이번에 여러 대외활동을 하면서 느낀점이 있다면 바로 데이터 구조에 대한 기본이 무조건 필요하다는 것이다. SKT Devocean 활동을 하면서 현직에 계신 마스터분들도 데이터 구조 수업은 정말 집중해서 들어야하고 꼭 알고 있어야 한다고 강조를 하셨다.
학교에서도 '데이터 구조론' 이라는 수업이 있다. 물론 전공필수라 난 수강을 했다. 그런데 점수가 다른 과목에 비해 좋지 않았다. 수업을 C++ 언어로 진행을 하는데 내가 C 계열의 언어를 별로 좋아하지도 않고 수업이 거의 영어로 진행되어 정신이 안드로메다에 있을때가 많았다.
그래서 지금이라도 부랴부랴 데이터 구조에 대한 공부를 다시 해보려고 한다.
첫 번째로 정렬(sorting) 알고리즘에 대한 공부를 진행할 계획이다.
1. 정렬(sorting) 알고리즘이란?
데이터 정렬은 왜 하는 것일까? 데이터를 정렬해야 하는 이유는 탐색을 위해서이다. 사람은 수십에서 수백 개의 데이터를 다루는 데 그치지만 컴퓨터가 다뤄야 할 데이터는 보통이 백만 개 단위이며 데이터베이스 같은 경우 이론상 무한 개의 데이터를 다룰 수 있어야 한다. 탐색한 대상 데이터가 정렬되어 있지 않다면 순차 탐색 이외에 다른 알고리즘을 사용할 수 없지만 데이터가 정렬되어 있다면 이진 탐색이라는 강력한 알고리즘을 사용할 수 있다.
소프트웨어의 일을 아주 단순하게 표현하자면, '데이터를 저장하고 가공해서 사용자에게 보여주는 것'이다. 수많은 데이터 중에서 사용자가 원하는 무언가를 효율적으로 찾아낼 때에도 정렬이 활용된다. 그래서 정보를 다루는 소프트웨어에서 정렬은 거의 숨쉬기다. 자주 실행되는 가장 기본적인 작업이라는 뜻이다. 그러다보니 정렬 알고리즘을 잘 만드는 것은 컴퓨터 공학에서 아주아주 중요한 주제가 되었다.
2. 버블 정렬(Bubble Sort)

버블 정렬을 움직임으로 보여주는 gif다.
버블 정렬(Bubble Sort)이란 첫 번째 자료와 두 번째 자료를, 두 번째 자료와 세 번째 자료를, 세 번째 자료와 네 번째를, ... 이런식으로 (마지막-1)번째 자료와 마지막 자료를 비교하여 교환하면서 자료를 정렬한다.
1회전을 수행하고 나면 가장 큰 자료가 맨 뒤로 이동하므로 2회전에서는 맨 끝에 있는 자료는 정렬에서 제외되고, 2회전을 수행하고 나면 끝에서 두 번째 자료까지는 정렬에서 제외된다. 이렇게 정렬을 1회전 수행할 때마다 정렬에서 제외되는 데이터가 하나씩 늘어난다.
버블 정렬(bubble sort) 알고리즘의 예제를 통해 같이 알아보자.
배열에 7, 4, 5, 1, 3이 저장되어 있다고 가정하고 자료를 오름차순으로 정렬해보자.
