1. AWS Redshift란?
-
AWS가 서비스하는 클라우드 데이터웨어하우스 DB입니다.
-
2012년에 베타서비스를 시작하여 2015년에 정식 서비스를 시작하였지만 뛰어난 기능으로 많은 기업들이 사용하고 있습니다.
-
온프레미스에서 쿼리툴을 통해 레드프레스에 쿼리를 날리면, 레드프레스는 데이터를 분석, 가공해 기업에게 필요한 정보로 리턴해줍니다. -
클러스터(노드집합)를 생성하고, 클러스터가 사용할 준비가 되면(프로비저닝 완료) 데이터 적재 및 분석가능하고 PostgreSQL을 기반으로 해서 표준 SQL을 이용한 데이터처리를 지원하고, BI도구로 분석할 수 있다.
온프레미스(On-premise)란?
- 기업의 서버를 클라우드 같은 원격 환경에서 운영하는 방식이 아닌, 자체적으로 보유한 전산실 서버에 직접 설치해 운영하는 방식을 의미합니다.
- 온프레미스는 클라우드 컴퓨팅 기술이 나오기 전까지 기업 인프라 구축의 일반적인 방식이었습니다.
- 장점 : 기업의 비즈니스 정보를 보안성 높게 관리할 수 있다.
- 단점 : 시스템을 구축하는데 있어서 많은 시간과 많은 비용이 들어간다.
-> 기업에서 보안성 높은 데이터는 온프레미스 환경에서, 보안성 낮은 데이터는 클라우드 환경을 사용하는 하이브리드 IT 인프라가 등장했습니다.
2. AWS Redshift 구성요소
-
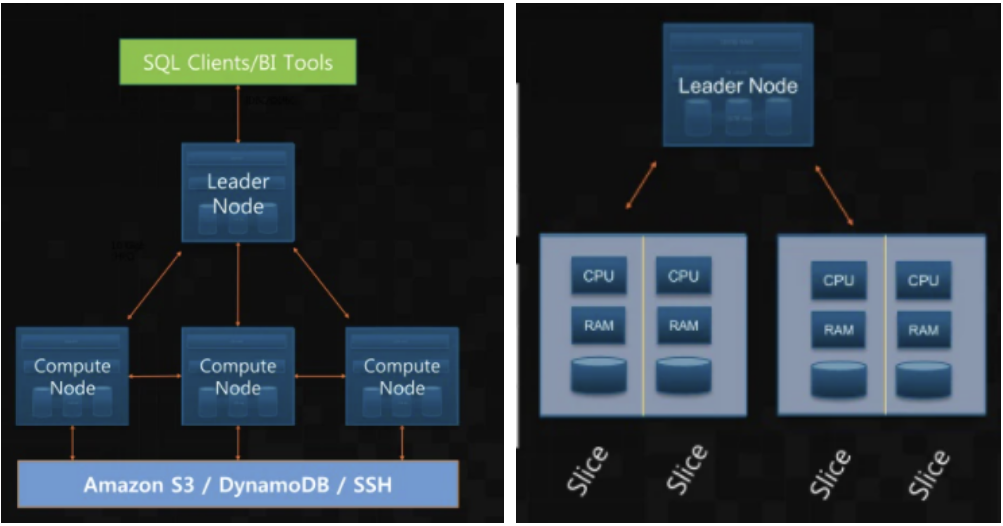
클러스터(Cluster) : 리더노드와 하나이상의 컴퓨팅 노드로 구성되어 있다.
-
리더노드(Leader Node) : SQL연결 엔드포인트, 외부 어플리케이션은 리더노드와 통신, 노드간의 통신을 관리하는 노드로 메타데이터를 저장하고, 클러스터의 모든 쿼리 수행을 관리한다.
-
컴퓨팅 노드(Compute Node) : 실제 작업을 수행하는 노드로 각 노드마다 여러개의 슬라이스를 보유하고 있다. 병렬로 쿼리를 수행하고, S3기반으로 백업 및 복구를 수행할 수 있다.
-
슬라이스(Slices) : 각 노드는 여러개의 슬라이스로 구성되어 있다. 그 슬라이스는 별도의 메모리, cpu, 디스크공간이 할당되어 있다. 슬라이스별로 독립적인 워크로드를 병렬적으로 실행한다.
3. Redshift 특징
1. 대용량병렬처리(Massive Parallel Processing, MPP)
-
분산형(MPP)시스템
-
클러스터는 리더노드(Leader Node)와 컴퓨팅 노드(Compute Node)로 구성되어 있고, 컴퓨팅 노드(Compute Node)는 하나이상의 Slices로 구성되어 있다. 그리고 Slices에 데이터를 포함한다.
-
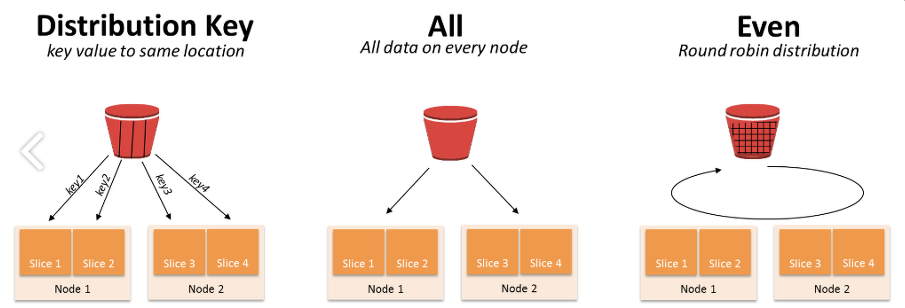
데이터를 병렬로 처리할 수 있도록 테이블의 행을 계산노드에 배포하고, 각 테이블마다 분산키를 선택하거나, All이나 Even방식 중 하나의 방법으로 슬라이스를 선택한다. 그리고 쿼리들은 모든 슬라이스들에 걸쳐 병렬수행을 한다.
