Introduction
- Siamese-RPN을 활용한 off-line trained 딥러닝 모델
- Template branch와 Detection branch의 correlation feature map을 활용한다.
- Template branch는 RPN에서 커널로 이용되어 meta-learner라 칭해진다.
- Online tracking 시 첫번째 프레임으로부터 추출된 meta-learner를 고정된 커널로 사용하고 Detection branch만 들어오므로 one-shot detection이라 할 수 있다.
Contributions
- 오프라인에서 큰 스케일의 이미지 쌍을 end-to-end로 학습하는 Siamse-RPN 활용
- 온라인 tracking 시 one shot detection으로 구성
- 160FPS의 속도를 보이며 정확도와 효율성에서 모두 좋은 성과
Siamese-RPN framework
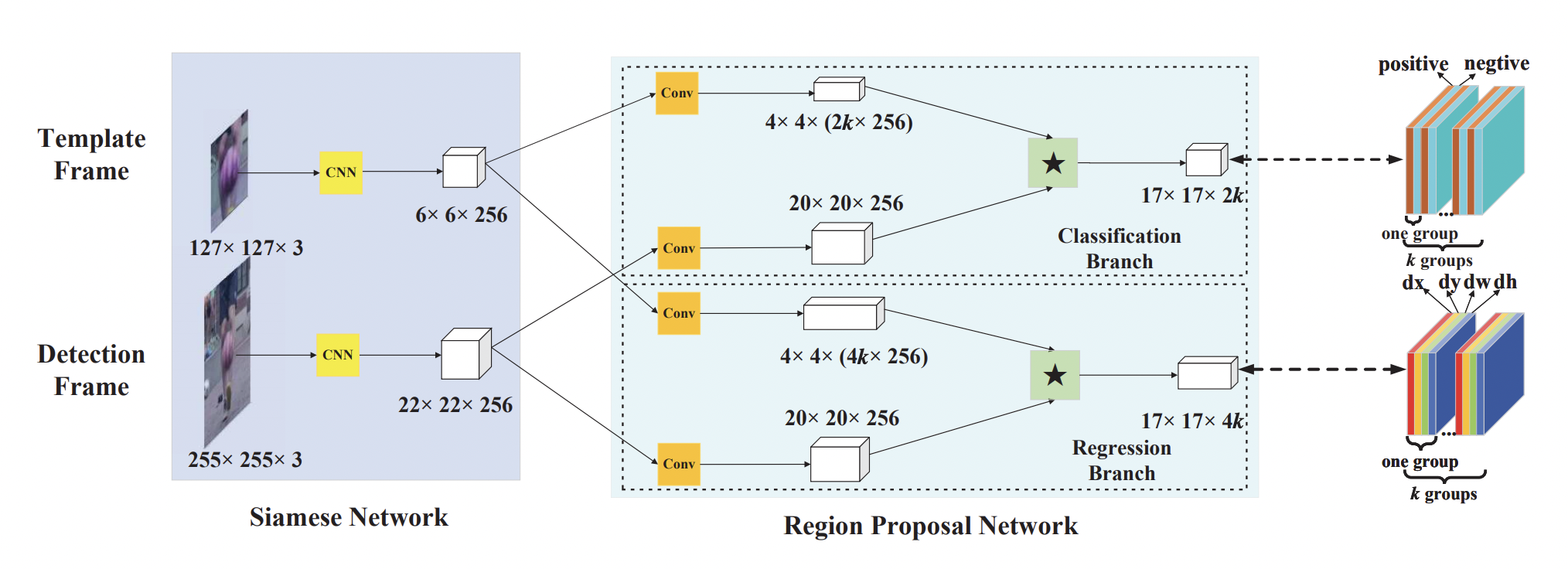
특징을 추출하기 위한 Siamese subnetwork와 proposal을 만들기 위한 region proposal subnetwork로 구성된다. RPN subnetwork는 배경 여부를 구분하는 branch와 박스의 위치를 조정해주는 branch로 나뉜다.
Siamse feature extraction subnetwork
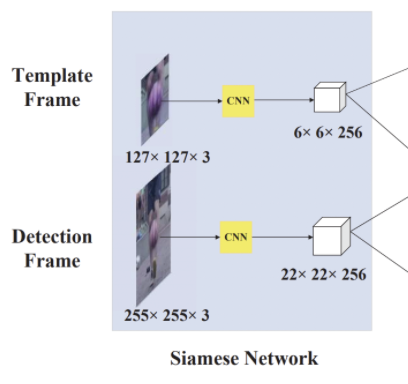
- template branch: 이전 프레임에서의 target을 input으로 넣어주며 z로 표기한다.
- detection branch: 현재 프레임의 target을 input으로 넣어주며 x로 표기한다.
- 두 개의 input은 공통된 fully convolution network를 거쳐 feature map을 추출하며 (z)와 (x)로 표기한다.
