Thread
프로세스 : 컴퓨터에서 연속적으로 실행되고 있는 컴퓨터 프로그램스레드 : 어떠한 프로그램 내에서, 특히 프로세스 내에서 실행되는 흐름의 단위, 일반적으로 한 프로그램은 하나의 스레드를 가지고 있지만, 프로그램 환경에 따라 둘 이상의 스레드를 동시에 실행할 수 있다.
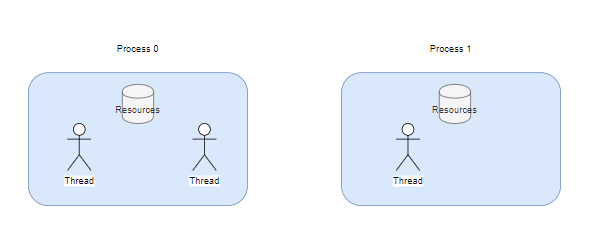
- 운영체제에서 어떤 프로그램이 실행된다는 것은 CPU, 메모리, SSD와 같은 컴퓨터 자원을 사용합니다.
- 따라서 운영체제는 프로그램이 마음껏 실행될 수 있도록 전용 '놀이터'와 같은 공간을 제공해주는데 이를
프로세스라고 합니다.
- 놀이터에는 응용 프로그램이 놀 수 있습니다. 운영체제 입장에서 놀이터에 있는 플레이어를 스레드라고 부릅니다.
- 어떤 응용 프로그램은 한 번에 여러 가지 작업을 수행해야 하는 경우도 있습니다. 이 경우 동일한 프로세스 안의 두 스레드는 모든 컴퓨터 자원을 공유합니다.
import threading
import time
class Worker(threading.Thread):
def __init__(self, name):
super().__init__()
self.name = name
def run(self):
print("sub thread start ", threading.current_thread().getName())
time.sleep(3)
print("sub thread end ", threading.current_thread().getName())
print("main thread start")
for i in range(5):
name = "thread {}".format(i)
t = Worker(name)
t.start()
print("main thread end")
- 메인 스레드와 5개의 서브 스레드는 운영체제의 스케줄러에 의해 스케줄링 되면서 실행됩니다. 가장 먼저 메인 스레드가 끝나고 서브 스레드들은 0,1,2,3,4 순으로 실행됐지만 종료 순서는 조금 다른 것을 확인할 수 있습니다.
- 기본적으로 메인 스레드에서 서브 스레드를 생성하면 메인 스레드는 자신의 작업을 모두 마쳤더라도 서브 스레드의 작업이 종료될 때까지 기다렸다가 서브 스레드의 작업이 모두 완료되면 종료됩니다.
class Worker(threading.Thread):
def __init__(self, name):
super().__init__()
self.name = name
def run(self):
print("sub thread start ", threading.currentThread().getName())
time.sleep(3)
print("sub thread end ", threading.currentThread().getName())
print("main thread start")
for i in range(5):
name = "thread {}".format(i)
t = Worker(name)
t.daemon = True
t.start()
print("main thread end")
데몬(daemon) 스레드 : 메인 스레드가 종료될 때 자신의 실행 상태와 상관없이 종료되는 서브 스레드- ex) 파일 다운로드 프로그램에서 서브 스레드를 통해 파일을 동시에 다운로드 받고 있을 때 사용자가 메인 프로그램을 종료하면 파일의 다운로드 완료 여부와 상관없이 프로그램이 종료되어야 한다.
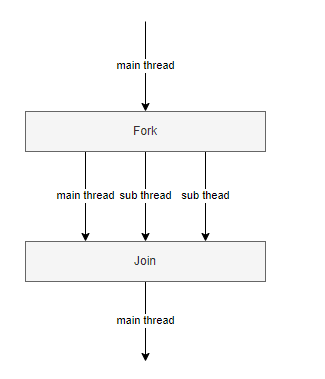
fork : 메인 스레드가 서브 스레드를 생성하는 것join : 모든 스레드가 작업을 마칠 때까지 기다리는 것
import threading
import time
class Worker(threading.Thread):
def __init__(self, name):
super().__init__()
self.name = name
def run(self):
print("sub thread start ", threading.currentThread().getName())
time.sleep(5)
print("sub thread end ", threading.currentThread().getName())
print("main thread start")
t1 = Worker("1")
t1.start()
t2 = Worker("2")
t2.start()
t1.join()
t2.join()
print("main thread post job")
print("main thread end")
- 앞의 예에서는 메인스레드가 모든 실행을 완료한 후 서브 스레드가 종료될 때까지 기다렸지만 이 예제에서는 join()메서드가 호출되는 지점에서 기다린다는 차이가 있습니다.
