[Point Review] SceneScape: Text-Driven Consistent Scene Generation
-
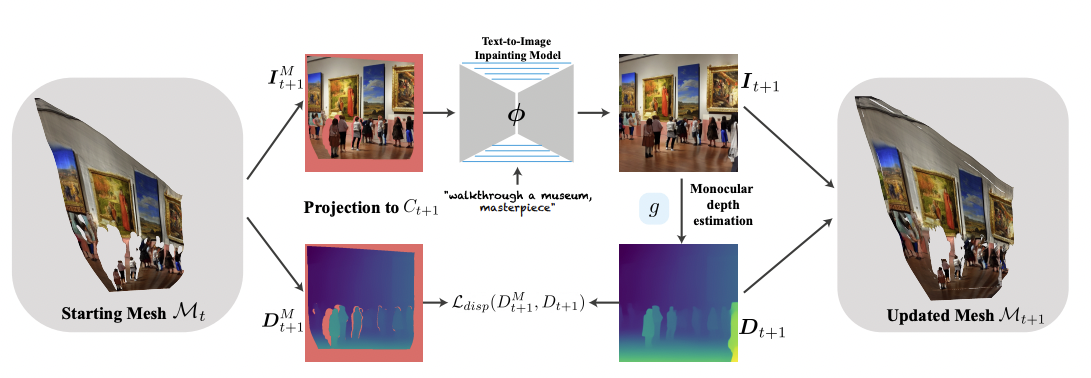
Text와 camera trajectory가 주어졌을 때 zero-shot으로 scene에 대한 video를 생성
-
Pretrained diffusion model로 initial view를 만든 뒤 pretrained depth estimation model로 depth 예측
-
다음 frame으로 warping 하는 것이 naive한 방법이지만 여러 pixel이 한 pixel로 mapping 되는 문제가 있으며 unified representation이 아니므로 mesh를 활용함
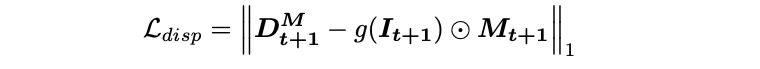
-
Mesh를 다음 frame으로 projection 시킨 후 depth estimation을 하는데 consistency를 유지하기 위해 위와 같은 loss term을 추가함
