수의 그래프는 다음과 같다.
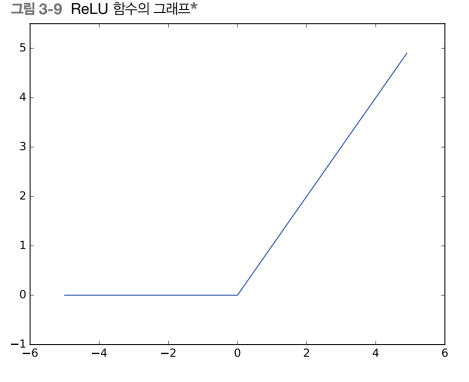
ReLU 함수는 입력이 0을 넘으면 그 입력을 그대로 출력하지만 그렇지 않다면 전부 0을 출력한다.
신경망에서의 행렬의 곱
넘파이 행렬을 통해 신경망을 구현을 해볼려고 한다.
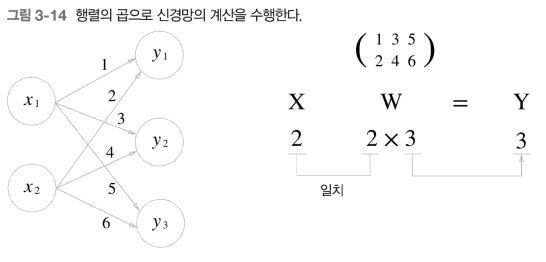
코드로 나타내면 다음과 같다.
import numpy as np
X = np.array([1,2])
W = np.array([[1,3,5],[2,4,6]])
Y = np.dot(X,W) # 행렬의 곱
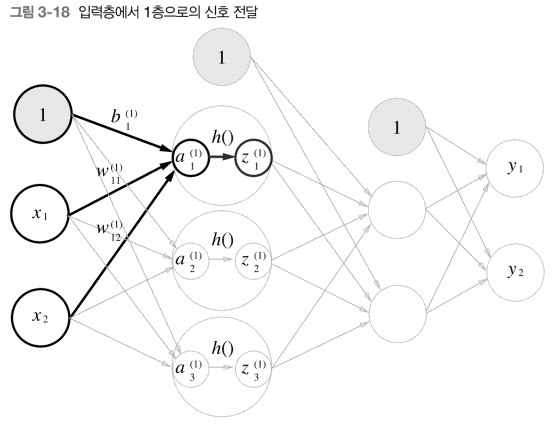
print(Y)이를 토대로 입력층에서 1층으로 신호가 전달되는 것을 그림으로 나타내면 다음과 같다.
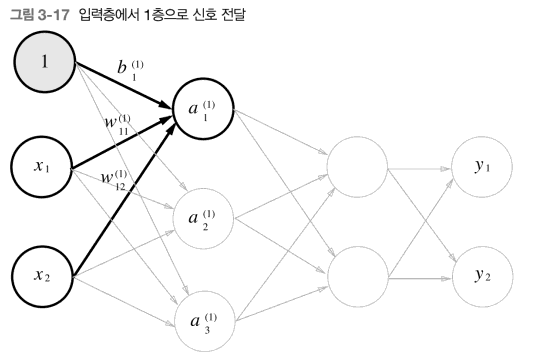
1층의 a를 식으로 나타내면 다음과 같다.
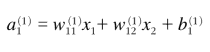
이런식으로 행렬의 곱을 이용하여 1층의 가중치 부분을 간소화할 수 있다. 그 식은 다음과 같다.
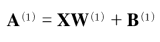
이 때의 행렬을 각각 정리해보면
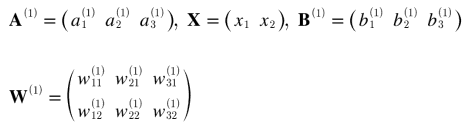 이런 식으로 정리를 해볼 수 있다.
이런 식으로 정리를 해볼 수 있다.
다차원 배열의 곱셈을 이용하여 a를 구하는 코드를 작성해보면 다음과 같다.
import numpy as np
X = np.array([1.0,0.5])
W1 = np.array([[0.1,0.3,0.5],[0.2,0.4,0.6]])
B1 = np.array([0.1,0.2,0.3])
A1 = np.dot(X,W1) + B1
print(A1)이제 이어서 1층의 활성화 함수에서의 처리를 생각해보자. 이것을 그림으로 나타내면 이렇게 표현해볼 수 있다.
