
1. 개요
Airflow란 데이터 엔지니어의 핵심 업무인 데이터 파이프라인을 구축하는데 쓰이는 핵심 도구이다.
Job Orchestration tool인 Airflow에 대해서 알아보도록 하겠다.
2. Airflow란?
Airflow는 'Job Orchestration tool'로 내가 원하는 데이터 처리 작업을 설정한 일정한 시간에 설정한 순서대로 자동화하고 과정을 관리하는 도구이다.
cronjob과 같이 개발자가 원하는 주기를 지정하고 데이터 처리 작업 과정을 구현하여 Airflow를 통해서 통합이 가능하다.
통합된 전체적인 과정은 Airflow의 웹 기반 인터페이스를 통해서 파이프라인 구조를 파악할 수 있고, 실행 상태를 확인할 수 있어 문제가 발생했을때 빠른 대응이 가능하다.
↓아래는 최근 Airflow 3 기준의 UI이다.
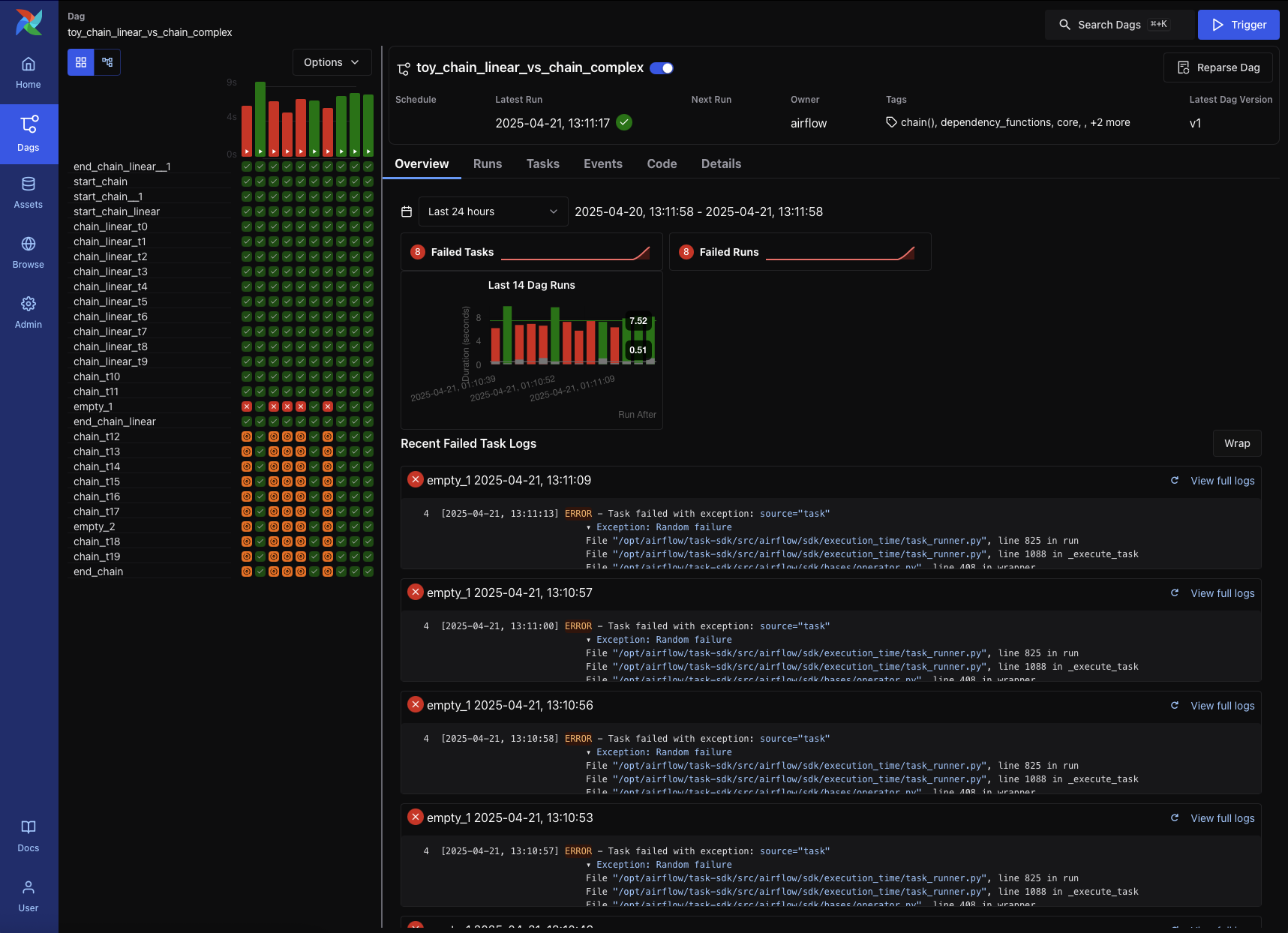
2-1. 데이터 파이프라인?
