난이도
실버 3
문제
https://www.acmicpc.net/problem/15649
풀이
N과 M 시리즈는 백트래킹 시리즈이다.
이제 이것을 하나하나 풀어가보려고 한다.
백트래킹이란 어떤 노드의 유망성을 판단한 뒤, 해당 노드가 유망하지 않다면 부모 노드로 돌아가 다른 자식 노드를 찾는 알고리즘이다.
(모든 경우의 수를 찾되, 그중에서 가능성 있는 경우의 수만 찾아보는 방법)
이 문제에 대해,
" a + b + c + d = 20 을 만족하는 두 수를 모두 찾아내시오. ( 0 ≤ a ,b ,c ,d < 100) "
브루트포스의 경우,
a = 1, b = 1, c =1, d = 1 부터 시작하여 a = 100, b = 100, c = 100, d = 100 까지 총 1억개의 경우의 수를 모두 찾아보면서 a + b + c + d = 20 이 만족하는 값을 탐색하는 것이다.
백트래킹은 해당 노드의 유망성을 판단한다. 즉, 해당 범위 내에서 조건을 추가하여 값의 유망성을 판단한다.
하나라도 a = 21 또는 b = 21 또는 c = 21 또는 d = 21 일 경우 20일 가능성이 1 ~ 100 범위 내에서는 절대 불가능하다. 그렇기 때문에 a > 20 이거나 b > 20, c > 20, d > 20 일 경우는 탐색하지 않는다. 그렇게 된다면 탐색하는데 필요한 자원을 많이 줄일 수 있다.
백트래킹은 DFS로 풀 수 있다.
문제 접근
문제에서 n과 m이 주어지고, 중복되는 수를 제외한 모든 경우의 수를 탐색하면 된다. 그럼 기본적으로 재귀를 통해 풀어볼 수 있다.
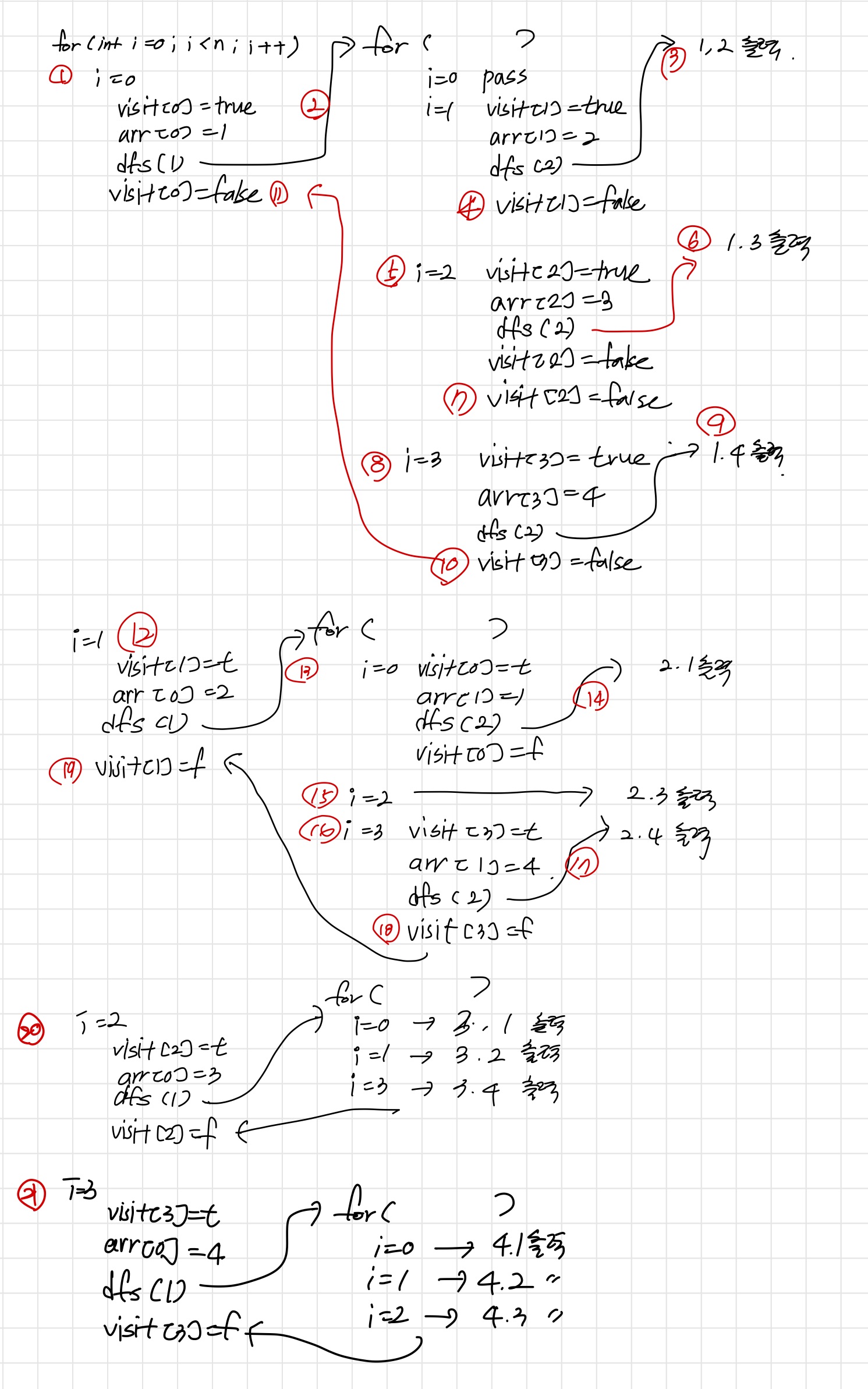
이때, 재귀를 하면서 이미 방문한 노드라면 다음 노드를 탐색하도록 하기 위해(유망한 노드인지 검사하기 위해) n크기의 boolean배열(visit)과 m크기의 탐색 과정에서의 값을 담을 int 배열(arr)을 생성한다.
depth를 통해 재귀가 깊어질 때마다 depth를 1씩 증가시켜 m과 같아지면 더이상 재귀를 호출하지않고 탐색과정 중 값을 담았던 arr 배열을 출력해주고 return하는 역할을 한다.
추가 설명
아래 코드 주석을 참고해서 보면 된다.
개인적으로 dfs 속에 dfs를 들어가서 visit[i] = false; 이부분이 언제 실행되는건지 이해가 되질 않았다.