은닉층에서의 가중치 합을 a로 표현하고 활성화 함수 h()로 변환된 신호를 z로 표기한다. 여기서 활성화 함수는 sigmoid 함수를 사용한다. 이것을 파이썬으로 구현해본 코드이다.
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
X = np.array([1.0,0.5])
W1 = np.array([[0.1,0.3,0.5],[0.2,0.4,0.6]])
B1 = np.array([0.1,0.2,0.3])
A1 = np.dot(X,W1) + B1
Z1 = sigmoid(A1)
print(Z1)이어서 1층에서 2층으로 가는 과정과 그 구현을 살펴보면
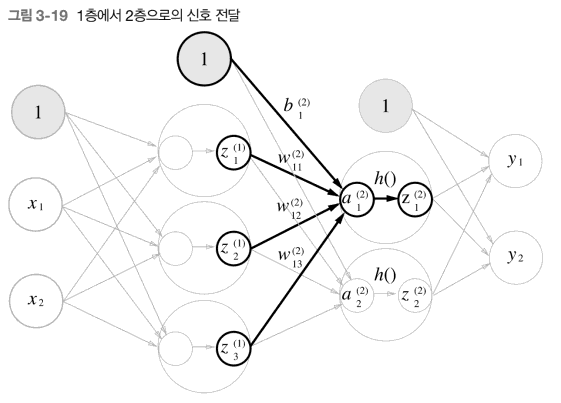
이를 위의 코드와 합해서 구현을 해보면
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
X = np.array([1.0,0.5])
W1 = np.array([[0.1,0.3,0.5],[0.2,0.4,0.6]])
W2 = np.array([[0.1,0.4],[0.2,0.5],[0.3,0.6]])
B1 = np.array([0.1,0.2,0.3])
B2 = np.array([0.1,0.2])
A1 = np.dot(X,W1) + B1
Z1 = sigmoid(A1)
A2 = np.dot(Z1,W2) +B2
Z2 = sigmoid(A2)
print(Z2)이 구현은 1층의 출력 Z1이 2층의 입력이 된다는 점을 제외하고는 조금 전에 구현했던 것과 똑같다. 마지막으로 2층에서 출력층으로의 신호전달이다. 활성화 함수가 지금까지의 은닉층과 다르다는 점을 제외하고는 똑같다.
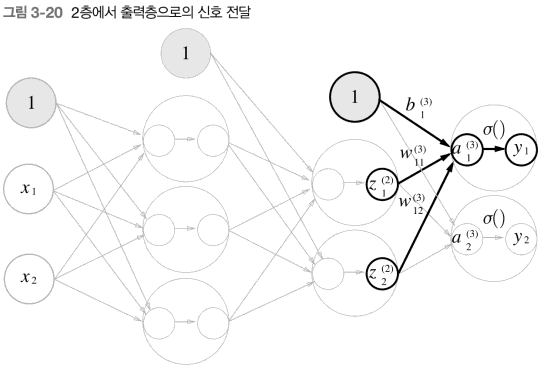
코드로 구현해보면 다음과 같다.
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def identity_function(x):
return x
X = np.array([1.0,0.5])
W1 = np.array([[0.1,0.3,0.5],[0.2,0.4,0.6]])
W2 = np.array([[0.1,0.4],[0.2,0.5],[0.3,0.6]])
B1 = np.array([0.1,0.2,0.3])
B2 = np.array([0.1,0.2])
W3 = np.array([[0.1,0.3],[0.2,0.4]])
B3 = np.array([0.1,0.2])
A1 = np.dot(X,W1) + B1
Z1 = sigmoid(A1)
A2 = np.dot(Z1,W2) + B2
Z2 = sigmoid(A2)
A3 = np.dot(Z2,W3) + B3
Y = identity_function(A3)
print(Y)구현하면서 들었고 책에도 나와있는 내용이지만 굳이 identity_function을 사용할 필요는 없어보인다.
이렇게 해서 신경망의 순방향 구현을 끝내었다.