Airflow는 데이터 파이프라인 구성에 쓰이는 핵심 도구라고 서술하였다.
데이터 파이프라인이란 데이터 소스에서 원하는 목적지까지 이동하는 전체 과정을 의미한다.
파이프라인 구성은 ETL(Extract, Transform, Load), ELT 두 가지 방식이 존재한다.
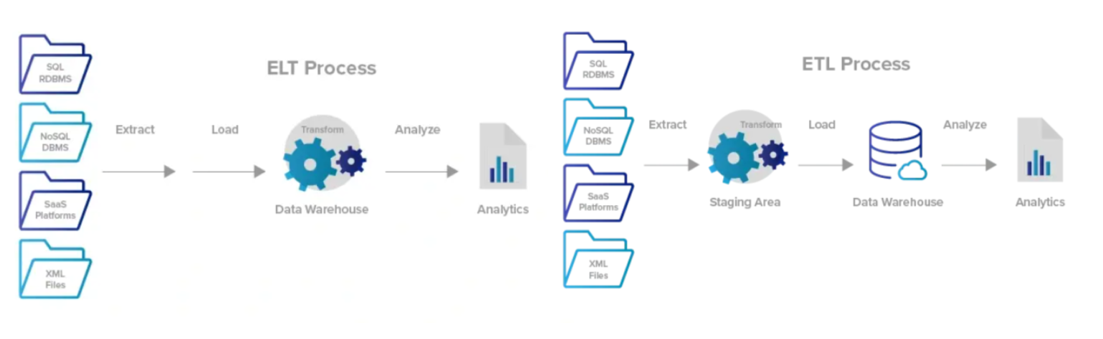
- ETL : 전통적인 데이터 파이프라인 방식으로 데이터를 추출해 원하는 형태로 변환 후 적재하는 방식이다.
- ELT : 최근 데이터의 크기가 점점 방대해짐으로 인해 DL(Data Lake) 개념이 생겼다. 과거에는 비정형/반정형 데이터를 DW(Data Warehouse)에서 처리할 수 없었지만 이제는 SnowFlake, Redshift, Google BigQuery와 같은 OLAP(Online Analytical Processing)가 등장하며 DL의 대규모 데이터를 DW로 끌고와 DW에서 SQL을 통해 변환이 가능해졌다.
2-2. 실시간 vs 배치
데이터 처리의 방식은 실시간, 배치로 나눌 수 있다.
예를 들자면, 실시간 처리는 네비게이션과 같이 사용자가 경로 이탈을 하는 경우 바로 새로운 경로를 제공하는 것과 같다.
하지만 이러한 과정은 보통 Kafka, Spark Streaming 등을 통해 이루어진다.
Airflow는 실시간이 아닌 지정된 주기에 따라 데이터 처리를 진행하는 배치 방식에 특화 되어있다.
2-3. 편의성, 확장성
Airflow는 Python 코드를 통해 파이프라인을 정의할 수 있다. 기존의 파이썬 라이브러리 사용이 가능하고, 반복문 조건문을 통한 파이프라인 정의가 가능하다.
또한, 확장성도 뛰어나다. AWS, GCP, Azure와 같은 클라우드 서비스부터 Spark, Hadoop과 같은 빅데이터 도구 그리고 MySQL, PostgreSQL, Snowflake 등 거의 모든 종류의 데이터베이스와 손쉽게 연동할 수 있는 뛰어난 확장성을 자랑한다.
실제 운영에도 웹 UI를 통한 직관적인 파이프라인 상태 확인, 실패한 테스크의 자동 재시도, 알림 설정과 같은 기능이 존재한다.
2-4. 원자성, 멱등성
Airflow를 사용할 때 가장 중요하게 생각해야하는 것은 원자성, 멱등성이다.
- 원자성 : Airflow 테스크가 성공할꺼면 전체 성공, 실패할꺼면 전체 실패
- 멱등성 : 동일한 입력으로 동일한 테스크를 여러 번 호출해도 항상 결과는 같다.
정리하자면 Airflow는 배치 처리 환경에서 원자성과 멱등성을 지키는 데이터 파이프라인의 핵심 역할을 담당한다.