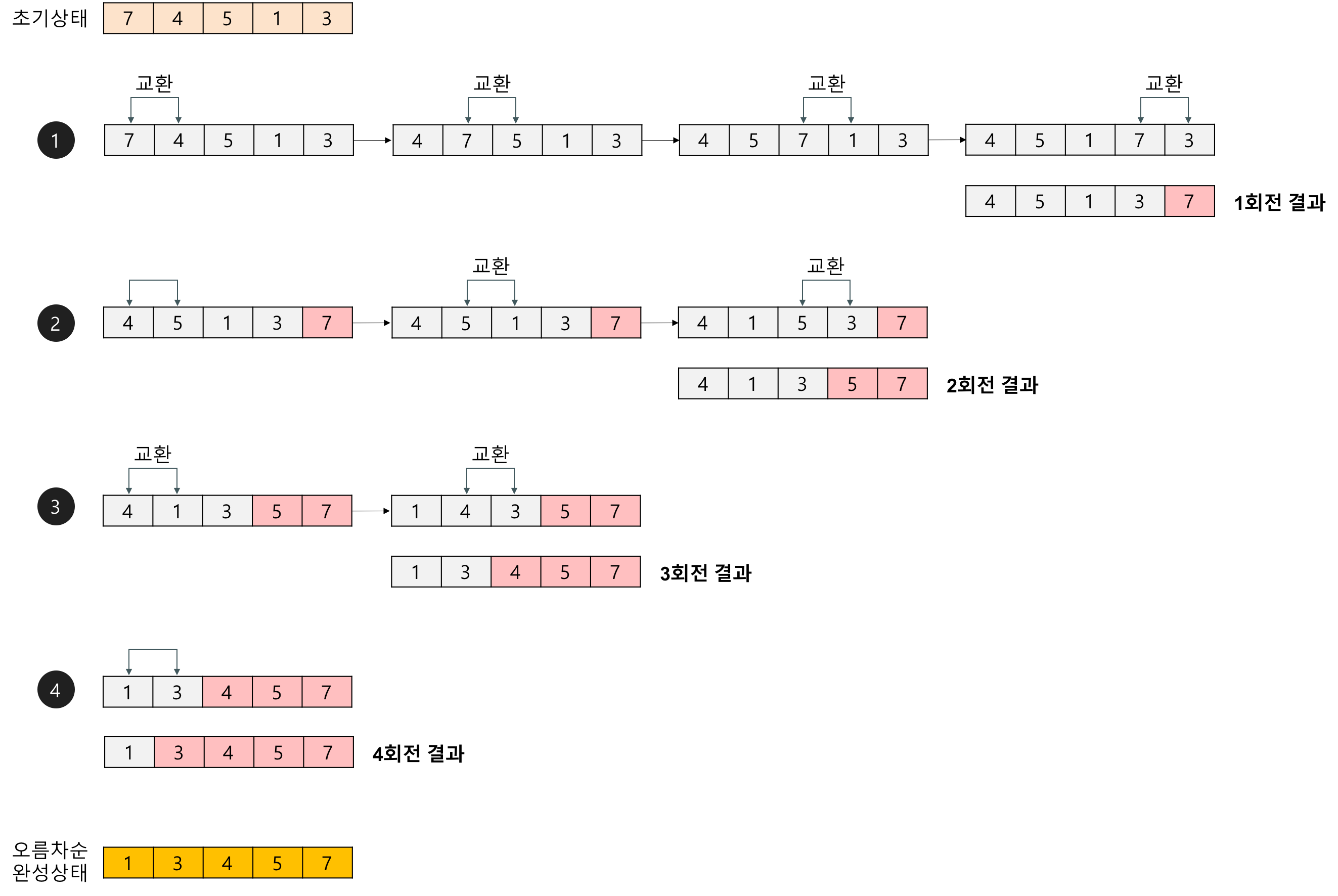
- 1회전
첫 번째 자료 7을 두 번째 자료 4와 비교하여 교환하고, 두 번째 7과 세 번째의 5를 비교하여 교환하고, 세 번째의 7과 네 번째의 1을 비교하여 교환하고, 네 번째의 7과 다섯 번째의 3을 비교하여 교환한다. 이 과정에서 자료를 네 번 비교한다. 그리고 가장 큰 자료가 맨 끝으로 이동하므로 다음 회전에서는 맨 끝에 있는 자료는 비교할 필요가 없다.
- 2회전
첫 번째의 4를 두 번째 5와 비교하여 교환하지 않고, 두 번째의 5와 세 번째의 1을 비교하여 교환하고, 세 번째의 5와 네 번째의 3을 비교하여 교환한다. 이 과정에서 자료를 세 번 비교한다. 비교한 자료 중 가장 큰 자료가 끝에서 두 번째에 놓인다.
- 3회전
첫 번째의 4를 두 번째 1과 비교화여 교환하고, 두 번째의 4와 세 번째의 3을 비교하여 교환한다. 이 과정에서 자료를 두 번 비교한다. 바교한 자료 중 가장 큰 자료가 끝에서 세 번째에 놓인다.