출력층 설계하기
신경망은 분류와 회귀 모두에 이용할 수 있다. 둘중 어떤 문제냐에 따라서 출력층에 사용하는 활성화 함수가 달라지게 된다. 일반적으로 회귀에는 항등 함수를, 분류에는 소프트맥스 함수를 사용한다.
기계학습 문제는 분류와 회귀로 나뉘는데 분류는 데이터가 어느 클래스에 속하느냐를 푸는 문제이고 회귀는 입력 데이터에서 연속적인 수치를 예측하는 문제이다.
항등함수는 입력을 그대로 출력한다. 그래서 출력층에서 항등함수를 사용하면 입력 신호가 그대로 출력되게 된다.
분류에서 사용하는 소프트맥스 함수의 식은 다음과 같다.
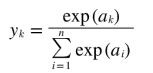
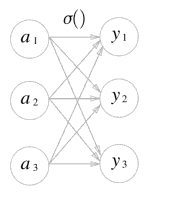
이 소프트맥스를 그림으로 나타내면 이런 식으로 나타낼 수 있다.
이 소프트맥스 함수를 파이썬을 활용하여 구현해보면 다음과 같다.
import numpy as np
a = np.array([0.3,2.9,4.0])
exp_a = np.exp(a)
print(exp_a)
sum_exp_a = np.sum(exp_a)
print(sum_exp_a)
y = exp_a / sum_exp_a
print(y)하지만 이렇게 구현하면 overflow 문제가 발생하는 경우가 있기 때문에 위의 식을 조금 개선해야 한다.
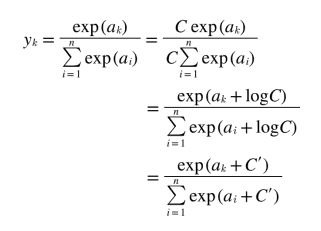
지수함수를 계산할 때에 어떤 정수를 더하고 빼도 계산결과는 바뀌지 않기 때문에 보통 C'에 입력 신호중 최대값을 넣어서 계산을 한다. 이를 토대로 소프트맥스를 다시 구현해보면 다음과 같다.
import numpy as np
def softmax(a):
c = np.max(a)
exp_a = np.exp(a-c)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
a = np.array([0.3,2.9,4.0])
y = softmax(a)
print(y)
sum = np.sum(y)
print(sum)소프트맥스의 출력은 0~1사이이고 이를 모두 합한 총 합은 1이 나오게 된다. 출력의 총 합이 항상 1이 되는것이 소프트맥스의 중요한 성질이다. 이것 덕분에 소프트맥스 함수의 출력을 확률로 해석할 수 있다.
손글씨 숫자 인식
기계학습의 문제풀이는 학습과 추론의 두 단계를 거쳐야한다.학습단계에서 모델을 학습하고 추론단계에서 앞서 학습한 모델로 미지의 데이터에 대해서 추론을 수행한다. 기계학습과 마찬가지로 신경망도 두 단계를 거쳐 문제를 해결한다. 먼저 훈련 데이터를 사용해 가중치 매개변수를 학습하고, 추론 단계에서는 앞서 학습한 매개변수를 사용하여 입력 데이터를 분류한다.
MNIST 데이터셋
MNIST 데이터셋을 이용하여 모델을 학습하고, 학습한 모델로 시험 이미지들을 얼마나 정확하게 분류하는지 평가한다.
이를 준비하는 코드는 다음과 같다.