3. DAG
Airflow 웹을 확인해본다면 아래와 같이 Dag들을 볼 수 있다.
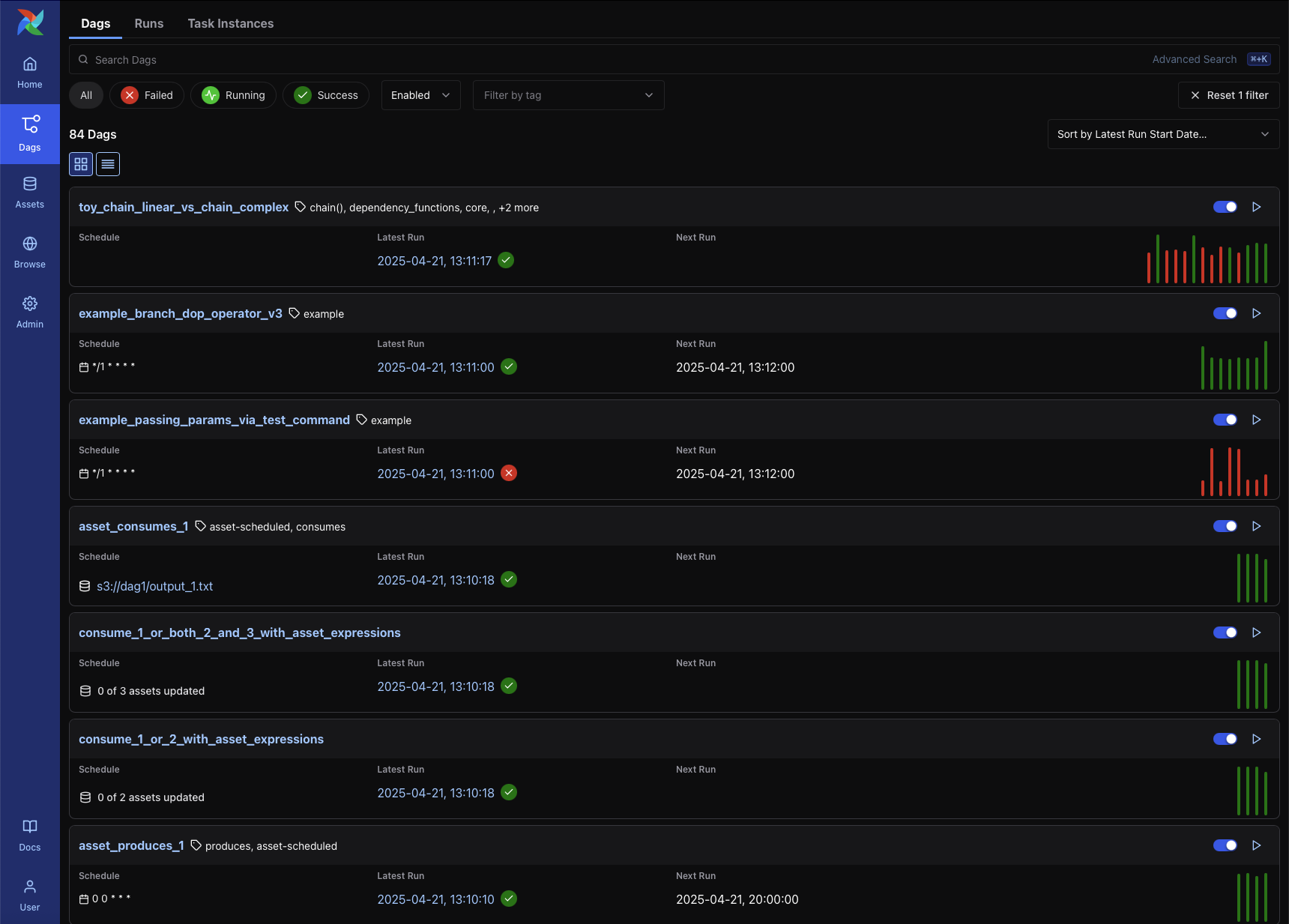
위에서 말하던 데이터 파이프라인 ETL 하나의 과정을 Dag라고 할 수 있다.
예를 들자면, 아침 루틴 Dag(기상 -> 가글 -> 아침 식사 -> 세수) 이러한 식이고 아침, 점심, 저녁 루틴이 전부 각각의 Dag로 모여 있는 것이다.
