목표
- 자료구조와 함께하는 인덱스에 대해 알아보자
예상 질문
- 인덱스에 대해 아는대로 말해주세요
- 장단점, 사용이유 등등
- 인덱스 자료구조에 대해 말해주세요
INDEX를 왜 사용해야할까?
| 이름 | 태어난 해 |
|---|---|
| 김민섭 | 1999 |
| 나* | 2000 |
| 윤선* | 1996 |
| 이가* | 1999 |
| 이성* | 1996 |
- 몇년생인지 검색하려고 select … where 2000 을 한다고 가정해보자.
- 컴퓨터는 하나씩 다 검색함. 근데 만약 데이터가 1억개, 10억개라면? 굉장히 비효율적임
더 효율적으로 생각해보자
당연하게, 특정범위의 특정 숫자를 찾기 위해 하나씩 찾는것보다, 반씩 잘라가면서 찾는게 효율적이다. 그러면 1부터 100까지의 숫자는 정렬되어있어야 한다.
- 여기에서 Index의 특징인 특정 컬럼의 데이터들을 정렬해서 저장해야한다는 걸 알 수 있다.
| 태어난 해 |
|---|
| 1996 |
| 1996 |
| 1999 |
| 1999 |
| 2000 |
(복사한 컬럼을 정렬해놓은 상태)
데이터를 정렬해서 저장했을 때 당연히 장점들이 따라온다.
- where 조건 검색이 효율적으로된다.
- order by 자원소모를 안해도 된다
- min, max값 연산이 굉장히 간편해짐
관련된 자료구조들에 대해서 알아보자
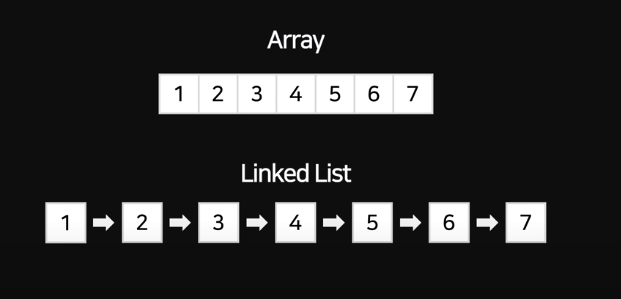
일차적으로 데이터를 저장하는 방법은, array or list를 떠올릴 것이다.
그러나 실제 데이터베이스는 이 형식으로 안하는데, 데이터들을 귀찮게 다 가져와서 일렬로 정렬하는 것 보다 흩뿌려져있는결 화살표로 연결해버리는 방식이 더 효율적이기 때문이다.
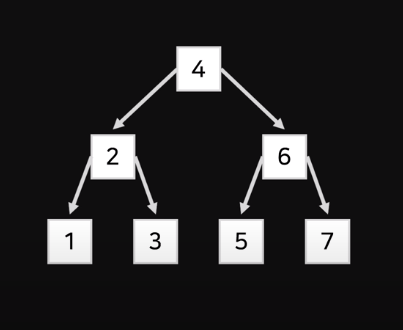
이런식으로 배치해놔도 binary search로 log(n)의 시간복잡도로 특정 데이터를 가져올 수 있다.
실제로 index는 이런식으로 데이터들을 배치하고, 이를 Binary Search Tree라고 한다.
성능을 더 개선시킬 수 없을까?
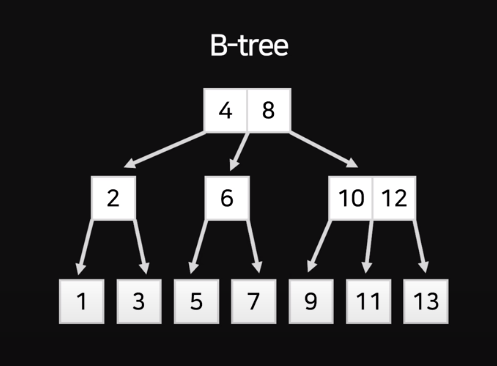
특정 데이터를 기준으로 2개의 자식만을 갖는 Binary Search Tree의 한계를 개선한 B-Tree이다.
Node마다 데이터들을 여러개 넣어버려 절반씩 자르는게 아니라 한번에 1 / 3, 1 / 4씩 잘라가면서 탐색하는 방법이다. 이전엔 2번의 탐색으로 1부터 7을 찾았지만, 이젠 그 이상도 가능하다.
한번 더 개선시킨다.
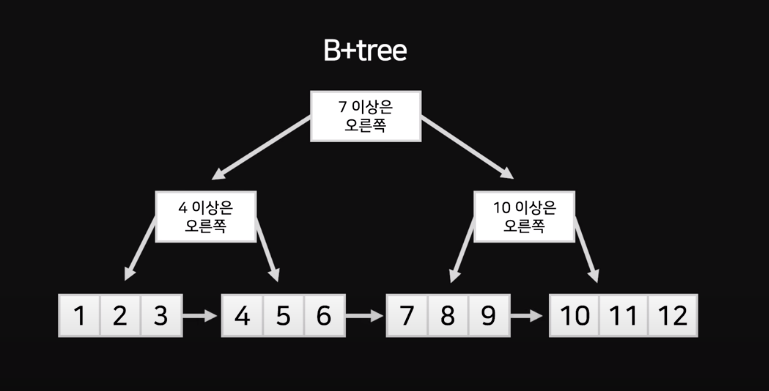
데이터들을 맨 아래에 배치한다. 그 부모 노드들은 가이드만 제공한다.
따라서 동일하게 데이터들을 가이드받아 빠르게 찾아낼 수 있는 건 동일하다. 근데 특이한점은, 맨 아래 노드끼리 연결되어있다.
- 범위 검색이 매우 쉬워진다
Range (4, 8)을 검색하고 싶다고 생각해보자.
- B-Tree의 경우
- 범위의 하한값(4)을 B-Tree에서 검색한다.
- logN으로 찾고, 그 노드와 연결된 리프 노드들을 순회하며 범위에 속하는 값을 찾는다. 이 과정에서 부모 노드를 거칠 경우가 생긴다.
- 범위의 상한값(8)이 나올 때 까지 반복한다.
- B+Tree의 경우
- 범위의 하한값(4)를 B+Tree에서 검색한다.
- 그리고 연결되어 있는 노드들을 통해 상한값을 찾는다.
정리
- 인덱스 없으면 모든 행 다찾음
- 인덱스 있으면 특정 값 빠르게 찾음
- 인덱스와 연결 된 원래 테이블 행 가져와서 처리함
그러면 자연스럽게, 단점이 보일 것이다.
단점
- 컬럼을 복사해서 정렬해두는 개념이기에, 만들때마다 DB 용량을 그만큼 차지하게 된다.
- 무지성 인덱스 만들어두지 마라
- 기존 테이블에 있던거 수정 삭제하면 성능에 문제가 생김
- 이가* 1999인데 빠른 뭐시기 법이 적용되어서 1998로 수정해야한다면 원본 테이블 수정 + 인덱스 사본도 수정해야함

새로운 자극을 주세요.