- 4회전
첫 번째의 1과 두 번째의 3을 비교하여 교환하지 않는다.
버블 정렬(bubble sort) 을 c 언어 코드로 표현해보자.
# include <Stdio.h>
# define MAX_SIZE 5
//버블 정렬
void bubble_sort(int list[], int n){
int i, j, temp;
for(i=n-1; i>0; i--){
//0~(i-1)까지 반복
for(j=0; j<i; j++){
//j번째와 j+1번째의 요소가 크기 순이 아니면 교환
if(list[j]<list[j+i]){
temp = list[j];
list = list[j+1];
list[j+1] = temp;
}
}
}
}
void main(){
int i;
int n = MAX_SIZE;
int list[n] = {7, 4, 5, 1, 3};
//버블 정렬 수행
bubble_sort(list, n);
//정렬 결과 출력
for(i=0; i<n; i++){
printf("%d\n", list[i]);
}
}버블 정렬(bubble sort) 알고리즘의 특징
장점
- 구현이 매우 간단하다.
단점
- 순서를 맞지 않은 요소를 인접한 요소와 교환한다.
- 하나의 요소가 가장 왼쪽에서 가장 오른쪽으로 이동하기 위해서는 배열에서 모든 다른 요소들과 교환되어야 한다.
- 특히 특정 요소가 최종 정렬 위치에 이미 있는 경우라도 교환되는 일이 일어난다.
일반적으로 자료의 교환 작업(SWAP)이 자료의 이동 작업(MOVE)보다 더 복잡하기 때문에 버블 정렬은 단순성에도 불구하도 거의 쓰이지 않는다.
3. 선택 정렬(Selection Sort)

선택 정렬을 실행했을 때 나오는 그림이다.
선택 정렬은 첫 번째 자료를 두 번째 자료부터 마지막 자료까지 차례대로 비교하여 가장 작은 값을 찾아 첫 번째에 놓고, 두 번째 자료를 세 번째 자료부터 마지막 자료까지와 차례대로 비교하여 그 중 가장 작은 값을 찾아 두 번째 위치에 놓는 과정을 반복하여 정렬을 수행한다.
1회전을 수행하고 나면 가장 작은 값의 자료가 맨 앞에 오게 되므로 그 다음 회전에서는 두 번째 자료를 가지고 비교한다. 마찬가지로 3회전에서는 세 번째 자료를 정렬한다.