import time
import threading
class Worker(threading.Thread):
def __init__(self, name):
super().__init__()
self.name = name
def run(self):
print("sub thread start ", threading.currentThread().getName())
time.sleep(5)
print("sub thread end ", threading.currentThread().getName())
print("main thread start")
threads = []
for i in range(3):
thread = Worker(i)
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
print("main thread post job")
print("main thread end")
import time
if __name__ == "__main__":
increased_num = 0
start_time = time.time()
for i in range(100000000):
increased_num += 1
print("--- %s seconds ---" % (time.time() - start_time))
print("increased_num=", end=""), print(increased_num)
print("end of main")
import threading
import time
shared_number = 0
def thread_1(number):
global shared_number
print("number = ",end=""), print(number)
for i in range(number):
shared_number += 1
def thread_2(number):
global shared_number
print("number = ",end=""), print(number)
for i in range(number):
shared_number += 1
if __name__ == "__main__":
threads = [ ]
start_time = time.time()
t1 = threading.Thread( target= thread_1, args=(50000000,) )
t1.start()
threads.append(t1)
t2 = threading.Thread( target= thread_2, args=(50000000,) )
t2.start()
threads.append(t2)
for t in threads:
t.join()
print("--- %s seconds ---" % (time.time() - start_time))
print("shared_number=",end=""), print(shared_number)
print("end of main")
- 하나의 쓰레드에서 천만까지 증가시키는 코드를 두 개의 쓰레드로 분리해서 오백만씩 증가시켰으나 속도가 반으로 줄지도 않았고 최종 증가된 숫자는 천만이 안되었습니다.
- 스레드는 완전 동시에 로직을 처리하지 않습니다. 조금씩 차이가 발생합니다.
- t1 스레드가 shared_number 변수를 읽고 t2 스레드가 결과 값을 shared_number에 저장하면 t1 스레드가 작업을 완료했을 때 t2 스레드의 작업 내용을 덮어 쓰게 됩니다.
해결 방법
- 스레드 간에 공유하는 자원을 없애고 각 스레드 별 고유의 자원을 할당 한 후에 마지막으로 합치는 과정을 수행한다.
- 스레드가 공유하는 자원에 대해서 접근할 때 해당 자원이 사용중인지 아닌지에 따라서 한 스레드만 접근이 가능하게 만든다. ->
임계 영역의 동시 접근을 막는 것, 동기화
동기화
- '일치한다'는 의미에서의 동기화가 아닌, 순서에 의해서 질서가 지켜지고 있음을 의미한다.
메모리 접근에 대한 동기화
- 메모리 접근에 있어서 동시접근을 막는 것
- 한 순간에 하나의 쓰레드에만 접근해야 하는 메모리 영역이 존재한다. (데이터 영역, 힙 영역)
- 메모리 공간 종류
- 코드(code) 영역 : 프로그램의 코드가 저장되는 영역
- 데이터(data) 영역 : 프로그램의 전역 변수와 정적 변수가 저장되는 영역
- 스택(stack) 영역 : 함수의 호출과 관계되는 지역 변수와 매개변수가 저장되는 영역
- 힙(heap) 영역 : 사용자가 직접 관리할 수 있는 메모리 영역
임계 영역
- 각각의 프로세스 또는 스레드 등의 접근 단위가 동시에 접근하면 안되는 공유 영역, 임계 구역이 아닌 부분은 나머지 구역(Remainder Section)이라고 부름
스레드 동기화 방법
유저 모드 동기화 (커널 코드 실행 x)
- 크리티컬 섹션(Critical Section) 기반의 동기화
- 인터락 함수(Interlocked Family Of Function) 기반의 동기화
커널 모드 동기화
- 뮤텍스(Mutex) 기반의 동기화 -> (Mutual Exclusion)의 약자, 공유 자원에 여러 쓰레드가 접근하는 것을 막는 것 (오직 1개의 프로세스 혹은 스레드만이 공유 자원에 접근 가능)
- 세마포어(Semaphore) 기반의 동기화 -> 공유 자원에 여러 프로세스가 접근하는 것을 막는 것 (지정된 변수의 값만큼 접근 가능)
- 이름있는 뮤텍스(Named Mutex) 기반의 동기화 -> 프로세스 간 동기화
- 이벤트(Event) 기반의 동기화 -> 실행순서 동기화
import threading
import time
t1_number = 0
t2_number = 0
def thread_1(number):
global t1_number
print("number = {}".format(number))
for i in range(number):
t1_number += 1
def thread_2(number):
global t2_number
print("number = {}".format(number))
for i in range(number):
t2_number += 1
if __name__ == "__main__":
threads = [ ]
start_time = time.time()
t1 = threading.Thread( target= thread_1, args=(50000000,) )
t1.start()
threads.append(t1)
t2 = threading.Thread( target= thread_2, args=(50000000,) )
t2.start()
threads.append(t2)
for t in threads:
t.join()
print("--- %s seconds ---" % (time.time() - start_time))
print("result number = {}".format(t1_number + t2_number))
print("end of main")
import threading
import time
shared_number = 0
lock = threading.Lock()
def thread_1(number):
global shared_number
print("number = {}".format(number))
for i in range(number):
lock.acquire()
shared_number += 1
lock.release()
def thread_2(number):
global shared_number
print("number = {}".format(number))
for i in range(number):
lock.acquire()
shared_number += 1
lock.release()
if __name__ == "__main__":
threads = [ ]
start_time = time.time()
t1 = threading.Thread( target= thread_1, args=(50000000,) )
t1.start()
threads.append(t1)
t2 = threading.Thread( target= thread_2, args=(50000000,) )
t2.start()
threads.append(t2)
for t in threads:
t.join()
print("--- %s seconds ---" % (time.time() - start_time))
print("shared_number=",end=""), print(shared_number)
print("end of main")
- 뮤텍스를 적용하는 방법이 무조건 좋은 결과를 내진 않는다.
- 보다 효율적인 설계와 데이터 흐름을 확정한 후 그에 맞는 스레드 구조와 뮤텍스를 사용해야만 의미있는 성능의 향상을 기대할 수 있다.