하나의 Dag 코드를 예시로 들어보겠다.
from datetime import datetime
from airflow.models.dag import DAG
from airflow.operators.python import PythonOperator
def extract_data():
'''
외부 소스 데이터 추출
'''
pass
def transform_data():
'''
추출된 데이터 변환
'''
pass
# DAG 정의
with DAG(
dag_id='ETL', # DAG 이름, 이거 겹치면 안됨
start_date=datetime(2025, 1, 1),
schedule='@daily',
tags=['example'],
) as dag:
extract = PythonOperator(
task_id='extract_data', # Task 고유 식별자
python_callable=extract_data # 실행할 파이썬 함수
)
transform = PythonOperator(
task_id='transform_data',
python_callable=transform_data
)
# 실행 순서 정의
extract >> transform이러한 식으로 하나의 DAG의 이름, 시작 날짜, 스케줄링 간격을 설정하고, 내부에 여러개의 Task로 구성된 것을 볼 수 있다.
그리고 마지막의 >> 를 통해서 Task별 실행 순서를 정할 수 있다.
병렬 실행
서로 독립적인 Task는 병렬 실행이 가능하다.
task1 >> [task2, task3] >> task4분기 실행
branch operator를 통해 결과값에 따라 원하는 분기로 실행 방향을 정할 수 있다.
branching_task = BranchPythonOperator(
task_id='branching',
python_callable=decide_which_path,
)
# decide_which_path의 return 값이 'task2' or 'task3' 중 동일한 곳으로 향함
branching_task >> [task2, task3] >> task4조건부 실행
trigger_rule을 통해 이전 task의 성공 여부로 나눌 수도 있다.
trigger_rule 종류
failure_task = BashOperator(
task_id='task3_on_failure',
bash_command='echo "task1이 실패했습니다! 에러 처리 또는 알림 작업을 수행합니다."',
# trigger_rule을 'one_failed'로 설정하는 것이 핵심입니다.
trigger_rule=TriggerRule.ONE_FAILED, # default = 'all_success'
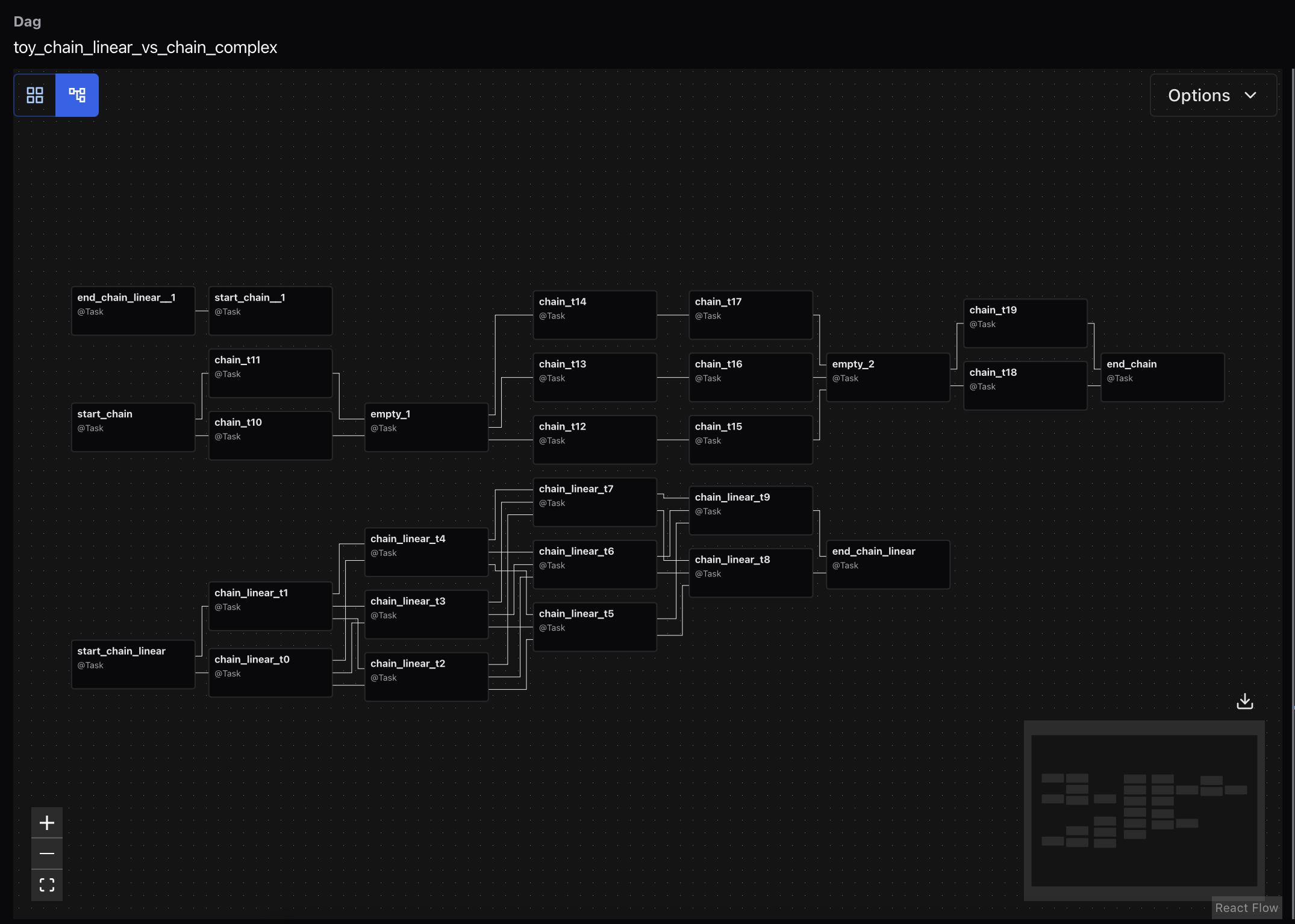
)이렇게 하나의 Dag가 구성된다면 아래와 같은 Graph를 웹에서 확인할 수 있다.