선택 정렬(Selection Sort) 알고리즘의 예제를 통해 이해를 하자.
배열에 9, 6, 7, 3, 5가 저장되어 있다고 가정하고 자료를 오름차순으로 정렬해 보자.
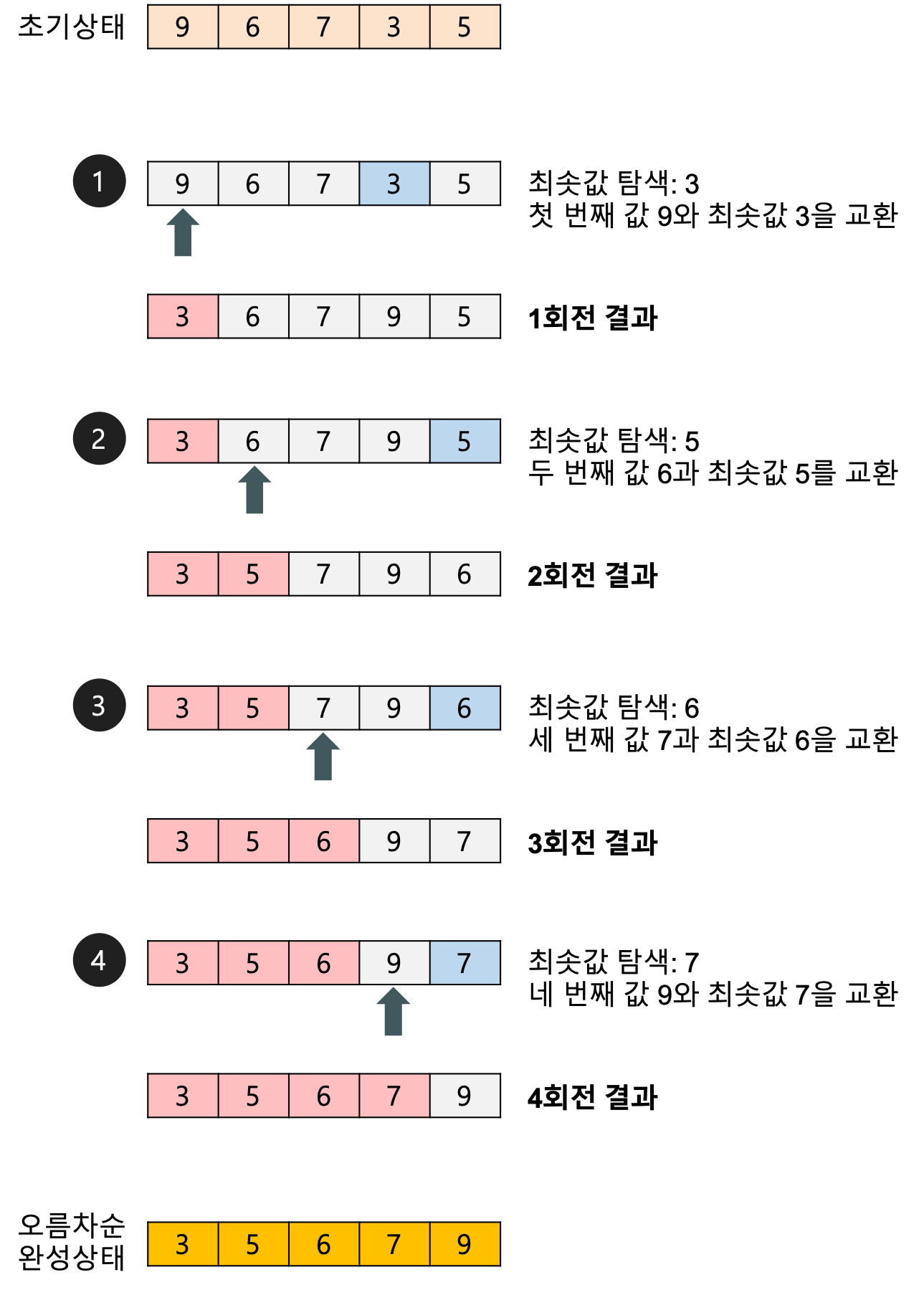
- 1회전
첫 번째 자료 9를 두 번째 자료부터 마지막 자료까지와 비교하여 가장 작은 값을 첫 번째 위치에 옮겨 놓는다.
- 2회전
두 번째 자료 6을 세 번째 자료부터 마지막 자료까지와 비교하여 가장 작은 값을 두 번째 위치에 옮겨 놓는다.
- 3회전
세 번째 자료 7을 네 번째 자료부터 마지막 자료까지와 비교하여 가장 작은 값을 세 번째 위체에 옮겨 놓는다.
- 4회전
네 번째 자료 9와 마지막에 있는 7을 비교하여 서로 교환한다.
선택 정렬(Selection Sort)을 C 언어 코드로 표현해보자.
#include <stdio.h>
#define SWAP(x, y, temp) ((temp)=(x), (x)=(y), (y)=(temp))
#define MAX_SIZE 5
//선택 정렬
void selection_sort(int list[], int n){
int i, j, least, temp;
//마지막 숫자는 자동으로 정렬되기 때문에 (숫자 개수-1) 만큼 반복한다.
for(i=0; i<n-1; i++){
least = i;
//최솟값을 탐색한다.
for(j=i+1; j<n; j++){
if(list[j]<list[least])
least = j;
}
//최솟값이 자기 자신이면 자료 이동을 하지 않는다.
if(i != least){
SWAP(list[i], list[least], temp);
}
}
}
int main(){
int i;
int n = MAX_SIZE;
int list[] = {9, 6, 7, 3, 5};
selection_sort(list, n);
for(i=0; i<n; i++){
printf("%d\n", list[i]);
}
}선택 정렬(Selection Sort) 알고리즘의 특징을 알아보자
장점
- 자료 이동 횟수가 미리 결정된다.
