- 의문1 print(’더하자’)의 순서가 바뀐 경우 왜 안나오는가
def sum(a,b) :
return a+b
print('더하자')
result = sum(1,2)
print(result)
//
3def sum(a,b) :
print('더하자')
return a+b
result = sum(1,2)
print(result)
//
더하자
3- return을 사용하는 경우에는 그것을 통해 다른 값을 사용하기위함
def sum(a,b):
return a+b
sum(1,2)
// 안나옴
--> sum이라는 함수 안에 print가 있다면 나왔을것..
return을 사용하는 경우에는 그 함수를 통해 또 다른 걸 쓰는 경우def sum(a,b):
return a+b
sum(1,2)
def is_adult(age):
if age > 20:
print('성인입니다')
else:
print('청소년입니다')
is_adult(sum(12,10))
//
성인입니다
def is_adult(age):
if age > 20:
print('성인입니다')
else:
print('청소년입니다')
print(is_adult(20))
//
청소년입니다
None
--> print(안에 is_adult(20)값이 결국 성인입니다 라는 텍스트값일것이므로
def is_adult(age):
if age > 20:
print('성인입니다')
else:
print('청소년입니다')
is_adult(20)
//
청소년입니다- 반복문(for문)
fruits = ['사과','배','배','감','수박','귤','딸기','사과','배','수박']
for A in fruits: //fruits를 순서대로 추출한걸 A라고 지칭할게
print(A)
//
사과
배
배
감....
순서대로 다 배치됨
- 갯수 찾는 함수
fruits = ['사과','배','배','감','수박','귤','딸기','사과','배','수박']
count = 0
for aaa in fruits:
if aaa == '사과' :
count +=1 //count=0이므로 사과의 개수만큼 +1씩 해서 갯수 셀수있다.
print(count)
//
2- 딕셔너리형 에서의 if문
people = [{'name': 'bob', 'age': 20},
{'name': 'carry', 'age': 38},
{'name': 'john', 'age': 7},
{'name': 'smith', 'age': 17},
{'name': 'ben', 'age': 27}]
for person in people :
if person['age'] < 30:
print(person['name'])
//
bob
john
smith
benRequests 라이브러리
- API를 불러올 수 있습니다. - 기본틀은 아래와 같다
import requests # requests 라이브러리 설치 필요
r = requests.get('api주소')
rjson = r.json()import requests # requests 라이브러리 설치 필요
r = requests.get('api주소')
rjson = r.json()
rows = rjson['RealtimeCityAir']['row']
for row in rows :
gu_name=row['MSRSTE_NM']
gu_mise=row['IDEX_MVL']
if gu_mise < 20:
print(gu_name)bs4(BeautifulSoup)를 이용한 크롤링 (파이썬아님)
- 기본세팅
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
# 코딩 시작
# 이것을 통해 해당 링크의 html소스를 뽑아올 수 있습니다! # 선택자를 사용하는 방법 (copy selector)
soup.select('태그명')
soup.select('.클래스명')
soup.select('#아이디명') //copy selector사용 시 사용가능
soup.select('상위태그명 > 하위태그명 > 하위태그명')
soup.select('상위태그명.클래스명 > 하위태그명.클래스명')
# 태그와 속성값으로 찾는 방법
soup.select('태그명[속성="값"]')
# 한 개만 가져오고 싶은 경우
soup.select_one('위와 동일')copy selector을 이용해도 되지만 항상 정확하지는 않다고 함
copy selector을 이용할 때에는 경로를 넣어보고 print하면서
어디있는지 찾으면 편하당..^..^
rows = soup.select('#old_content > table > tbody > tr:nth-child(2) > td.title > div > a')
print(rows['href'])
//
[<a href="/movie/bi/mi/basic.naver?code=186114" title="밥정">밥정</a>]
위의 경로였으나, href값을 추출하게 되면 위의 href 값만 추출해준다.
- 활용하자
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
#old_content > table > tbody > tr:nth-child(13) > td.title > div > a
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
list = movie.select_one('td.title > div > a')
if list is not None:
print(list.text)import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
#old_content > table > tbody > tr:nth-child(2) > td.title > div > a
list = soup.select('#old_content > table > tbody > tr')
for movie in list:
movielist = movie.select_one('td.title > div > a')
if movielist is not None:
title = movielist.text
rank = movie.select_one('td:nth-child(1) > img')['alt']
star = movie.select_one('td.point').text
print(rank,title,star)- 실수하는 점
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
#old_content > table > tbody > tr:nth-child(13) > td.title > div > a
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
list = movie.select_one('td.title > div > a')
print(list.text)
왜 이때는안되는가 -> None값에 text가 없어서 안된다고 오류뜸
AttributeError: 'NoneType' object has no attribute 'text'import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
title = soup.select('#old_content > table > tbody > tr:nth-child(2) > td.title > div > a')
print(title[href])Pymongo DB
- mongoDB를 조작하기 위해 필요한 pymongo라이브러리 다운로드
- pymongo 기본코드
from pymongo import MongoClient
client = MongoClient('여기에 URL 입력')
db = client.dbsparta- pymongo 코드요약
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시
all_users = list(db.users.find({},{'_id':False}))-> id값제외
all_users = list(db.users.find({})) 는 조건0
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})- db 찾기
from pymongo import MongoClient
client = MongoClient('url')
db = client.dbsparta
all_users = list(db.users.find({}))
for user in all_users:
print(user)- 실수로 데이터를 두번 넣었을 때
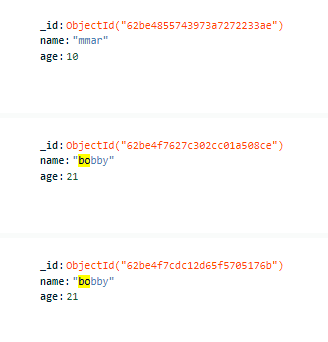
위와같이 두번 들어갔을 경우 delete를 통해 1번 실행시켜주면 먼저 넣었던 데이터값이 사라진다.
list = soup.select('#old_content > table > tbody > tr')
for movie in list:
movielist = movie.select_one('td.title > div > a')
if movielist is not None:
title = movielist.text
rank = movie.select_one('td:nth-child(1) > img')['alt']
star = movie.select_one('td.point').text
doc = { 'title': title, 'rank': rank, 'star':star}
db.movie.insert_one(doc)
//
이렇게 하면 아래만 들어감
_id
:
62be54bf65cfd779bd30dabd
title
:
"클레멘타인"
rank
:
"50"
star
:
"9.37"movie = db.movies.find_one({'title':'가버나움'})
star = movie['star']
all_movies = list(db.movies.find({'star':star},{'_id':False}))
for m in all_movies:
print(m['가버나움'])
//
그린북
가버나움
lovjgb