import sys
import os
sys.path.append(os.pardir) # 부모 디렉토리
from dataset.mnist import load_mnist # dataset폴더에 있는 mnist라는 파일에서 load_mnist라는 함수를 import 해라
(x_train, t_train), (x_test, t_test) = \
load_mnist(flatten=True, normalize=False)
print(x_train.shape)
print(t_train.shape)
print(x_test.shape)
print(t_test.shape)load_mnist 함수는 읽은 데이터를 (훈련이미지,훈련레이블), (시험이미지,시험레이블) 형식으로 반환한다. 인수로는 normalize, flatten, one_hot_label 세 가지를 설정할 수 있다. 세 인수 모두 bool 값이다. 첫 번째 인수인 normalize는 입력 이미지의 픽셀값을 0.0~1.0 사이의 값으로 정규화할지를 정한다. False로 설정하면 입력이미지의 픽셀은 원래 값 그대로 0~244 사이의 값을 유지한다. 두 번째 인수인 flattern은 입력 이미지를 평탄하게 1차원 배열로 만들지를 정한다. False로 설정하면 입력 이미지를 1x28x28의 3차원 배열로, True로 설정하면 784개의 원소로 이뤄진 1차원 배열로 저장한다. 세 번째 인수인 one_hot_label은 레이블을 원-핫-인코딩 형태로 저장할지를 정한다. 원-핫 인코딩이란 정답을 뜻하는 원소만 1이고 나머지는 모두 0인 배열이다. 이것이 False이면 7이나 2와 같은 숫자 형태의 레이블을 저장하고 True이면 원-핫 인코딩하여 레이블을 저장한다.
MNIST 이미지를 불러오도록 하는 코드는 다음과 같다.
import sys
import os
import numpy as np
sys.path.append(os.pardir) # 부모 디렉토리
from dataset.mnist import load_mnist # dataset폴더에 있는 mnist라는 파일에서 load_mnist라는 함수를 import 해라
from PIL import Image
def img_show(img):
pil_img = Image.fromarray(np.uint8(img)) # 넘파이로 저장된 이미지 데이터를 PIL용 데이터 객체로 변환하는 함수
pil_img.show()
(x_train, t_train), (x_test, t_test) = \
load_mnist(flatten=True, normalize=False) # flattern = True로 설정해 읽어 들인 이미지는 1차원 넘파이 배열로 저장
img = x_train[0]
label = t_train[0]
print(label)
print(img.shape)
img = img.reshape(28,28) # 원래 이미지 모양으로 변형
print(img.shape)
img_show(img)이것을 실행해서 얻은 결과는 다음과 같다.

이렇게 얻은 MNIST 데이터셋을 가지고 추론을 수행하는 신경망을 구현하려 한다. 이 신경망은 입력층 뉴런이 이미지의 크기가 28x28이기 때문에 784이고 출력층은 0~9까지의 숫자를 구분하기 때문에 10이 된다. 은닉층은 2개로 첫 번째 은닉층에서 50개의 뉴런을, 두 번째 은닉층에서 100개의 뉴런을 배치하고자 한다. 50과 100은 임의의 값이다.
이를 코드로 나타내면 다음과 같다.
import sys
import os
import numpy as np
import pickle # 파이썬에서 리스트나 클래스 이외의 자료형을 파일로 저장하고자 할때 사용
from common.functions import sigmoid,softmax
sys.path.append(os.pardir) # 부모 디렉토리
from dataset.mnist import load_mnist # dataset폴더에 있는 mnist라는 파일에서 load_mnist라는 함수를 import 해라
from PIL import Image
def img_show(img):
pil_img = Image.fromarray(np.uint8(img)) # 넘파이로 저장된 이미지 데이터를 PIL용 데이터 객체로 변환하는 함수, uint8 : 2^8만큼 표현가능 0~255
pil_img.show()
def get_data():
(x_train, t_train), (x_test, t_test) = \
load_mnist(flatten=True, normalize=False, one_hot_label=False) # flattern = True로 설정해 읽어 들인 이미지는 1차원 넘파이 배열로 저장
return x_test, t_test
def init_network():
with open("C:\image\sample_weight.pkl",'rb') as f: # sample_weight-이미학습된 개체, 왜인지몰라도 같은 폴더에 넣어놨더니 못읽어오길래 다른 경로로 집어넣어서 실행함. open_as rb는 읽기모드와 바이너리모드가 동시에 적용된 것.
# sample_weight를 불러와서 f라는 변수로 치환
network = pickle.load(f)
return network
def predict(network, x): # 각 레이블의 확률을 넘파이 배열로 반환한다.