단점
- 안정성을 만족하지 않는다.
- 즉, 값이 같은 레코드가 있는 경우에 상대적인 위치가 변경될 수 있다.
4. 삽입 정렬(Insertion Sort)
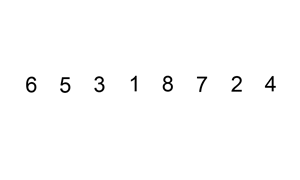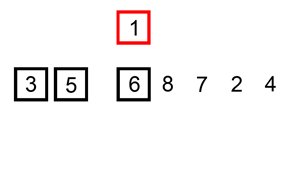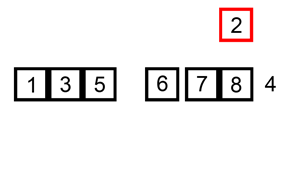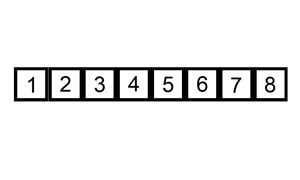
삽입 정렬(Insertion Sort)이란 두 번째 자료부터 시작하여 그 앞의 자료들과 비교하여 삽입할 위치를 지정한 후 자료를 뒤로 옮기고 지정한 자리에 자료를 삽입하여 정렬하는 알고리즘이다.
즉, 두 번째 자료는 첫 번째 자료, 세 번째 자료는 두 번째와 첫 번째 자료, 네 번째 자료는 세 번째, 두 번째, 첫 번째 자료와 바교한 후 자료가 삽입될 위치를 찾는다. 자료가 삽입될 위치를 찾았다면 그 위치에 자료를 삽입하기 위해 자료를 한 칸씩 뒤로 이동시킨다.
처음 Key 값은 두 번째 자료부터 시작한다.
삽입 정렬(Insertion Sort) 알고리즘의 예제를 살펴보자.
배열에 8, 5, 6, 2, 4가 저장되어 있다고 가정하고 자료를 오름차순으로 정렬해 보자.

- 1회전: 두 번째 자료인 5를 Key로 해서 그 이전의 자료들과 비교한다.
Key 값 5와 첫 번째 자료인 8을 비교한다. 8이 5보다 크므로 8을 5자리에 넣고 Key 값 5를 8의 자리인 첫 번째에 기억시킨다.
- 2회전: 세 번째 자료인 6을 Key 값으로 해서 그 이전의 자료들과 비교한다.
Key값 6과 두 번째 자료인 8을 비교한다. 8이 Key 값보다 크므로 8을 6이 있던 세 번째 자리에 기억시킨다.
Key값 6과 첫 번째 자료인 5를 비교한다. 5가 Key 값보다 작으르모 Key 값 6을 두 번째 자리에 기억시킨다.
- 3회전: 네 번째 자료인 2를 Key 값으로 해서 그 이전의 자료들과 비교한다.
Key값 2와 세 번째 자료인 8을 비교한다. 8이 Key 값보다 크므로 8을 6이 있던 세 번째 자리에 기억시킨다.
Key값 2와 두 번째 자료인 6을 비교한다. 6이 Key 값보다 크므로 6을 세 번째 자리에 기억시킨다.
Key값 2와 첫 번째 자료인 5를 비교한다. 5가 Key 값보다 크므로 5를 두 번째 자리에 넣고 그 자리에 Key 값 2를 기억시킨다.
- 4회전: 다섯 번째 자료인 4를 Key 값으로 해서 그 이전의 자료들과 비교한다.
Key값 4와 네 번째 자료인 8을 비교한다. 8이 Key 값보다 크므로 8을 다섯 번째 자리에 기억시킨다.
Key값 4와 세 번째 자료인 6을 비교한다. 6이 Key 값보다 크므로 6을 네 번째 자리에 기억시킨다.
Key값 4와 두 번째 자료인 5를 비교한다. 5가 Key 값보다 크므로 5를 세 번째 자리에 기억시킨다.
Key값 4와 첫 번째 자료인 2를 비교한다. 2가 Key 값보다 크므로 4를 두 번째 자리에 기억시킨다.
삽입 정렬(Insertion Sort)을 C 언어 코드로 알아보겠다.