그래서 일일이 손으로 코드를 써보며 간신히 이해했다.
dfs 과정의 흐름의 감을 잡기 위해서는 써보는 것을 추천한다.
코드
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class boj_15649 {
static StringBuilder sb = new StringBuilder();
static int n, m;
static boolean[] visit;
static int[] arr;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
n = Integer.parseInt(st.nextToken());
m = Integer.parseInt(st.nextToken());
visit = new boolean[n];
arr = new int[m];
dfs(0);
System.out.println(sb);
}
private static void dfs(int depth) {
if (depth == m) {
for (int val : arr) {
sb.append(val).append(" ");
}
sb.append("\n");
return;
}
for (int i = 0; i < n; i++) {
// 해당 노드를 방문하지 않았다면
if (!visit[i]) {
visit[i] = true; // 해당 노드 방문상태 변경
arr[depth] = i + 1; // 해당 깊이를 index로 하여 i+1 값 저장
dfs(depth + 1);// 다음 자식 노드 방문 위해 depth 1 증가시키며 재귀 호출
visit[i] = false; // 자식노드 방문이 끝나고 돌아오면 방문노드를 방문하지 않은 상태로 변경
}
}
}
}

필사로 알고리즘 흐름도 작성하신 부분에 의견이 있어 댓글 남깁니다.
5번에서 'arr[2] = 3'라고 작성하신 부분에 대해 'arr[1] = 3'이 적절하지 않을까요? 인덱스로 depth가 들어가게 되는데 5번, 8번 모두 depth = 1의 상태에서 이루어진 과정이니까요. 또한 작성하신 대로 'arr[2] = 3'으로 한다면 arr = {1, 2, 3} 이 되어 6번에서 출력을 하게 되었을 때 두 개가 아닌 세 개의 값이 출력될 것으로 예상됩니다.