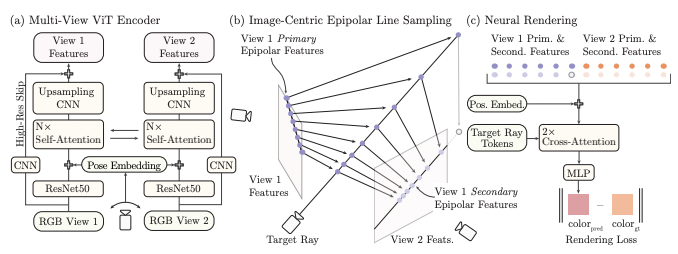
- 각 이미지에서 따로 인코딩한 feature로 학습시킬 경우 생기는 artifact를 제거하기 위해 relative pose와 함께 두 이미지 간의 self-attention이 이뤄지는 Multi-View ViT Encoder 제안
- 두 개의 이미지만을 쓰기 때문에 epipolar line을 벗어나는 정보는 필요없음을 활용하여 효율적으로 sampling
- Image1의 feature와 그에 상응하는 Image2의 feature(secondary feature)를 concat하여 final set을 만들며 그 반대 방향 정보도 똑같이 만들어준다.