#include <stdio.h>
#define MAX_SIZE 5
//삽입정렬
void insertion_sort(int list[], int n){
int i, j, key;
//인덱스 0은 이미 정렬된 것으로 볼 수 있다.
for(i=1; i<n; i++){
key = list[i]; //현제 삽입될 숫자인 i번째 정수를 key 변수로 복사
//현재 정렬된 배열은 i-1까지이므로 i-1번째부터 역순으로 조사한다.
//j 값은 음수가 아니어야 되고
//key 값보다 정렬된 배열에 있는 값이 크면 j번째를 j+1번째로 이동
for(j=i-1; j>=0&& list[j]>key; j--){
list[j+1] = list[j]; //레코드의 오른쪽으로 이동
}
list[j+1] = key;
}
}
void main(){
int i;
int n = MAX_SIZE;
int list[n] = {8, 5, 6, 2, 4};
//삽입 정렬 수행
insertion_sort(list, n);
//정렬 결과 출력
for(i=0; i<n; i++){
printf("%d\n", list[i]);
}
}삽입 정렬(insertion sort) 알고리즘의 특징을 알아보자.
장점
- 안정한 정렬 방법
- 레코드의 수가 적을 경우 알고리즘 자체가 매우 간단하므로 다른 복잡한 정렬 방법보다 유리할 수 있다.
- 대부분의 레코드가 이미 정렬되어 있는 경우에 매우 효율적일 수 있다.
단점
- 비교적 많은 레코드들의 이동을 포함한다.
- 레코드 수가 많고 레코드 크기가 클 경우에 적합하지 않다.
5. 합병 정렬(Merge Sort)
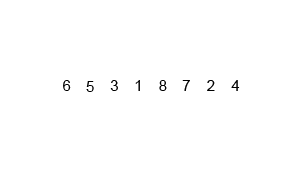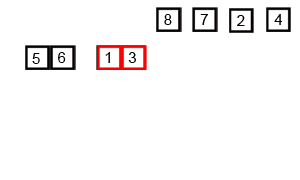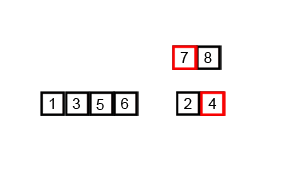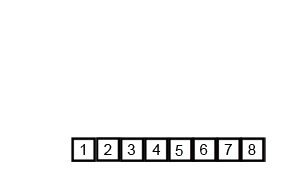
합병 정렬(Merge Sort)은 하나의 리스트를 두 개의 균등한 크기로 분할하고 분할된 부분 리스트를 정렬한 다음, 두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트가 되게 하는 방법이다.
합병 정렬은 다음의 단계들로 이루어진다.
분할(Divide): 입력 배열을 같은 크기의 2개의 부분 배열로 분할한다.
정복(Conquer): 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 순환 호출을 이용하여 다시 분할 정복 방법을 적용한다.
결합(Combine): 정렬된 부분 배열들을 하나의 배열에 합병한다.
합병 정렬(Merge Sort)의 예제를 살펴보자.