3-1. Operator
하나의 Dag에 여러개 존재하는 Task의 실제 작업을 정의하는 클래스이다.
- ⚙️ 핵심 및 일반 오퍼레이터
가장 기본적이고 범용적으로 사용되는 오퍼레이터들입니다.
| 오퍼레이터 | 설명 |
|---|---|
BashOperator | 셸 스크립트 또는 특정 셸 명령어를 실행합니다. |
PythonOperator | 정의된 Python 함수를 실행합니다. 가장 유연하게 사용할 수 있습니다. |
BranchPythonOperator | Python 함수의 결과에 따라 워크플로우를 여러 경로로 분기합니다. |
EmailOperator | 이메일을 전송합니다. (예: 작업 실패 시 알림) |
TriggerDagRunOperator | 다른 Airflow DAG의 실행을 트리거합니다. |
- 💾 데이터베이스 오퍼레이터 (Database)
다양한 데이터베이스에 연결하여 SQL 실행, 데이터 전송 등을 수행합니다.
| 오퍼레이터 | 설명 |
|---|---|
PostgresOperator | PostgreSQL 데이터베이스에 대해 SQL 쿼리를 실행합니다. |
MySqlOperator | MySQL 데이터베이스에 대해 SQL 쿼리를 실행합니다. |
SqliteOperator | SQLite 데이터베이스에 대해 SQL 쿼리를 실행합니다. |
MssqlOperator | Microsoft SQL Server에 대해 SQL 쿼리를 실행합니다. |
OracleOperator | Oracle 데이터베이스에 대해 SQL 쿼리를 실행합니다. |
GenericTransfer | 한 데이터베이스에서 다른 데이터베이스로 데이터를 복사합니다. |
- 📊 빅데이터 및 기타 서비스 오퍼레이터
다양한 데이터 처리 도구 및 SaaS(서비스형 소프트웨어)와 연동합니다.
| 오퍼레이터 | 설명 |
|---|---|
SparkSubmitOperator | Apache Spark 애플리케이션을 클러스터에 제출합니다. |
HiveOperator | Apache Hive 클러스터에 대해 HQL(HiveQL)을 실행합니다. |
DockerOperator | Docker 컨테이너를 실행합니다. |
KubernetesPodOperator | 쿠버네티스 클러스터에 지정된 이미지로 새로운 Pod를 생성하여 실행합니다. |
SnowflakeOperator | Snowflake 데이터 웨어하우스에서 SQL을 실행합니다. |
SlackAPIPostOperator | Slack 채널에 메시지를 보냅니다. |
이 외에도 수많은 커뮤니티 기반 프로바이더를 통해 거의 모든 종류의 시스템과 연동이 가능하다.
필요한 기능이 있다면 먼저 Airflow Providers 공식 문서에서 관련 오퍼레이터가 있는지 찾아보는 것이 가장 좋다.
4. 정리
대부분의 데이터 엔지니어 공고를 확인하면 Airflow는 대부분 포함되어있다.
단순히 하나의 스크립트를 실행하는 것이라면 cronjob을 통해 진행 할 수 있겠지만 복잡한 데이터 처리 과정이 필요해진다면 Airflow를 사용할 수 밖에 없다고 생각한다.