W1,W2,W3 = network['W1'],network['W2'],network['W3']
b1,b2,b3 = network['b1'],network['b2'],network['b3']
a1 = np.dot(x,W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1,W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2,W3) + b3
y = softmax(a3)
return y
x, t = get_data()
network = init_network()
accuracy_cnt = 0
for i in range(len(x)):
y = predict(network,x[i])
p = np.argmax(y)
if p == t[i]: # 신경망이 숫자를 맞췄다면
accuracy_cnt += 1 # 그 횟수를 증가시킨다.
print('Accuracy:' + str(float(accuracy_cnt)/len(x))) # len(x)는 전체 이미지 숫자이고 신경망이 맞춘 숫자를 전체 이미지 숫자로 나눠서 정확도를 구한다. 배치 처리
하나로 묶은 입력 데이터를 배치라고 한다. 배치처리는 이미지 1장당 처리 시간을 대폭 줄여준다. 크게 두 가지 이유를 생각할 수 있는데 하나는 수치 계산 라이브러리 대부분이 큰 배열을 효율적으로 처리할 수 있도록 고도로 최적화 되어있기 때문이고 다른 하나는 커다란 신경망에서는 데이터 전송이 병목으로 작용하는 경우가 자주 있는데 배치 처리를 함으로써 버스에 주는 부하를 줄인다는 것이다. 즉, 컴퓨터에서는 작은 배열을 여러 번 계산하는것보다 큰 배열을 한 번 계산하는 것이 빠르다.
배치 처리를 구현해보면 다음과 같다.
import sys
import os
import numpy as np
import pickle # 파이썬에서 리스트나 클래스 이외의 자료형을 파일로 저장하고자 할때 사용
from common.functions import sigmoid,softmax
sys.path.append(os.pardir) # 부모 디렉토리
from dataset.mnist import load_mnist # dataset폴더에 있는 mnist라는 파일에서 load_mnist라는 함수를 import 해라
from PIL import Image
def img_show(img):
pil_img = Image.fromarray(np.uint8(img)) # 넘파이로 저장된 이미지 데이터를 PIL용 데이터 객체로 변환하는 함수, uint8 : 2^8만큼 표현가능 0~255
pil_img.show()
def get_data():
(x_train, t_train), (x_test, t_test) = \
load_mnist(flatten=True, normalize=False, one_hot_label=False) # flattern = True로 설정해 읽어 들인 이미지는 1차원 넘파이 배열로 저장
return x_test, t_test
def init_network():
with open("C:\image\sample_weight.pkl",'rb') as f: # sample_weight-이미학습된 개체, 왜인지몰라도 같은 폴더에 넣어놨더니 못읽어오길래 다른 경로로 집어넣어서 실행함. open_as rb는 읽기모드와 바이너리모드가 동시에 적용된 것.
# sample_weight를 불러와서 f라는 변수로 치환
network = pickle.load(f)
return network
def predict(network, x): # 각 레이블의 확률을 넘파이 배열로 반환한다.
W1,W2,W3 = network['W1'],network['W2'],network['W3']
b1,b2,b3 = network['b1'],network['b2'],network['b3']
a1 = np.dot(x,W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1,W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2,W3) + b3
y = softmax(a3)
return y
'''
x, t = get_data()
network = init_network()
accuracy_cnt = 0
for i in range(len(x)):
y = predict(network,x[i])
p = np.argmax(y)
if p == t[i]: # 신경망이 숫자를 맞췄다면
accuracy_cnt += 1 # 그 횟수를 증가시킨다.
'''
x, t = get_data()
network = init_network()
batch_size = 100
accuracy_cnt = 0
for i in range(0,len(x), batch_size): # 0부터 batch_size 만큼 묶어나간다.
x_batch = x[i:i+batch_size]
y_batch = predict(network, x_batch)
p = np.argmax(y_batch,axis = 1) # 100x10의 배열 중 1차원을 구성하는 각 원소에서(1번째 차원을 축으로) 최대값의 인덱스를 찾도록 한 것
accuracy_cnt += np.sum(p == t[i:i+batch_size])
print('Accuracy:' + str(float(accuracy_cnt)/len(x))) # len(x)는 전체 이미지 숫자이고 신경망이 맞춘 숫자를 전체 이미지 숫자로 나눠서 정확도를 구한다. 출처 : 밑바닥부터 시작하는 딥러닝: 파이썬으로 익히는 딥러닝 이론과 구현 - 사이토 고키(2017)