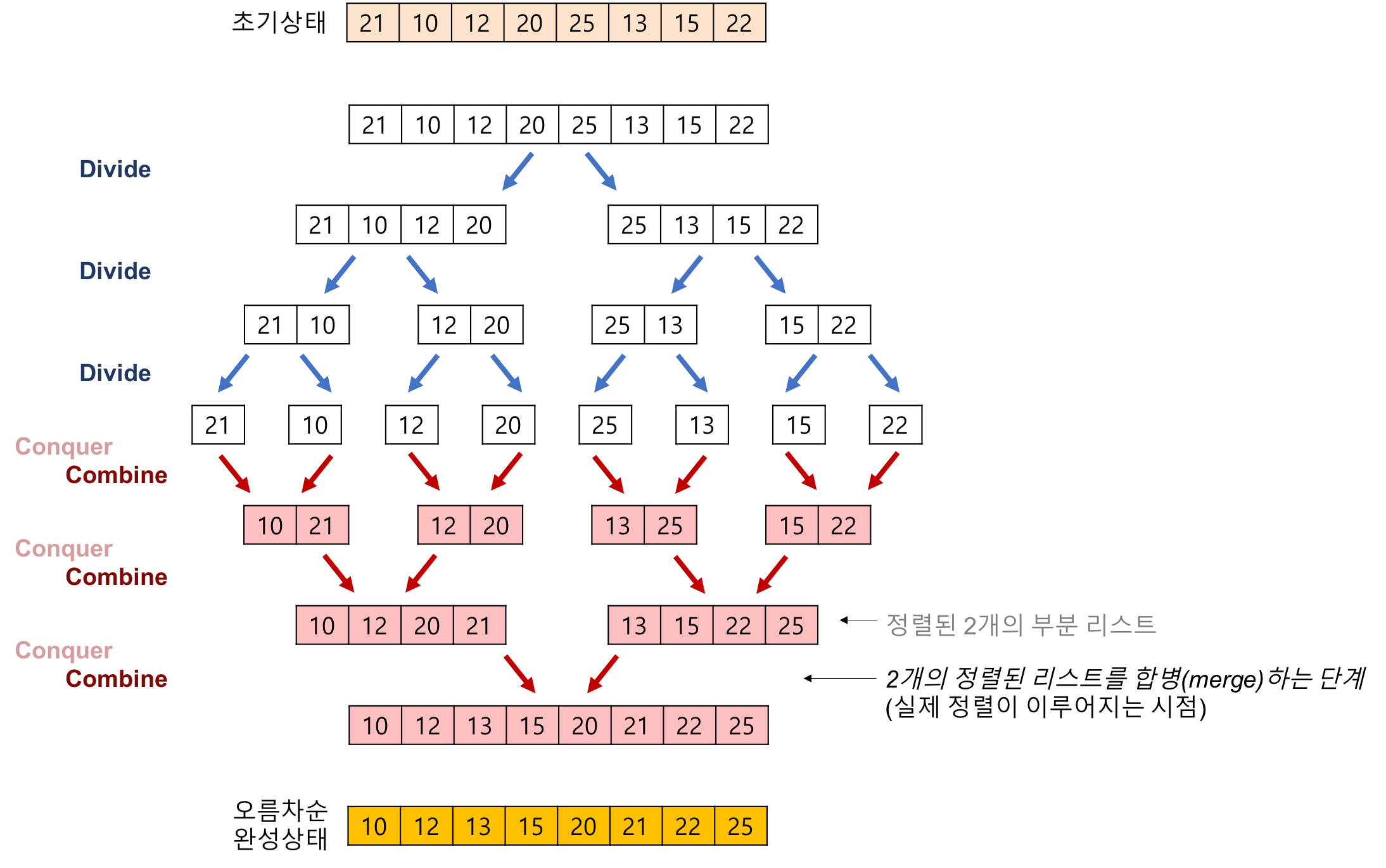
2개의 정렬된 리스트를 합병하는 과정이다.
-
2개의 리스트의 값들을 처음부터 하나씩 비교하여 두 개의 리스트의 값 중에서 더 작은 값을 새로운 리스트로 옮긴다.
-
둘 중에서 하나가 끝날 때까지 이 과정을 되풀이한다.
-
만약 둘 중에서 하나의 리스트가 먼저 끝나게 되면 나머지 리스트의 값들을 전부 새로운 리스트로 복사한다.
-
새로운 리스트를 원래의 리스트로 옮긴다.
합병 정렬(Merge Sort) 알고리즘의 특징은 이렇다.
단점
- 만약 레코드를 배열(Array)로 구성하면, 임시 배열이 필요하다.
- 레코드들의 크기가 큰 경우에는 이동 횟수가 많으므로 매우 큰 시간적 낭비를 초래한다.
장점
- 데이터의 분포에 영향을 덜 받는다. 즉, 입력 데이터가 무엇이든 간에 정렬되는 시간은 동일하다.
- 만약 레코드를 연결 리스트로 구성하면, 링크 인덱스만 변경되므로 데이터의 이동은 무시할 수 있을 정도로 작아진다.
- 따라서 크기가 큰 레코드를 정렬할 경우에 연결 리스트를 사용한다면, 합병 정렬은 퀵 정렬을 포함한 다른 어떤 정렬 방법보다 효율적이다.