Region proposal subnetwork
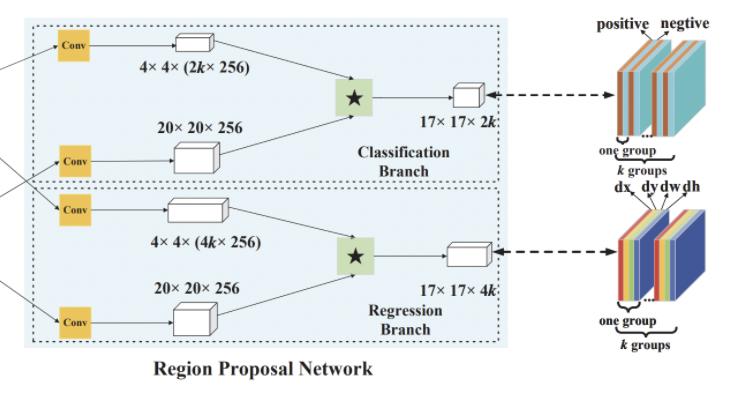
pair-wise correlation section과 supervision section으로 구성되며 supervision section은 classification branch와 regression branch로 나뉜다.
pair-wise correlation section
- k의 anchor가 있을 때 classification을 위한 2k의 채널과 regression을 위한 4k의 채널이 필요하므로 (z)를 convolution layer를 통해 [(z)]와 [(z)]로 나눠준다.
- (x)도 두 개의 branch [(x)], [(x)]로 나뉘지만 채널의 수는 그대로 유지한다.
- [(z)]가 [(x)]의 필터로 사용되어 두 branch에 대해서 모두 correlation이 계산된다.(★은 convolution 연산)
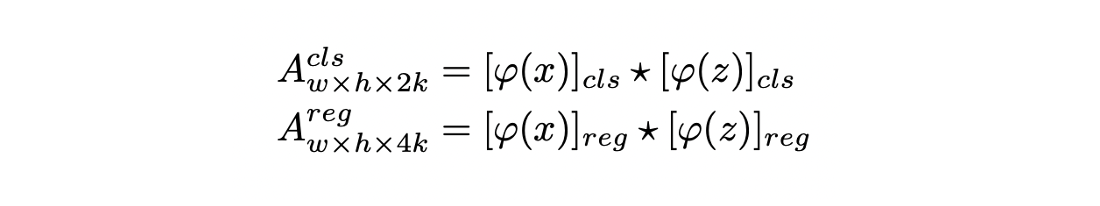
supervision section
- 는 각 anchor에 대한 classification이 2개의 채널(positive, negative)로 나오며 cross entropy loss가 적용된다.
- 는 상응하는 ground truth와의 거리인 ()가 담긴 4개의 채널이 나오며 정규화된 좌표의 smooth loss가 적용된다.
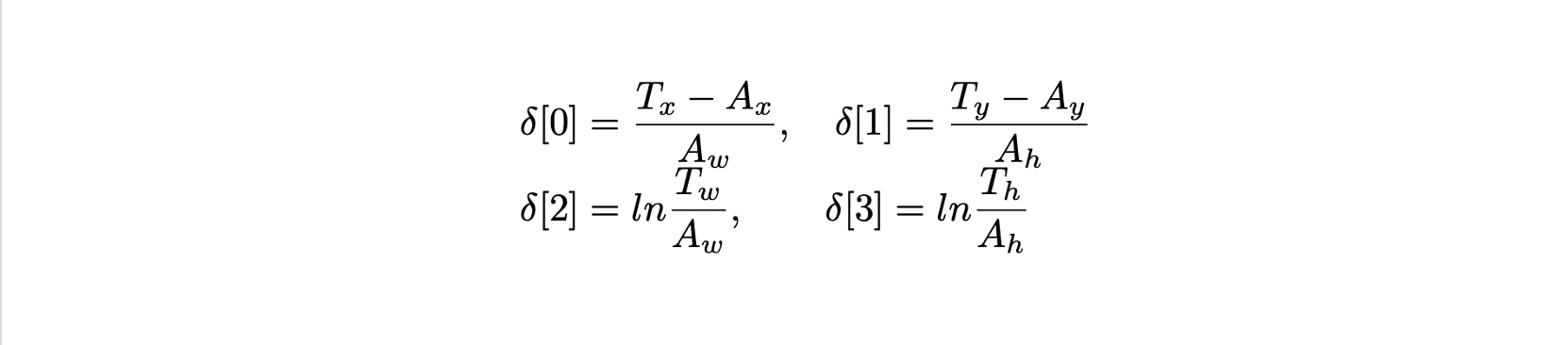
- : anchor boxes의 center point
- : ground truth의 center point
- : 정규화된 거리
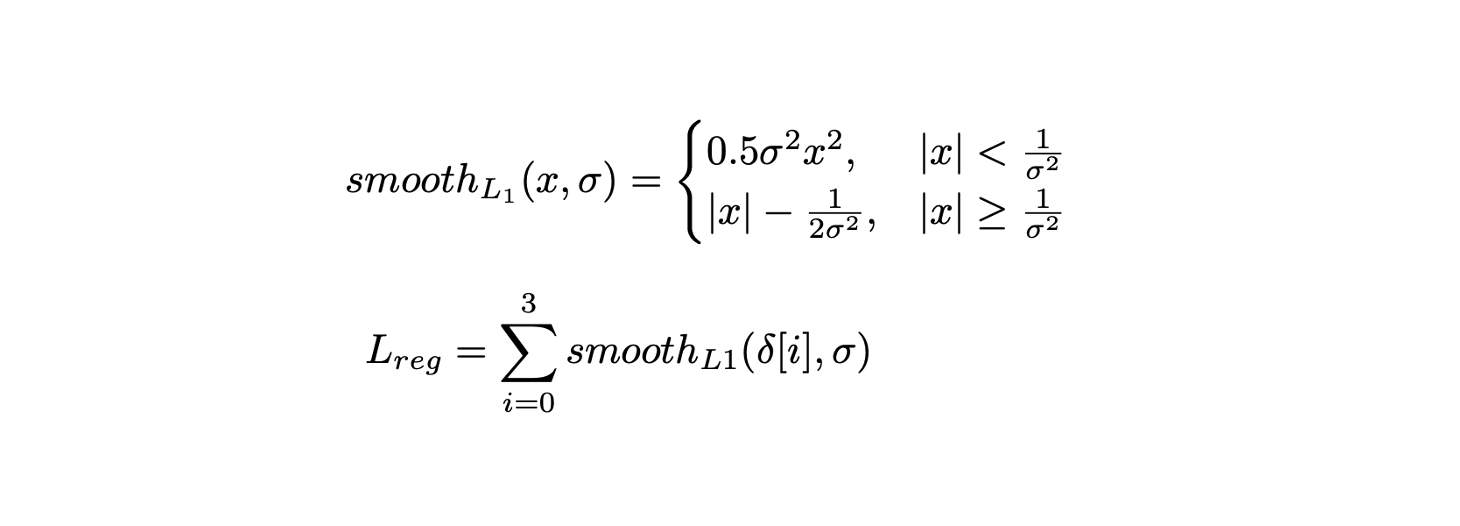
최종 Loss는 regression Loss에 가중치를 주어 구성한다.
Training phase: End-to-end train Siamese-RPN
- 같은 영상 내 2개의 프레임에서 template patch와 detection patch를 추출