-
DISTKEY(Distribution key)
- 명시적으로 지정한 컬럼을 기준으로 각 레코드의 슬라이스 배치가 결정됨
- 컬럼 카디널리티에 따라 슬라이스간 상당한 편차가 발생 가능함
- ex) 여러 테이블에서 조인의 대상이 되는 경우 DISTKEY로 분산
-
ALL
- 모든 레코드가 각 컴퓨팅 노드에 동일하게 복제함
- ex) 작은 테이블은 ALL(마스터 테이블)
-
EVEN
- 각 레코드가 슬라이스에 라운드로빈 방식으로 분산, 균등하게 데이터 저장
->라운드로빈(Round Robin Scheduling, RR) : 시분할 시스템을 위해 설계된 선점형 스케줄링의 하나로서, 프로세스들 사이에 우선순위를 두지 않고, 순서대로 시간단위(Time Quantum)로 CPU를 할당하는 방식의 CPU 스케줄링 알고리즘이다. - ex) 조인을 자주하지 않고 비정규화 된 테이블을 EVEN으로 분산함
- 각 레코드가 슬라이스에 라운드로빈 방식으로 분산, 균등하게 데이터 저장
2. 컬럼기반 데이터스토리 : Columnar data storage
-
데이터베이스에 저장하는 테이블 정보를 행기반이 아닌 컬럼(열)기반으로 저장한다.
-
컬럼으로 압축함으로써 데이터를 읽는 크기를 줄여 디스크 io를 줄이고, 쿼리성능을 향상시킬 수 있다.
-
압축기능의 자동적용을 위해 copy명령으로 redshift로 데이터를 로딩하면서 데이터분석할 수 있게 압축수행
4. Redshift vs 기존DW : 클라우드 vs 온프레미스
1. 확장성
- 기존 dw는 온프레미스 시스템이라 사전에 할당된 리소스만 사용해야해서 확장하기 어려움 -> redshift는 클라우드기반이라 확장성이 뛰어남
2. 데이터집합적
- 기존 dw는 데이터가 여러장소에 분산되어 있어서 어떤 데이터가 원본인지 알기 어려움 -> 반면 redshift는 모든 데이터를 s3하나에 저장
3. 가격
- 기존 dw는 개발비용이 비싼데, redshift는 온디맨드 요금으로 사용하는만큼 비용부과
4. 다양한 데이터
-
기존 dw는 정형화된 데이터만 분석할 수 있음
-
반면 레드시프트는 정형데이터 뿐만 아니라 반정형, 비정형 데이터도 가능
-
raw data를 그대로 저장하고, redshift가 분석할때 필요한 형태로 가공한다
5. Redshift vs RDS : OLAP vs OLTP
-
OLAP(온라인 분석 처리) : 대규모 비즈니스 데이터베이스를 구성하고 복잡한 분석을 지원하는 기술입니다. 트랜잭션 시스템에 부정적인 영향을 주지 않고 복잡한 분석 쿼리를 수행하는 데 사용할 수 있습니다. -
OLTP(온라인 트랜잭션 처리) : 컴퓨터 시스템을 사용하는 트랜잭션 데이터 관리라고 합니다. OLTP 시스템은 조직의 일상적인 작업에서 발생하는 비즈니스 상호 작용을 기록하고, 이 데이터를 쿼리하여 유추할 수 있도록 지원합니다. -
redshif는 OLAP, 일반 RDS는 OLTP 워크로드에 사용한다.
-
RDS는 주로 서비스운영에 활용되는 db로 row단위의 update와 insert를 같이 단지 트랜잭션을 수행하는데 목표
-
반면 redshift는 DW이기 때문에 일반 RDS보단 대용량 데이터를 가지고 있고 복잡한 쿼리로 데이터를 분석하는 목표
6. Redshift vs EMR vs Athena : 사용목적
-
EMR(Elastic MapReduce) : AWS에 제공해주는 완전관리형 빅데이터 플랫폼, 하둡(MapReduce), Spark, Hive, Zeppelin등 오픈소스 프레임워크를 가지고 클러스터를 쉽게 구축해주는 서비스이다. -
반면 Redshift는 이미 정제하고 적재된 데이터를 이용하여 분석하는 데이터웨어하우스
-
Athena : s3에서 표준 SQL을 사용하여 데이터를 쉽게 바로 분석할 수 있는 대화형쿼리서비스, s3데이터에 Glue스키마만 생성해주고, 간편하게 EDA(Exploratory Data Analysis, 수집한 데이터가 들어왔을 때 이를 다양한 각도에서 관찰하고 이해하는 과정) 목적으로 사용 -
반면 Redshift는 복잡한 쿼리를 빨리 수행해야하거나 정기적인 배치처리가 필요한 경우 사용