- 이미지넷으로 pretrain 된 Siamese subnetwork에 이어 Siamse-RPN을 SGD를 이용하여 end-to-end 방식으로 학습
- tracking의 객체는 연속된 프레임에서 변화가 크지 않아 detection에 비해 적은 anchor를 사용한다.
따라서, [0.33, 0.5, 1, 2, 3] 중 하나의 scale을 골라 사용한다. - ground truth와의 IOU가 0.6보다 크면 Positive로, 0.3보다 작으면 Negative로 분류된다.
Inference phase: Perform one-shot detection
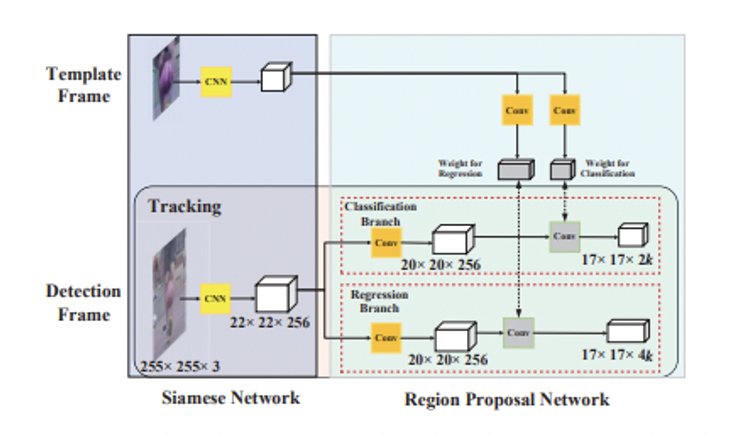
- Inference phase에서 첫번째 프레임의 template이 고정적으로 사용된다.
- 이 template 의 feature map이 RPN에서 커널로 사용되면서 파라미터 의 역할을 하게 되는데 학습을 위해 학습 되었기 때문에 meta learner라 부른다.
- template branch에는 tracking 하고자 하는 객체의 정보가 임베딩 되어있어 프레임마다 바뀌어 들어오는 Detection branch에서 그 객체를 찾는 방식이므로 one-shot detection의 형태를 띄게 된다.
Proposal selection
one-shot detection이 tracking task에 맞도록 proposal을 고를 때 두가지 기법이 적용되었다.
- 중심에서 멀리 떨어진 anchor로부터 만들어진 bouding box들은 제외시킨다.
- proposal의 score rank를 재배열하여 가장 적합한 것을 찾기 위해 cosine window와 scale change penalty를 적용한다.
- penalty =
- 는 padding,
- '은 이전 프레임을 의미
이후 NMS(Nom-maximum-sumppression)을 통해 최종 bouding box를 선택하며, linear interpolation을 통해 target 사이즈를 업데이트 한다.
